How Training-Free GRPO achieves state-of-the-art agentic performance by replacing expensive reinforcement learning with smart memory.
- Cost & Complexity Slashed: Traditional Agentic RL relies on expensive parameter updates; the new approach creates a paradigm shift by costing a fraction of the price (around $18) and requiring absolutely no weight changes.
- Context Over Parameters: By shifting optimization from the parameter space to the context space, the model learns “experiential knowledge” as a token prior, effectively treating memory as a policy optimizer.
- Micro-Data Efficiency: With just a few dozen samples, this method outperforms fine-tuned small LLMs, solving the data scarcity issue in specialized domains without the risk of overfitting.
Large Language Models (LLMs) have undeniably changed the technological landscape, emerging as powerful general-purpose agents capable of solving complex problems, writing code, and reasoning through abstract concepts. However, there is a “last mile” problem. While these models are brilliant generalists, they often stumble when deployed in specialized, real-world domains—such as advanced mathematical reasoning or complex web research—that require specific tools, APIs, or rigid prompting strategies.
To fix this, the industry standard has been Agentic Reinforcement Learning (Agentic RL). This typically involves a heavy-handed process: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) phases using methods like Group Relative Policy Optimization (GRPO). While effective, this approach is akin to performing brain surgery to teach someone a new card trick—it is expensive, risky, and resource-intensive.
Tencent has just proposed a radical alternative that might render that approach obsolete: Training-Free Group Relative Policy Optimization.
The Cost-Performance Dilemma
The current reliance on parameter tuning (physically changing the weights of the neural network) creates a significant bottleneck for developers and researchers. The paper identifies four critical flaws in the traditional fine-tuning approach:
- Computational Cost: Fine-tuning demands massive GPU resources. This forces a compromise where developers tune smaller models (under 32B parameters) because tuning the state-of-the-art giants is prohibitively expensive.
- Poor Generalization: Models optimized for a narrow task often forget how to do everything else. This leads to “siloed” models, increasing maintenance overhead.
- Data Scarcity: Specialized domains rarely have the thousands of high-quality annotated examples required for traditional RL.
- Overfitting: With limited data, fine-tuned models often simply memorize answers rather than learning logic, leading to brittle performance.
This creates a paradox: developers want the power of massive models (like GPT-4 or DeepSeek-V3) but can only afford to fine-tune small ones, leading to suboptimal performance in specialized tasks.
The Shift: From Parameters to Context
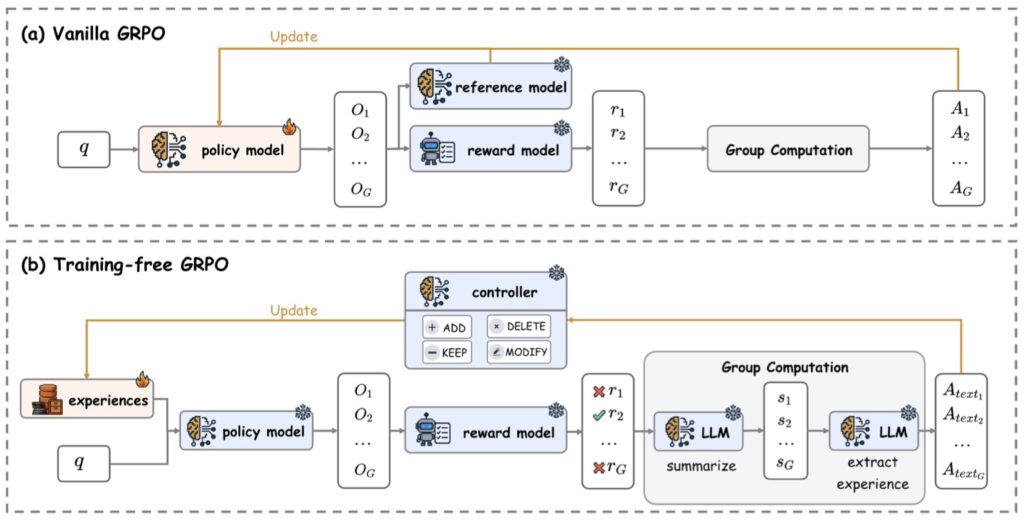
Tencent’s solution, Training-Free GRPO, fundamentally shifts the battlefield. Instead of asking “How do we change the model’s brain?”, it asks “How do we give the model better instructions based on experience?”
