The “Inference-Only” Myth is Dead—Long Live the Open NPU
- The Hidden Powerhouse: A research breakthrough has successfully reverse-engineered Apple’s proprietary Neural Engine (ANE) on the M4 chip, enabling backpropagation and neural network training on hardware Apple intended to be “inference-only.”
- Efficiency Reimagined: Benchmarks reveal the M4 ANE achieves a staggering 6.6 TFLOPS/W, making it roughly 80 times more power-efficient than an NVIDIA A100 for specific AI tasks.
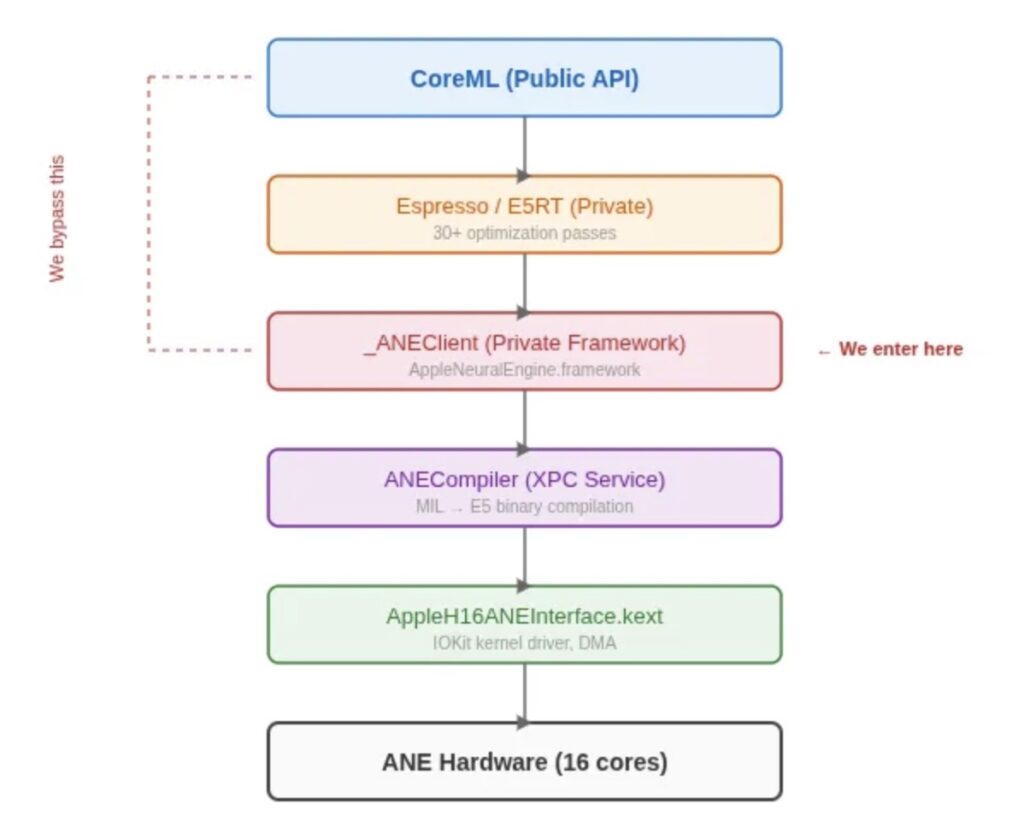
- Direct Access Achieved: By bypassing the restrictive CoreML and Metal frameworks, researchers tapped into private APIs (_ANEClient and _ANECompiler) to run custom compute graphs directly on the silicon.
For years, the Apple Neural Engine (ANE) has been the “black box” of Apple Silicon. Tucked away inside your Mac mini, MacBook, and iPad, this specialized hardware was designed for one thing: running AI models (inference) with extreme efficiency. Apple never provided public APIs, documentation, or any way to use it for training. It was a closed circuit—until now.
A new research project, conducted as a “weekend hack” by a developer named Maderix in collaboration with Claude 4.6, has effectively cracked the ANE open. By reverse-engineering the private frameworks that macOS uses internally, they have successfully trained a transformer model directly on the M4’s Neural Engine. This isn’t just a technical curiosity; it represents a fundamental shift in how we view consumer hardware for local AI development.
Beyond the Marketing: 38 TOPS vs. Reality
Apple’s marketing for the M4 chip proudly touts “38 TOPS” (Trillions of Operations Per Second). However, the reality under the hood is more nuanced. Through direct benchmarking—bypassing the overhead of the CoreML abstraction layer—the researchers found that the real-world throughput for FP16 (half-precision floating point) is closer to 19 TFLOPS.
