Exploring a Lightweight Approach to Bridging Visual and Audio Generation
- Unified Transformer Model: Visual Echoes uses a simple generative transformer for both audio-visual generation and cross-modal tasks.
- Efficiency and Performance: The model surpasses recent image-to-audio methods despite its simplicity.
- Future Improvements: Addressing limitations in image quality and expanding capabilities to video data are key future directions.
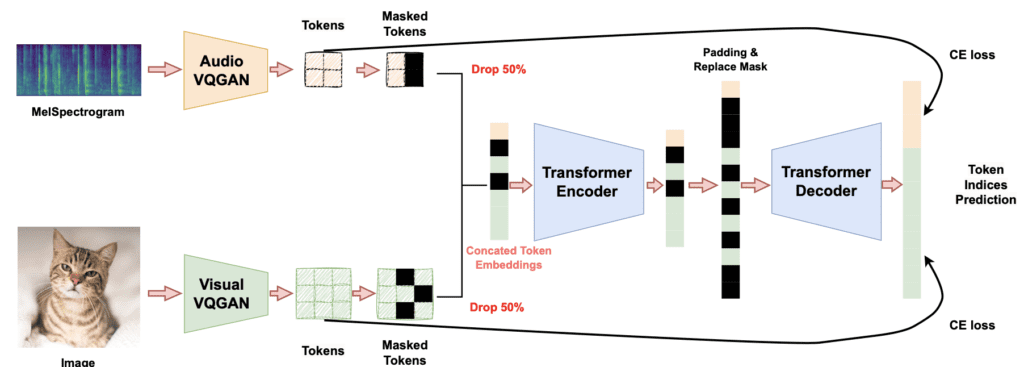
In the rapidly evolving field of generative models, significant strides have been made in text-to-image and text-to-audio generation. However, advancements in audio-to-visual and visual-to-audio generation have lagged behind. Addressing this gap, Sony introduces Visual Echoes, a simple yet effective unified transformer model for audio-visual generation. This model aims to achieve excellent results without the complexity of larger models, making it a noteworthy development in the realm of multi-modal generation.
Unified Transformer Model
Visual Echoes sets itself apart by utilizing a lightweight generative transformer to handle audio-visual tasks. Unlike existing methods that rely on large language models or composable diffusion models, Visual Echoes operates within the discrete audio and visual Vector-Quantized GAN (VQGAN) space. It is trained using a mask denoising technique, which enhances its ability to generate coherent outputs in both audio and visual domains.
The model’s versatility is one of its standout features. After training, it can be applied to various tasks such as image-to-audio, audio-to-image, and co-generation without requiring additional training or modifications. This makes Visual Echoes a robust and flexible tool for researchers and developers working on audio-visual integration.
Efficiency and Performance
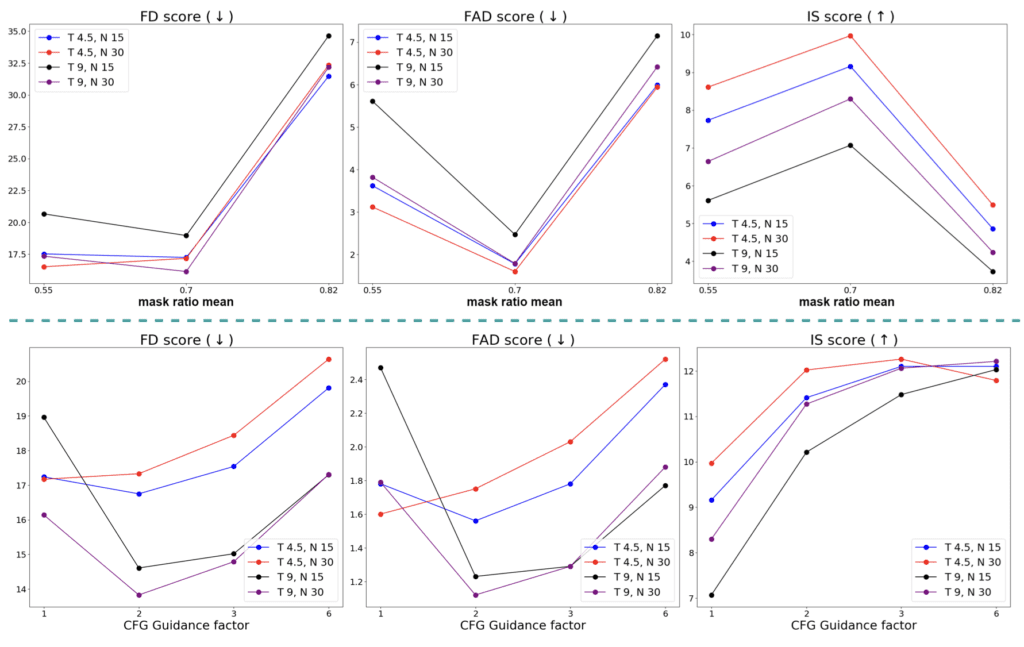
Despite its simplicity, Visual Echoes has demonstrated superior performance compared to recent image-to-audio generation methods. By employing classifier-free guidance, the model can improve its performance off-the-shelf. This approach not only simplifies the generation process but also ensures that the model remains efficient and easy to deploy across different tasks.
The experimental results highlight the model’s capability to surpass more complex systems, showcasing its potential as a strong baseline for future audio-visual generation research. However, the researchers acknowledge some limitations, particularly in image generation quality and the model’s ability to generalize across different datasets.

Future Improvements
While Visual Echoes represents a significant advancement in the field, there are areas where further development is needed. One major limitation is the model’s image generation quality, which is attributed to the generalization and reconstruction abilities of the ImageNet pre-trained VQGAN on the VGGSound dataset. Additionally, the current model cannot handle video data, which limits its applicability in scenarios requiring dynamic visual content.
Another area for improvement is the fine-grained visual control in audio generation, which remains unexplored in both Visual Echoes and existing methods. Addressing these issues will be crucial for enhancing the model’s real-world applicability and performance.
Moreover, the VGGSound dataset, used for training, contains videos that are completely or partially black, leading to the generation of black images by the model in some cases. Cleaning and refining the dataset could mitigate this issue and improve the model’s output quality.
Sony’s Visual Echoes marks a significant step forward in the field of audio-visual generation. By adopting a simple and unified transformer approach, it achieves remarkable performance while maintaining efficiency and adaptability. While there are areas for improvement, particularly in image quality and video processing, Visual Echoes provides a strong foundation for future research and development in multi-modal generation. As researchers continue to refine and expand upon this model, it promises to unlock new possibilities for integrating visual and audio data in innovative ways.