Revolutionizing video generation by solving the “first-frame” problem and harmonizing motion with identity.
- Paradigm Shift: SteadyDancer moves away from the flawed Reference-to-Video (R2V) model to an Image-to-Video (I2V) approach, ensuring the generated video actually looks like the original image from the very first frame.
- Technical Innovation: The framework utilizes a unique Condition-Reconciliation Mechanism and Synergistic Pose Modulation to balance strict motion control with high visual fidelity, eliminating common glitches like “identity drift.”
- Efficiency & Quality: Through a Staged Decoupled-Objective Training Pipeline, SteadyDancer achieves state-of-the-art performance in visual quality and motion accuracy while using significantly fewer computing resources than competitors.
Human image animation—the art of turning a single static photo into a moving video controlled by specific poses—is rapidly becoming a cornerstone of modern digital media. From film production and visual effects (VFX) to advertising and video game development, the ability to animate static characters has immense potential. While diffusion models have recently unlocked exciting new capabilities in high-fidelity video generation, a persistent problem has plagued the industry: keeping the character looking like themselves while making them move naturally. Enter SteadyDancer, a groundbreaking framework designed to harmonize motion and identity with unprecedented precision.

The Problem with Current Methods
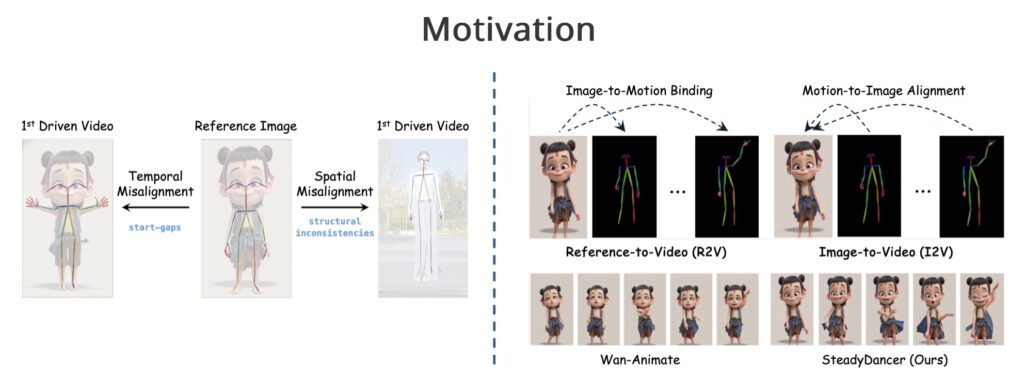
To understand why SteadyDancer is necessary, we must first look at the limitations of the dominant approach, known as the Reference-to-Video (R2V) paradigm. In the R2V model, the system attempts to “bind” a reference image onto a driving pose sequence. While this sounds logical, it often fails in real-world applications due to critical spatio-temporal misalignments.
Imagine trying to animate a photo of a person standing still, but the driving pose sequence starts with a jump. In the R2V paradigm, the system forces the image to instantly snap to that jumping pose. This results in an abrupt, unnatural jump that lacks a smooth transition. Furthermore, discrepancies in limb structure or movement amplitude often lead to “identity drift” (where the person stops looking like the original photo) and severe visual artifacts. For high-stakes applications like VFX or keyframe animation, where visual fidelity is paramount, these distortions are unacceptable.
The SteadyDancer Solution: An I2V Approach
SteadyDancer addresses these failures by adopting an Image-to-Video (I2V) paradigm. Unlike R2V, which relaxes alignment constraints, the I2V approach inherently guarantees first-frame preservation. This means the animation respects the initial state of the reference image, generating a consistent and coherent video that flows naturally from the start.
However, I2V is technically challenging because it demands strict adherence to the initial frame. The pose data must be carefully modulated to act as a control signal that aligns perfectly with the reference image. To solve this, SteadyDancer introduces a suite of novel technical innovations:
- Condition-Reconciliation Mechanism: This feature harmonizes conflicting conditions—specifically, the need to keep the image looking like the original photo while simultaneously forcing it to move. It enables precise motion control without sacrificing visual fidelity.
- Synergistic Pose Modulation Modules: These modules generate an adaptive pose representation that is highly compatible with the reference image, ensuring that the movement doesn’t break the visual logic of the character’s body.
- Staged Decoupled-Objective Training Pipeline: This hierarchical optimization strategy trains the model in stages, focusing separately on motion fidelity, visual quality, and temporal coherence.
Superior Performance with Less Waste
One of the most impressive aspects of SteadyDancer is its efficiency. By using the Staged Decoupled-Objective Training pipeline, the framework optimizes the model for continuity and quality while requiring significantly fewer training resources than comparable methods.
Experiments, particularly on the X-Dance benchmark, demonstrate that SteadyDancer achieves state-of-the-art performance. It excels in both appearance fidelity (keeping the person looking real) and motion control (making the movement accurate). By resolving the core challenges of harmonizing fidelity with motion, SteadyDancer provides a robust, efficient solution for the future of human animation, paving the way for more realistic and coherent digital storytelling.