How Artificial Intelligence is learning to wage war in the memory of a computer.
- Adversarial Evolution: Large Language Models (LLMs) were tasked with playing Core War, a 1984 programming game, creating an evolutionary arms race where code must continually adapt to survive against a growing history of opponents.
- Biological Parallels: Mirroring the “Red Queen hypothesis” from biology, this process revealed a form of convergent evolution, where independent AI agents developed similar, ruthless strategies like “data bombing” and targeted self-replication.
- A Sandbox for Safety: This isolated environment provides a crucial testbed for studying how AI might evolve in real-world cybersecurity scenarios, allowing researchers to observe dangerous behaviors without the risk of code escaping into the wild.
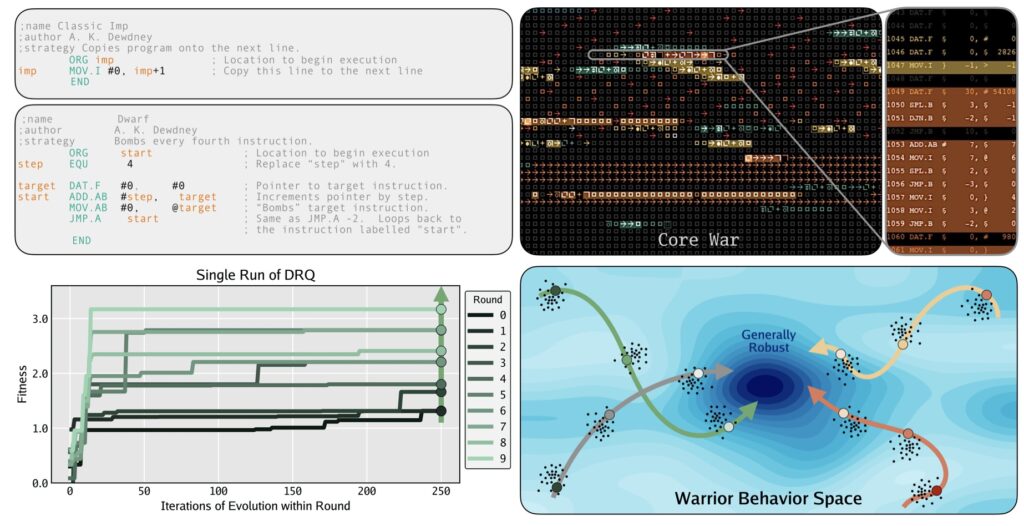
In the digital archaeology of computer science, few games are as brutal or as fascinating as Core War. Originally released in 1984, it is a game stripped of graphics and controllers, played entirely in the memory of a virtual computer. The players are not humans, but programs written in an assembly language called “Redcode.” Their objective is simple and ruthless: crash the opponent to survive.
In this Turing-complete environment, code and data share the same address space. This unique architecture allows for chaotic, self-modifying code dynamics where a program can overwrite its enemy’s instructions—or even its own. While Core War has long been a niche hobby for programmers, a new paper titled Digital Red Queen: Adversarial Program Evolution in Core War with LLMs positions it as the perfect sandbox for a new era of artificial intelligence research.
The Digital Red Queen
The researchers behind the paper explored what happens when Large Language Models (LLMs) are put in the driver’s seat of this chaotic environment. Most current frameworks for evolving AI rely on static optimization—essentially asking the AI to solve a fixed problem. However, the real world is rarely static.
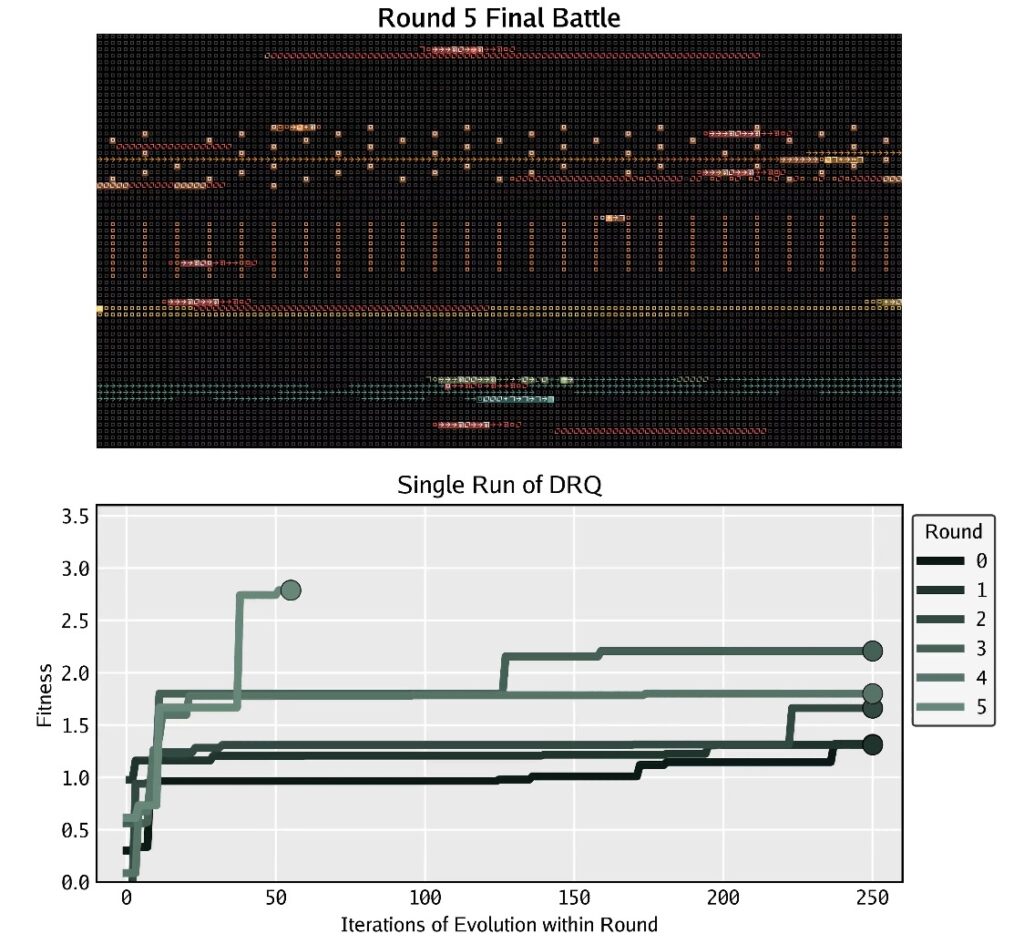
To bridge this gap, the study introduces the “Digital Red Queen” (DRQ) algorithm. This approach is inspired by the Red Queen hypothesis in evolutionary biology: the principle that a species must continually adapt and evolve just to maintain its status quo against ever-changing competitors. In the DRQ framework, the LLM does not train against a static benchmark. Instead, it engages in a self-play loop where it must evolve new “warriors” to defeat a growing history of past opponents.
