Mastering the balance between creative transformation and background stability through Region-Constraint In-Context Generation.
- Solving the Stability Crisis: ReCo addresses the critical flaw in AI video editing where modifying a specific subject accidentally warps or corrupts the surrounding non-editing regions.
- Dual-Regularization Technology: By utilizing novel “Latent” and “Attention” regularization terms, the model learns to strictly separate the foreground edits from the background context during the denoising process.
- Massive Scale Training: The introduction of “ReCo-Data,” a massive dataset comprising 500,000 instruction-video pairs, sets a new benchmark for high-quality, data-efficient model training.
The landscape of artificial intelligence is currently witnessing a rapid evolution in “in-context generation.” This paradigm has already demonstrated immense power in the realm of static image editing, offering both high-quality synthesis and impressive data efficiency. However, translating this success from still images to moving video is far from trivial.
The primary hurdle has been control. In traditional instruction-based video editing, models often struggle to distinguish where an edit should end and where the original video should remain untouched. Without specified editing regions, results frequently suffer from inaccurate changes. Worse yet, “token interference” occurs, where the digital noise from the editing area bleeds into the non-editing area, causing the background to warp or hallucinate unexpected content. To solve this, researchers at HiDream.ai have introduced a groundbreaking solution: ReCo (Region-Constraint In-Context Generation).
Introducing ReCo: A New Paradigm
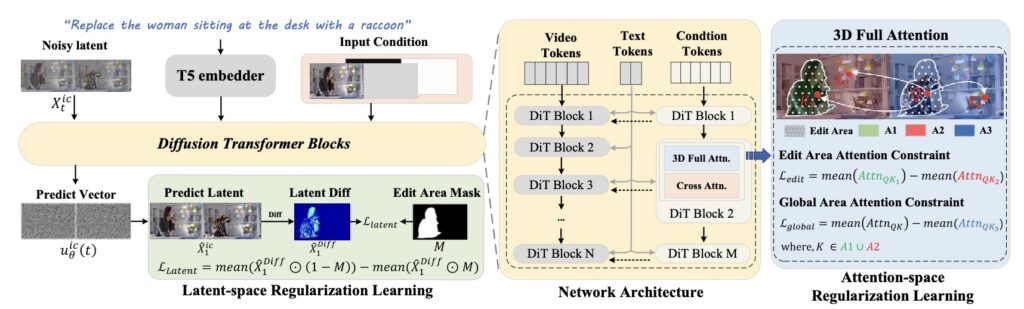
ReCo represents a shift in how AI approaches video diffusion. Rather than treating the video as a single, messy canvas, ReCo delves into constraint modeling. It explicitly defines the relationship between “editing regions” (the subject you want to change) and “non-editing regions” (the background you want to keep).
From a technical standpoint, ReCo employs a unique method called width-wise concatenation. It takes the source video and the target video and processes them together during joint denoising. This allows the model to constantly compare the original footage with the desired outcome based on natural language instructions.
The Mechanics of Precision: Two Key Regularizations
To ensure the AI doesn’t color outside the lines, ReCo capitalizes on two sophisticated regularization terms applied to one-step backward denoised latents and attention maps.
1. Latent Regularization: Protecting the Background
The first mechanism operates in the latent space. Its goal is to manage the “discrepancy” or difference between the source and target videos.
- For Non-Editing Areas: The model strives to decrease discrepancy. It forces the background of the new video to mathematically resemble the source video, alleviating the generation of unexpected content in areas that should remain static.
- For Editing Areas: Conversely, it increases the discrepancy. This emphasizes the modification, ensuring the AI commits fully to the requested change (e.g., changing a car from red to blue).
2. Attention Regularization: Focusing the Lens
The second mechanism addresses “token interference.” In standard models, the AI might look at the original object in the source video and get confused when trying to generate a novel object in the target video. ReCo suppresses the attention of tokens in the editing region toward their counterparts in the source video. By severing this distraction, the model can generate new objects—like turning a dog into a cat—without the “ghost” of the original object interfering with the synthesis.

Powering the Future with ReCo-Data
An AI model is only as good as the data it learns from. Recognizing a gap in available resources, the team constructed ReCo-Data. This is a large-scale, high-quality video editing dataset comprising 500,000 instruction-video pairs.
This massive dataset covers a wide range of editing tasks, providing the robust foundation necessary for the model to understand complex instructions and varied video contexts.
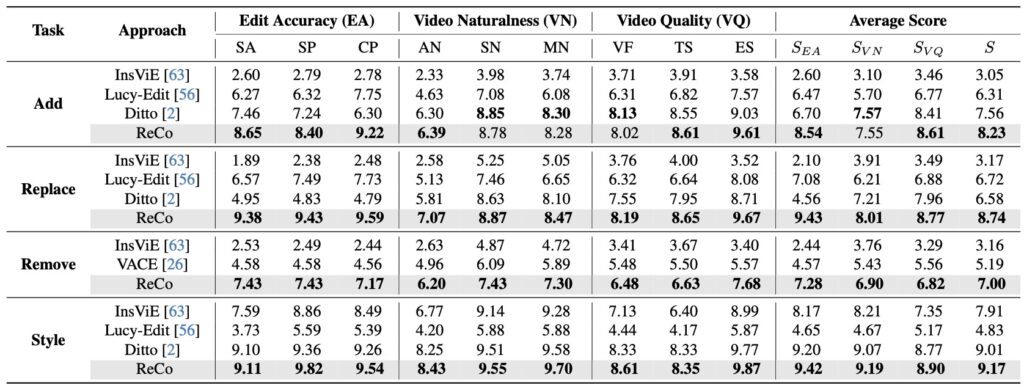
Extensive experiments conducted across four major instruction-based video editing tasks have demonstrated the superiority of the ReCo proposal. By successfully integrating regional constraint modeling into diffusion training, ReCo has solved the persistent problem of background instability. It ensures that when a user asks to edit a video, the AI changes exactly what was asked for—and nothing else.
