Moving beyond deeper reasoning to embrace the power of parallel multi-agent collaboration.
- The Shift to Width: While AI has traditionally focused on “depth” (longer reasoning chains), WIDESEEK-R1 introduces “width scaling” to handle tasks that require broad information gathering.
- Organizational Intelligence: By using Multi-Agent Reinforcement Learning (MARL), the system moves from individual agent competence to a coordinated “lead-subagent” organizational structure.
- Efficiency at Scale: A compact 4B model using width scaling can match the performance of a massive 671B single-agent model, proving that more heads are often better than one giant brain.
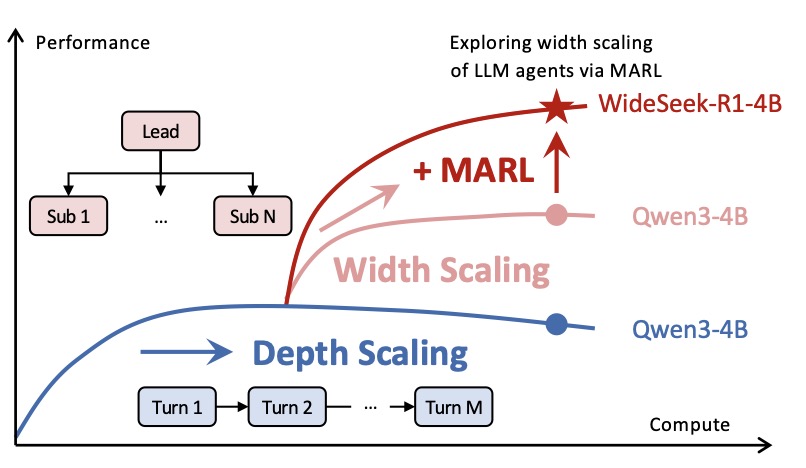
For the past few years, the race in Large Language Models (LLMs) has been vertical. We have focused intensely on depth scaling—building single agents capable of complex, multi-turn reasoning to solve “long-horizon” problems. However, as our digital tasks become increasingly broad, a new bottleneck has emerged. It is no longer just about how deeply an agent can think, but how much ground it can cover at once.
When a task requires searching across dozens of different domains or verifying hundreds of data points, a single agent—no matter how powerful—becomes a bottleneck. This is where the concept of width scaling comes in, shifting the focus from individual brilliance to organizational efficiency.
The Architecture of WIDESEEK-R1
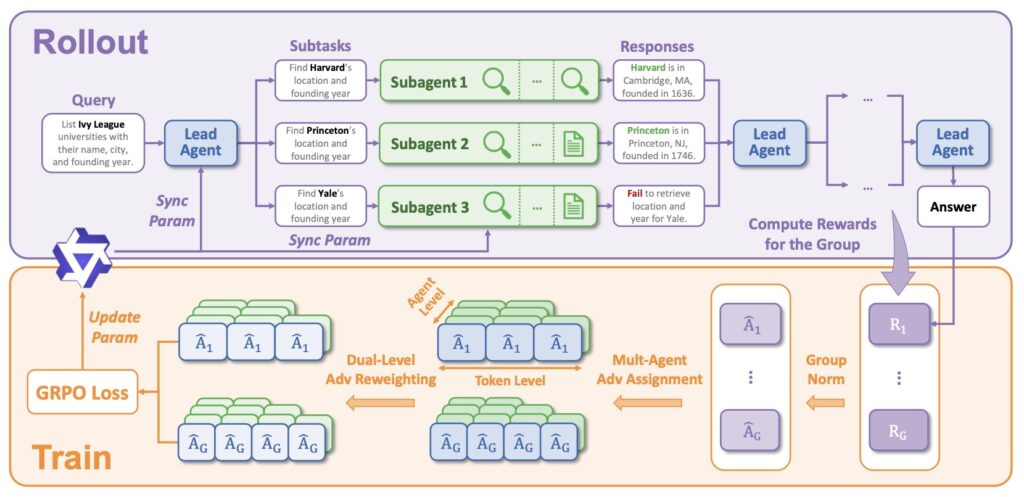
Enter WIDESEEK-R1, a framework designed to bridge the gap between simple tool-use and true parallel execution. Unlike traditional multi-agent systems that rely on rigid, hand-crafted workflows or slow “turn-taking” interactions, WIDESEEK-R1 utilizes a dynamic lead-agent and subagent structure.
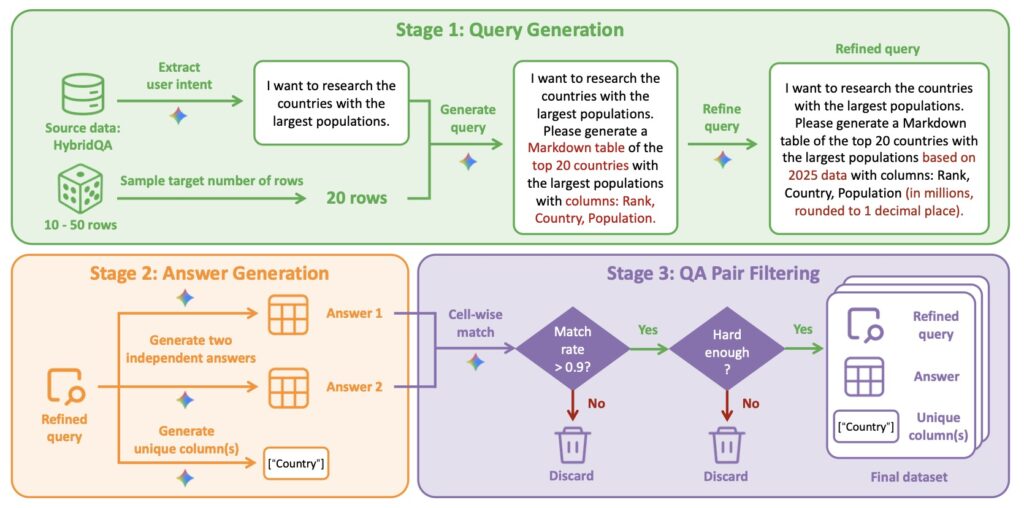
The system operates on a shared LLM backbone but maintains isolated contexts for its subagents. This allows a lead agent to act as an orchestrator, delegating specific portions of a broad query to specialized subagents who work in parallel. This coordination isn’t just programmed; it is earned. WIDESEEK-R1 is trained via Multi-Agent Reinforcement Learning (MARL), optimizing how the “manager” and the “workers” synergize to find information effectively.
