Unleashing the Power of Coherent Motion Synthesis in Avatar Animation
- FantasyTalking introduces a novel framework that leverages a pretrained video diffusion transformer model to generate high-fidelity, coherent talking portraits with controllable motion dynamics.
- The dual-stage audio-visual alignment strategy ensures precise synchronization of lip movements and captures global body movements and dynamic backgrounds.
- The approach achieves higher quality with better realism, coherence, motion intensity, and identity preservation, outperforming existing state-of-the-art methods.

Generating an animatable avatar from a single static portrait image has long been a fundamental challenge in computer vision and graphics. The ability to synthesize a realistic talking avatar given a reference image unlocks a wide range of applications in gaming, filmmaking, and virtual reality. It is crucial that the avatar can be seamlessly controlled using audio signals, enabling intuitive and flexible manipulation of expressions, lip movements, and gestures to align with the desired content.
Early attempts to tackle this task mainly resorted to 3D intermediate representations, such as 3D Morphable Models (3DMM) or FLAME. However, these approaches typically faced challenges in accurately capturing subtle expressions and realistic motions, which significantly limited the quality of the generated portrait animations. Recent research has increasingly focused on creating talking head videos using diffusion models, which show great promise in generating visually compelling content that adheres to multi-modal conditions, such as reference images, text prompts, and audio signals. However, the realism of the generated videos remained unsatisfactory.

Existing methods typically focused on tame talking head scenarios, achieving precise audio-aligned lip movements while neglecting other related motions, such as facial expressions and body movements, both of which are essential for producing smooth and coherent portrait animations. Moreover, the background and contextual objects usually remained static throughout the animation, which made the scene less natural.
To address these limitations, we introduce FantasyTalking, a novel audio-driven portrait animation technique. By employing a dual-stage audio-visual alignment training process, our method effectively captures the relationship between audio signals and lip movements, facial expressions, as well as body motions. At the core of our work is a dual-stage audio-visual alignment strategy. In the first stage, we employ a clip-level training scheme to establish coherent global motion by aligning audio-driven dynamics across the entire scene, including the reference portrait, contextual objects, and background. In the second stage, we refine lip movements at the frame level using a lip-tracing mask, ensuring precise synchronization with audio signals.
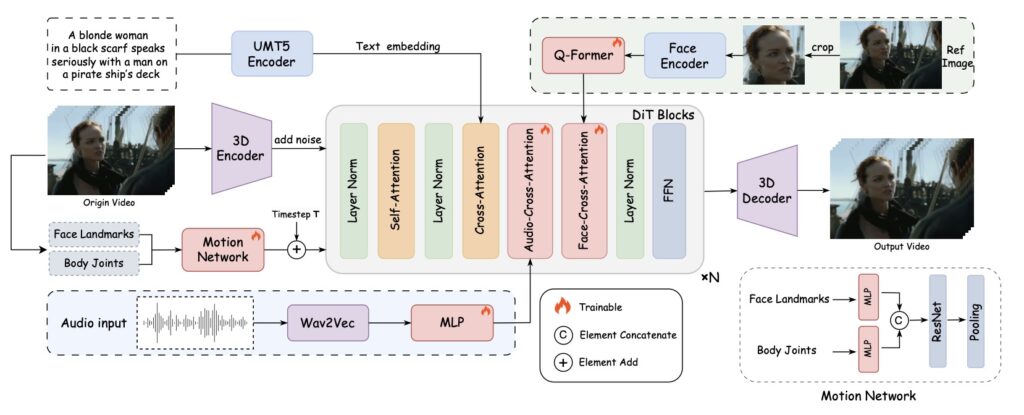
To enhance identity consistency within the generated videos, we propose a facial-focused approach to retain facial features accurately. We replace the commonly used reference network with a facial-focused cross-attention module that effectively maintains facial consistency throughout the video. Additionally, a motion intensity modulation module is integrated to explicitly control expression and body motion intensity, enabling controllable manipulation of portrait movements beyond mere lip motion.
Extensive experimental results show that our proposed approach, FantasyTalking, achieves higher quality with better realism, coherence, motion intensity, and identity preservation compared to existing state-of-the-art methods. Both qualitative and quantitative experiments demonstrate that FantasyTalking outperforms existing methods in several key aspects, including video quality, motion diversity, and identity consistency.
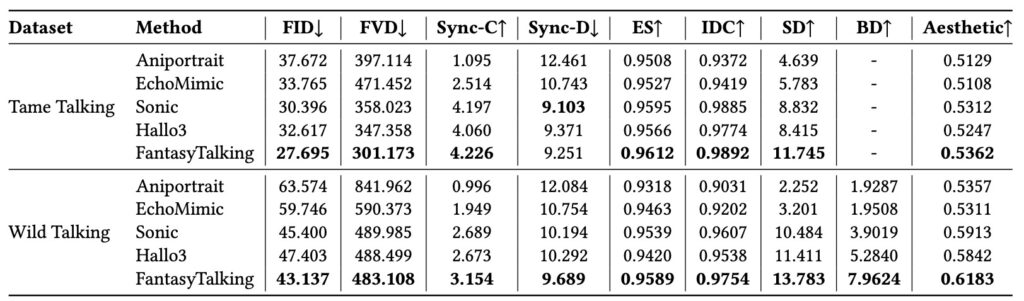
In conclusion, FantasyTalking revolutionizes the field of realistic talking portrait generation by leveraging a pretrained video diffusion transformer model and a dual-stage audio-visual alignment strategy. By capturing the relationship between audio signals and various motions, including lip movements, facial expressions, and body movements, while maintaining identity consistency and enabling controllable manipulation, FantasyTalking opens up new possibilities for creating engaging and lifelike animatable avatars from single static portraits.