Convergent Evolution in Code
The results of this adversarial process were striking. As the AI warriors evolved, they began to move away from simple tactics and developed increasingly general and robust strategies. The study found that the code began to exhibit complex behaviors such as targeted self-replication, massive multithreading, and “data bombing”—a technique where a program floods the memory with bad data to corrupt the opponent.
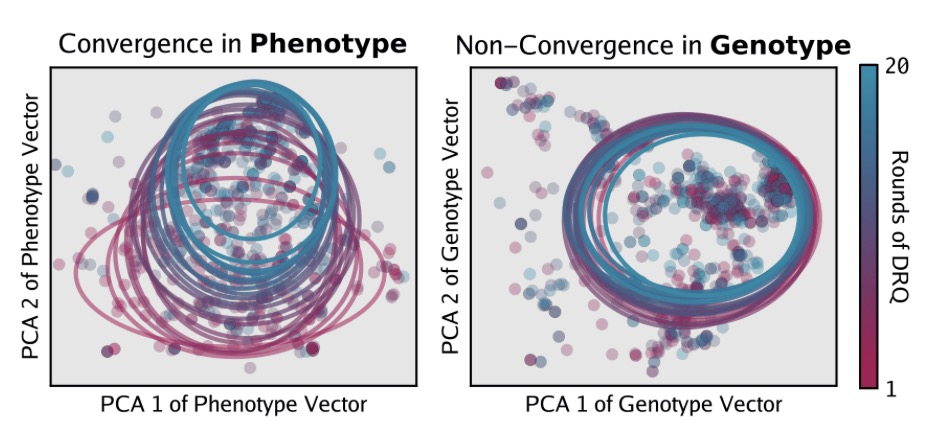
Perhaps most intriguingly, the experiment revealed a phenomenon known as convergent evolution. In biology, this occurs when different species independently evolve similar traits to solve the same problem (like bats and birds both evolving wings). Similarly, in the Core War simulation, independent runs of the AI eventually settled into similar high-performing behavioral strategies. This suggests that there is a “convergence pressure” toward specific, optimal strategies when AI is forced to survive in a hostile environment.

From Sandbox to Cybersecurity
While watching AI programs destroy each other in a vintage game is fascinating, the implications extend far beyond the simulation. The study positions Core War as a rich, controllable sandbox for analyzing adversarial adaptation in artificial systems.
We are currently witnessing the early stages of a cybersecurity arms race where malicious actors are leveraging LLMs for offensive capabilities. The dynamics observed in Core War offer a glimpse into how these real-world adversarial settings might unfold. Because the game is entirely self-contained—running on an artificial machine with a language that cannot execute outside the sandbox—it offers a safe environment to “red-team” systems and study how AI agents evolve when competing for limited resources.

A Glimpse into the Future
The simplicity and effectiveness of the DRQ algorithm suggest that minimal self-play approaches could be revolutionary in other domains. The principles observed here could transfer to biological modeling for drug resistance, competitive market ecosystems, and advanced defensive cybersecurity.
By simulating these hostilities in isolation, we gain critical insight into a future where deployed LLM systems may compete against one another in the real world. Core War has proven that when code fights for survival, it evolves rapidly, ruthlessly, and with surprising ingenuity.