The method moves policy optimization from the parameter space to the context space.
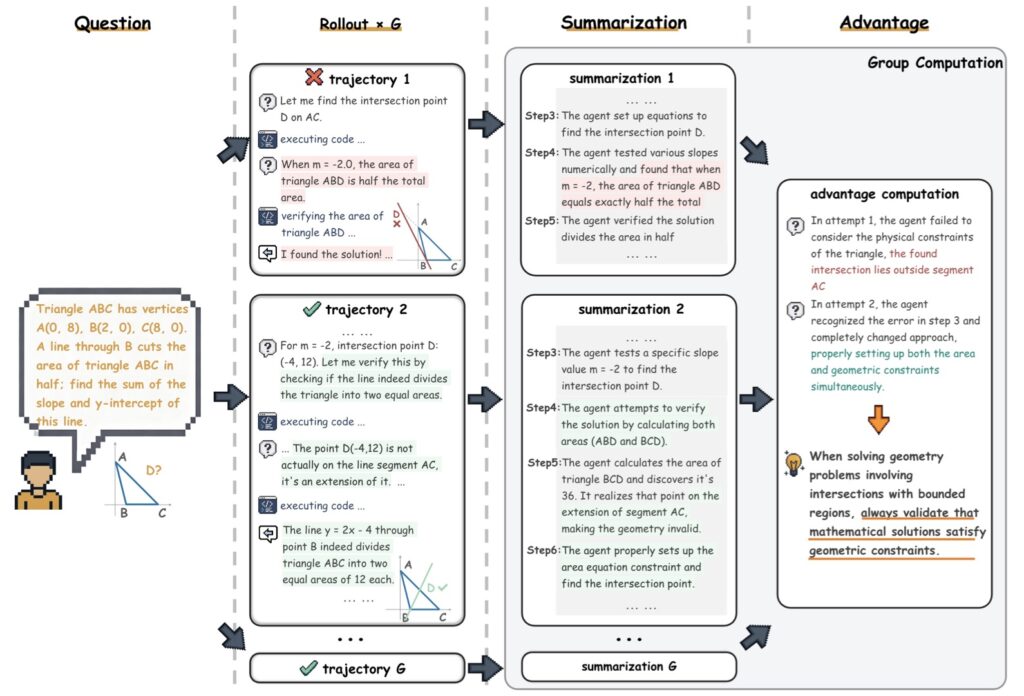
In traditional GRPO, the model generates a group of outputs, creates a numerical advantage score, and updates its weights. In Training-Free GRPO, the model generates rollouts, identifies a “semantic advantage” within that group, and distills high-quality “experiential knowledge.” This knowledge is then converted into a token prior—essentially a sophisticated, learned memory block that is fed back into the model during inference.
The Core Concept: The model doesn’t need to change its internal wiring to get better; it just needs to remember what worked previously. By treating memory as a policy optimizer, the LLM learns from its own attempts iteratively.
