From answering questions to executing complex workflows—how the new 32B parameter MoE model is redefining open-source AI.
- Beyond Chat: Kimi K2 is a Mixture-of-Experts model (32B activated / 1T total parameters) designed not just to converse, but to act, achieving state-of-the-art performance in coding, math, and agentic tool use.
- Architectural Breakthroughs: Powered by the novel MuonClip optimizer and the hybrid “Kimi Linear” architecture, the model achieves massive efficiency gains (up to 75% less KV cache usage) and training stability on 15.5T tokens.
- Open & Accessible: Available immediately as Kimi-K2-Base and Kimi-K2-Instruct, the model supports drop-in API integration, local hosting via vLLM/SGLang, and specialized coding capabilities through Kimi-Dev.

The era of the passive chatbot is ending. While the previous generation of Large Language Models (LLMs) excelled at retrieving information and generating text, the frontier of AI has shifted toward “Agentic Intelligence”—models that understand an environment, make decisions, and execute actions to achieve a goal. Enter Kimi K2, the latest Mixture-of-Experts (MoE) model that promises to bridge the gap between thinking and doing.
With 32 billion activated parameters and a staggering 1 trillion total parameters, Kimi K2 is meticulously optimized for agentic tasks. It does not merely answer; it acts. Whether you are a researcher needing a foundation model or a developer building complex workflows, Kimi K2 represents a leap forward in making advanced agentic intelligence open and accessible.
The “Reflex-Grade” Agent: Doing, Not Just Talking
Kimi K2 is designed to be a “reflex-grade” model. Unlike “thinking” models that may ponder indefinitely, Kimi K2 is built for immediate, effective interaction with tools. It automatically understands how to utilize provided utilities without requiring the user to script complex workflows.
The practical applications are vast and tangible. Imagine planning a dream Coldplay Tour 2025 in London. Kimi K2 can orchestrate this by executing 17 seamless tool calls spanning search engines, calendars, Gmail, flight aggregators, Airbnb, and restaurant bookings. In the realm of data science, it can take a request to explore remote-work salaries and autonomously execute 16 IPython calls to generate statistics, visualizations, and an interactive webpage of insights.
For developers, Kimi K2 brings intelligence to the command line. It can edit files, run commands, and debug its own work. In a demonstration of automating Minecraft development in JavaScript, the model managed rendering, ran test cases, captured failure logs, and iteratively improved the code until all tests succeeded. Similarly, when converting a Flask project to Rust, it systematically refactored the codebase and ran performance benchmarks to ensure robustness.
Engineering the “Era of Experience”
The development of Kimi K2 is rooted in the realization that human data is a finite “fossil fuel.” As noted by AI researchers, the growth of human-generated data lags behind the pace of compute. To transcend these limits, Kimi K2 embraces the “Era of Experience,” where models learn from self-generated interactions and reinforcement learning (RL).
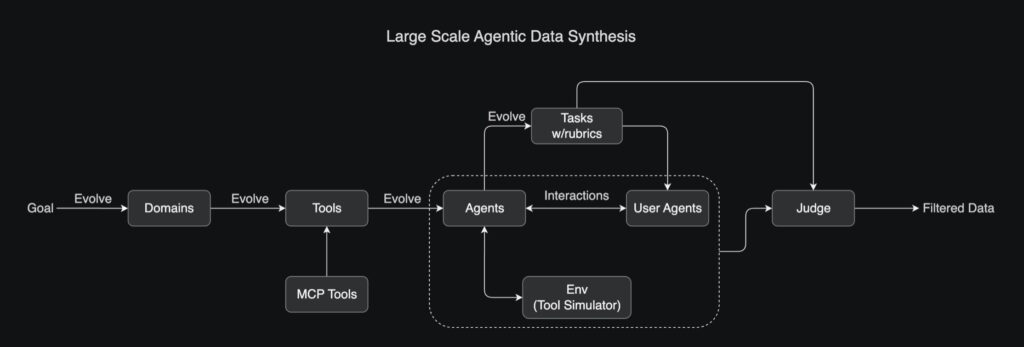
Large-Scale Agentic Data Synthesis
To teach Kimi K2 sophisticated tool use, the team developed a comprehensive pipeline inspired by ACEBench. This system simulates real-world scenarios by evolving hundreds of domains and thousands of tools—both real (via Model Context Protocol) and synthetic. Agents interact with these simulated environments, and an LLM judge evaluates the results against strict rubrics, filtering for high-quality training data.
General Reinforcement Learning
Kimi K2 utilizes a general RL system that handles both verifiable and non-verifiable rewards. For verifiable tasks like math or coding, success is binary. However, for non-verifiable tasks, such as writing a research report, the system uses a self-judging mechanism. The model acts as its own critic, providing scalable feedback. Interestingly, on-policy rollouts with verifiable rewards are used to continuously update this critic, ensuring it remains accurate even for subjective tasks.
Under the Hood: MuonClip and Kimi Linear
The performance of Kimi K2 is made possible by significant innovations in model architecture and optimization.