While that might seem like a “downgrade” from the marketing slides, the efficiency tells a different story. When compared to the industry-standard NVIDIA A100, the M4 ANE delivers 6.6 TFLOPS per watt, whereas the A100 manages only 0.08. This means your Mac is performing AI tasks with a fraction of the power, opening the door for complex local AI that doesn’t drain your battery or turn your desk into a space heater.
How the Breach Was Made
The researchers didn’t use standard tools like Metal or MLX. Instead, they performed a “deep dive” into the macOS software stack using dyld_info to discover over 40 private classes within the AppleNeuralEngine.framework.
The Stack from Top to Bottom
| Layer | Component | Description |
| Public API | CoreML | The user-facing, high-level framework (Limited). |
| Private Bridge | _ANEClient | The discovered gateway for direct ANE access. |
| Compiler | _ANECompiler | Converts Model Intermediate Language (MIL) to ANE binary. |
| Kernel Driver | IOKit / H16G | The low-level driver communicating with the physical M4 silicon. |
By targeting the _ANEClient and _ANECompiler directly, the team was able to submit raw Model Intermediate Language (MIL) code—a typed representation of neural networks—directly to the hardware. They discovered that the ANE supports a queue depth of 127 evaluation requests, suggesting it is a high-throughput streaming engine far more capable than Apple’s public documentation suggests.
Training on an “Inference” Chip
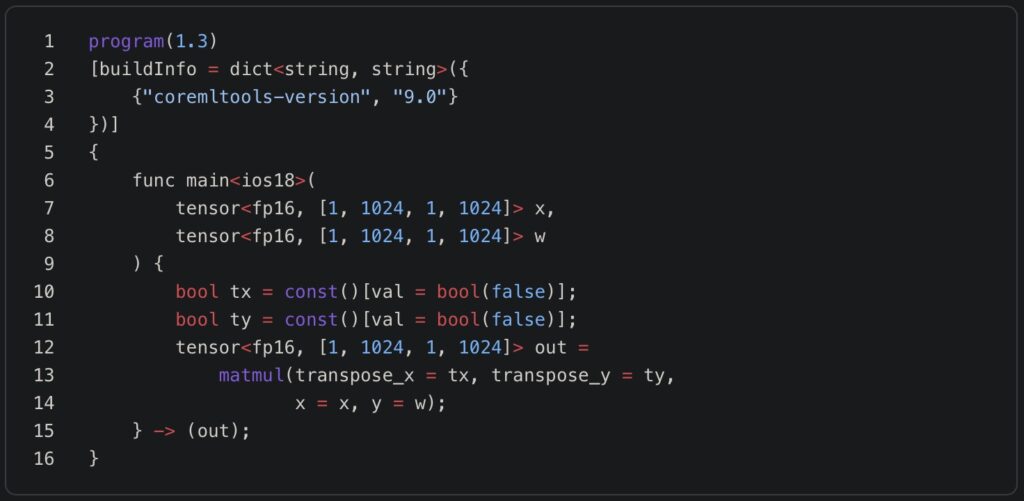
The most groundbreaking achievement of this project is Backpropagation on ANE. The researchers implemented a from-scratch transformer layer (dimension 768, sequence length 512) that performs both forward and backward passes on the Neural Engine.
Key technical hurdles were cleared through clever optimization:
- Channel-First Layout: Matching the ANE’s native
[1, C, 1, S]format to eliminate data transposition overhead. - Hybrid Compute: While the ANE handles the heavy lifting of the forward and backward passes, the CPU (using Apple’s Accelerate framework) handles the Adam optimizer updates and residual connections.
- RMSNorm Fusion: Folding normalization layers directly into the ANE kernels to prevent the data from ever having to leave the high-speed SRAM of the Neural Engine.
Why This Matters for the Future
This is still early-stage research. Currently, utilization of the ANE during training sits around 11.2%, and many smaller operations still “fall back” to the CPU. However, the door is now open.
The significance lies in the democratization of AI hardware. Most Mac users have a world-class AI accelerator sitting idle in their machines for 99% of the day. This research proves that with the right software “keys,” these machines can become powerful nodes for training small-to-medium research models locally, privately, and with unprecedented energy efficiency.
The project is released under the MIT license, encouraging the community to fork the code and build upon these findings. As we move into an era where “Edge AI” becomes the norm, the ability to train on the silicon we already own is no longer a dream—it’s a benchmark.