Proven Performance: Small Models, Big Results
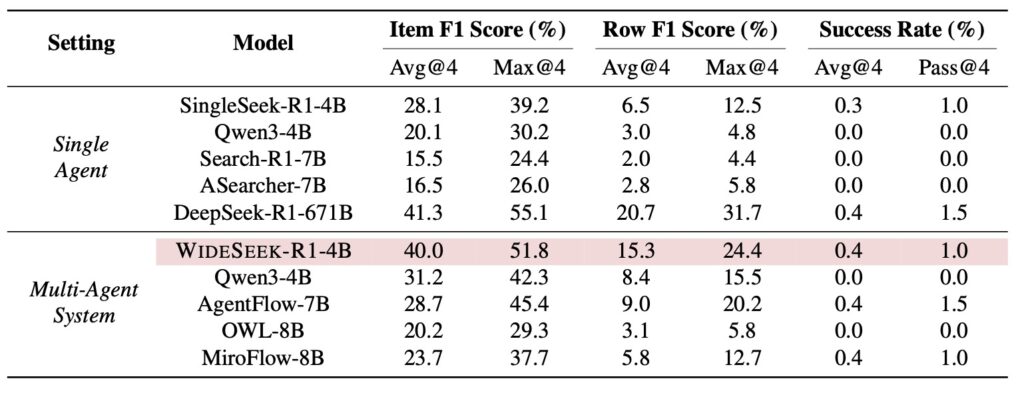
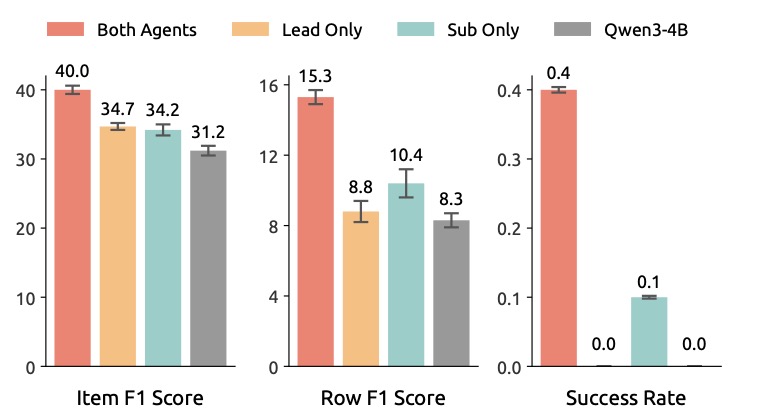
The results of this approach are nothing short of disruptive. In experiments using the WideSearch benchmark, the WIDESEEK-R1-4B model (a relatively small 4-billion parameter model) achieved an item F1 score of 40.0%.
To put that in perspective, this performance is comparable to the DeepSeek-R1-671B, a model more than 150 times its size. This suggests that for broad information-seeking tasks, the “width” of an organization can compensate for the “depth” of a single massive controller.
Key Finding: While depth scaling eventually faces diminishing returns, width scaling shows consistent performance gains. As you add more parallel subagents to WIDESEEK-R1, the system’s ability to solve complex problems continues to scale upward.
The Future of AI Organizations
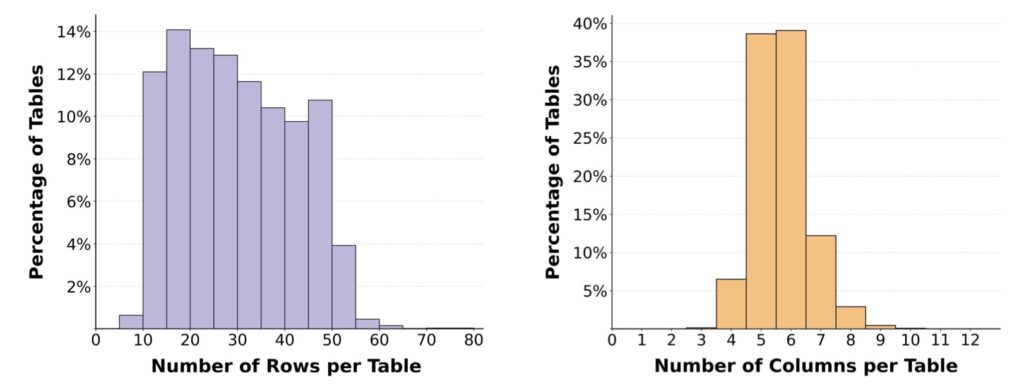
By releasing a curated dataset of 20,000 broad information-seeking tasks, the creators of WIDESEEK-R1 are laying the groundwork for a new era of AI research. We are moving away from the “lone genius” model of AI and toward a future of “efficient digital departments.”
This shift suggests that the next leap in AI productivity won’t just come from making models bigger, but from making them better at working together. WIDESEEK-R1 proves that when we stop asking an AI to do everything itself and start teaching it to lead, the ceiling for what is possible rises significantly.