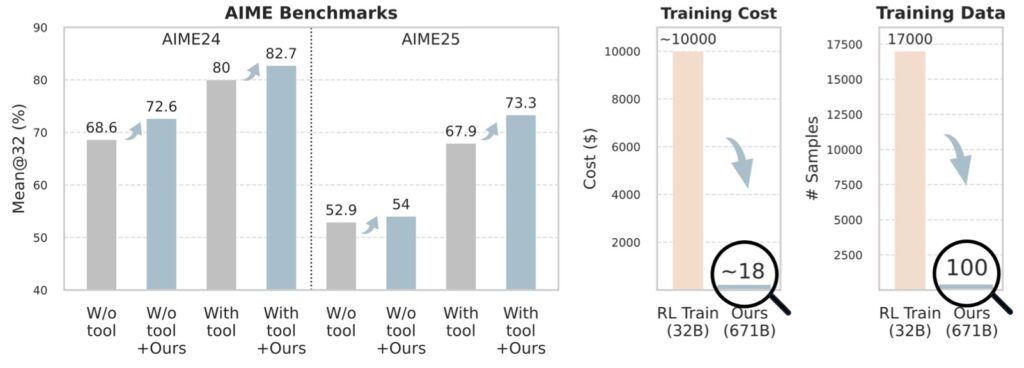
Breaking the $18 Barrier
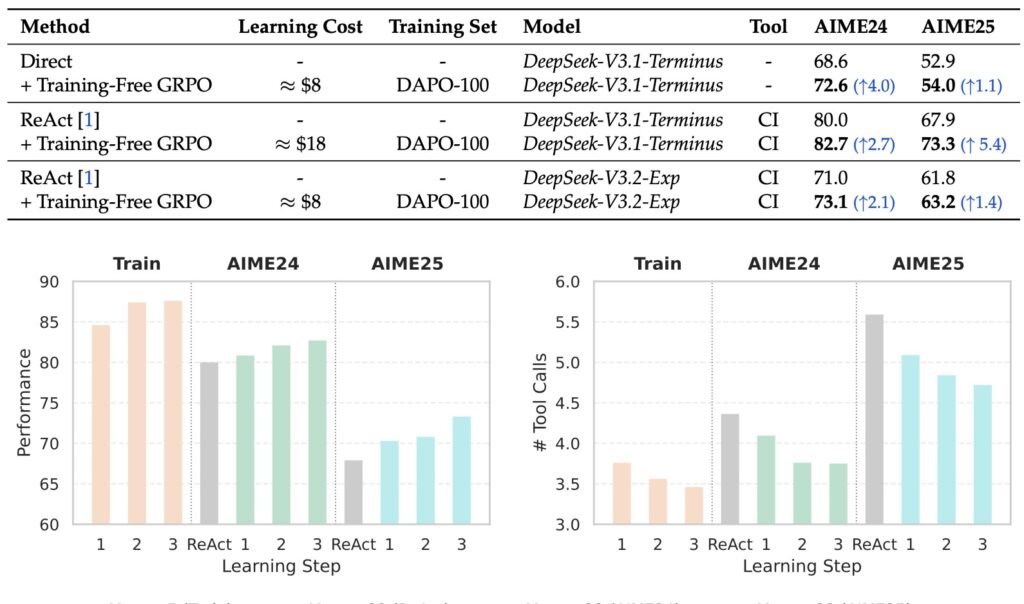
The efficiency gains reported are startling. By utilizing the DeepSeek-V3.1-Terminus model, the researchers demonstrated that they could achieve significant out-of-domain performance improvements with a budget as low as $18.
Because the method is “training-free,” it bypasses the need for massive GPU clusters. It iteratively distills knowledge over multiple epochs using a minimal ground-truth dataset—sometimes just a few dozen samples. This “learned token prior” is then seamlessly integrated during API calls.
This approach solves the data scarcity problem head-on. Where traditional fine-tuning requires rivers of data to avoid overfitting, Training-Free GRPO acts like a smart student taking notes. It distills the essence of success from a handful of examples and applies that logic immediately.
The Verdict: A New Path for Agents
The experiments on mathematical reasoning and web searching tasks are conclusive: Training-Free GRPO outperforms fine-tuned small LLMs.
This effectively kills the necessity of fine-tuning for a vast array of agentic tasks. It allows developers to leverage the raw power of massive, general-purpose models (via API) while still achieving the specialized, domain-specific high performance previously reserved for custom-trained models.
By decoupling performance gains from parameter updates, Tencent has opened the door to a future where AI agents are adaptable, cheap to deploy, and capable of learning from a handful of experiences—no GPU farm required.