Dynamic Frame Avatar Framework for Enhanced Video Generation
In the rapidly evolving field of artificial intelligence and video production, the ability to create realistic talking head videos from a single portrait and accompanying audio is becoming increasingly significant. Enter DAWN (Dynamic Frame Avatar with Non-autoregressive Diffusion), a groundbreaking framework designed to tackle the challenges of traditional talking head generation methods.
- Non-Autoregressive Advantage: DAWN utilizes a non-autoregressive approach to generate entire video sequences at once, overcoming the limitations of slower, autoregressive methods that suffer from context limitations and error accumulation.
- Holistic Motion Generation: The framework combines audio-driven holistic facial dynamics with precise control over head poses and eye blinks, ensuring that the generated videos are not only visually realistic but also synchronized with speech.
- Significant Performance Gains: With enhanced generation speed and strong extrapolation capabilities, DAWN opens new avenues for applications in virtual meetings, gaming, and film production, setting a new standard for the quality of generated talking head videos.

Talking head video generation has garnered considerable interest due to its potential applications in diverse fields such as virtual meetings, gaming, and film production. The primary objective is to synthesize a lifelike talking head that closely matches the accompanying speech audio, maintaining not just lip sync but also realistic coordination of head poses and eye movements. However, many existing methods rely heavily on autoregressive strategies, which generate one frame at a time. This approach leads to significant limitations, including slower generation speeds, the risk of error accumulation, and limited context utilization beyond the current frame.
Introducing DAWN: A Game Changer in Video Generation
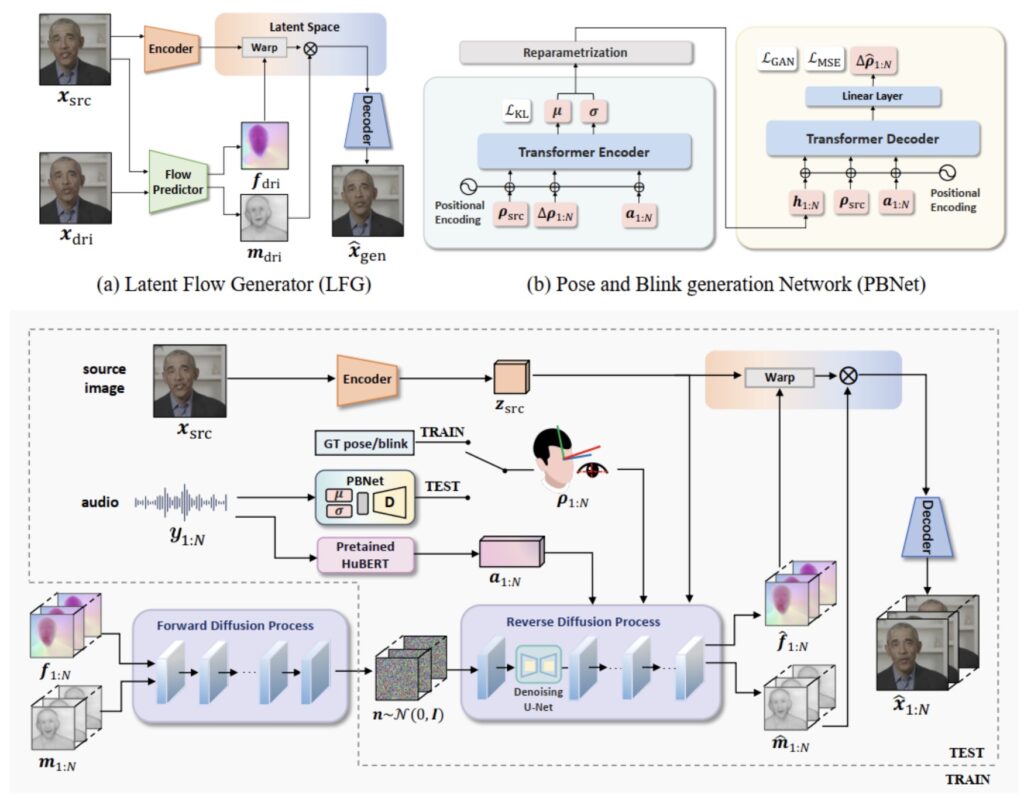
To overcome the drawbacks of traditional autoregressive methods, DAWN introduces a non-autoregressive framework that can generate dynamic-length video sequences in a single pass. This innovative architecture leverages two main components: the first focuses on audio-driven holistic facial dynamics generation in a latent motion space, while the second component generates head poses and blink movements synchronized with speech. By employing this dual strategy, DAWN ensures that every aspect of the generated video is cohesive and realistic, resulting in a more engaging viewing experience.
Technical Innovations and High-Quality Output
DAWN employs several technical innovations to achieve its high-quality output. The framework utilizes a sophisticated model called PBNet to generate natural head poses and eye blinks from the audio, while a complementary model, A2V-LDM, produces motion representations conditioned on both audio cues and the generated head movements. The final step involves decoding these motion representations into videos using a latent frame generator (LFG), which facilitates the seamless transition from audio and motion data to vivid video output.
Extensive experiments conducted on two distinct datasets demonstrate DAWN’s superiority in generating extended talking head videos. The framework consistently produces high-quality dynamic frames in a single pass, achieving not only realistic visual effects but also accurate lip synchronization and enhanced extrapolation capabilities. This allows DAWN to generate long video sequences that maintain coherence and detail throughout.
A New Era for Applications in Media and Entertainment
The implications of DAWN extend beyond mere technical achievements; they signal a transformative shift in how talking head videos can be created and utilized. The framework’s rapid generation capabilities and realistic output open doors for applications in various domains, including personalized content creation, virtual assistants, and interactive gaming. As the demand for engaging video content continues to grow, DAWN positions itself at the forefront of this evolution.
The Future of Video Generation
DAWN represents a significant advancement in the field of talking head video generation, addressing the limitations of traditional autoregressive methods and setting a new standard for quality and efficiency. By combining innovative audio-driven dynamics with non-autoregressive video generation, this framework paves the way for more nuanced and engaging content creation. As we look ahead, DAWN not only enhances our ability to produce realistic talking head videos but also sparks further exploration into the potential of non-autoregressive approaches in the broader landscape of media generation. The future of video content is here, and DAWN is leading the charge.