The MuonClip Optimizer:
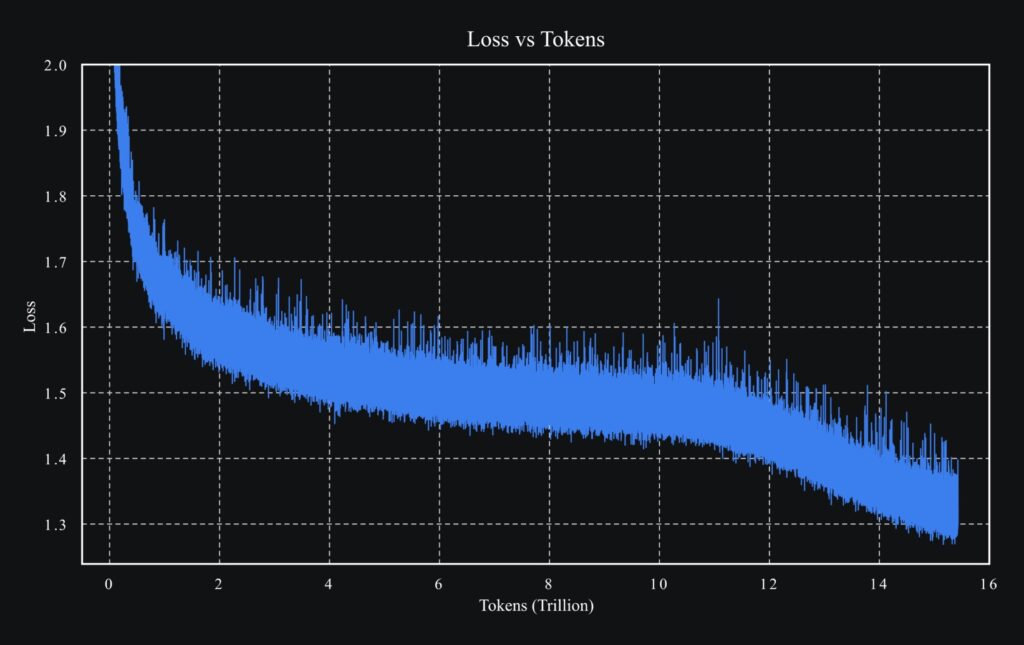
Training massive models often leads to instability, specifically “exploding attention logits.” Standard solutions like AdamW or simple logit soft-capping often fall short. Kimi K2 introduces MuonClip, an optimizer that stabilizes training by directly rescaling the weight matrices of query and key projections (qk-clip). This allowed the model to be pre-trained on 15.5 trillion tokens with zero training spikes, ensuring robust performance.
Kimi Linear Architecture:
Perhaps the most radical innovation is Kimi Linear, a hybrid linear attention architecture. By utilizing Kimi Delta Attention (KDA)—an expressive module that improves upon finite-state RNN memory—combined with Multi-Head Latent Attention (MLA), Kimi Linear outperforms full attention models. The results are striking: it reduces KV cache usage by up to 75% and achieves up to 6x decoding throughput for 1M context windows, making it a highly efficient drop-in replacement for traditional architectures.
Kimi-Dev: A New Standard for Software Engineering
Alongside the general model, the release includes Kimi-Dev, an open-source Software Engineering (SWE) LLM. Kimi-Dev bridges the gap between “Agentless” methods (single-turn, verifiable steps) and “SWE-Agent” frameworks (multi-turn interactions).
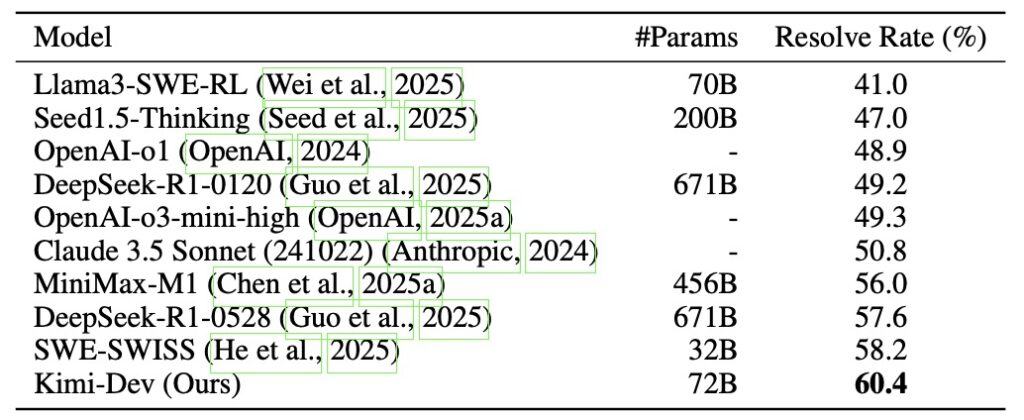
By curating a specific training recipe, Kimi-Dev achieves a score of 60.4% on SWE-bench Verified, the best among workflow approaches. When adapted with further supervised fine-tuning on 5,000 trajectories, it powers SWE-Agents to a 48.6% pass@1 rate, performing on par with proprietary giants like Claude 3.5 Sonnet. This proves that structured skill priors—localization, code editing, and self-reflection—are key to transferable coding agents.
Getting Started and Future Outlook
Kimi K2 is available today.
- For Users: The model is free to use on web and mobile via
kimi.com. - For Developers: An OpenAI/Anthropic compatible API is available, facilitating easy migration.
- For Researchers: The weights for Kimi-K2-Base (for fine-tuning) and Kimi-K2-Instruct (for immediate use) are open-sourced. The team recommends inference engines like vLLM, SGLang, or TensorRT-LLM for self-hosting.
Limitations and What’s Next
While Kimi K2 is a powerhouse, it is not without limitations. It currently lacks vision capabilities, and in scenarios with unclear tool definitions, it may generate excessive tokens. However, the roadmap is clear: future iterations will integrate “thinking” capabilities (System 2 reasoning) and visual understanding.
With Kimi K2, advanced agentic intelligence is no longer locked behind closed doors. It is open, efficient, and ready to build. Give Kimi K2 your tools, describe your task, and watch it get the job done.