Google’s latest research reveals that saying it twice is the zero-latency secret to better performance.
- Significant Gains: Google’s research shows that repeating a prompt twice improves model performance in 47 out of 70 benchmarks with zero accuracy regressions.
- The Mechanism: Because LLMs read sequentially, repeating the input allows the model to process the prompt with full context availability on the second pass.
- Zero Cost: This method enables “drop-in” deployment with no measurable increase in latency and no increase in output length.
In the complex world of Large Language Model (LLM) optimization, we are accustomed to trade-offs. Usually, better accuracy requires larger models, slower reasoning steps, or complex chain-of-thought prompting that eats up tokens and increases wait times. However, a new study from Google has unveiled a trivially simple method that defies this trend: Prompt Repetition.
The premise is exactly as simple as it sounds. Instead of sending a single query to an AI, you send the exact same input twice, back-to-back. The results are startlingly effective, offering a boost in accuracy without the usual costs associated with performance tuning.
How LLMs Read
To understand why this works, one must understand how standard LLMs process information. They are trained as “causal language models,” meaning they read tokens in strict order—from left to right. In a standard prompt, early tokens (the beginning of your sentence) cannot “attend to” or see the future tokens (the end of your sentence).
This creates a context blind spot. For example, the performance of a model can fluctuate wildy depending on whether you put the context before the question or the question before the context. When the model processes the beginning of a prompt, it does so without the full picture of what follows.
The Solution: <QUERY><QUERY>
Google’s solution transforms the input from <QUERY> to <QUERY><QUERY>. By repeating the prompt, the model gets a second chance to look at the information.
During the second pass (reading the repeated section), the model can “attend” to every token in the first pass. The first iteration serves as a complete memory bank for the second iteration. This ensures that when the model finally begins to generate an answer, it has processed the full context of the user’s intent, stabilizing predictions and improving logical connections.
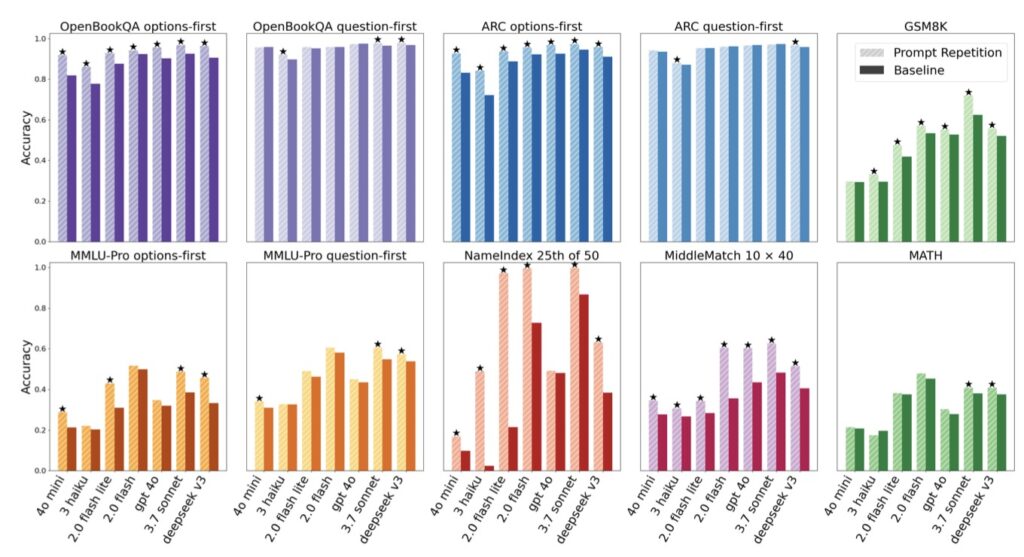
47 Wins, Zero Losses
The researchers tested this method across major popular systems at scale, and the data is compelling. Out of 70 different benchmarks, prompt repetition secured 47 wins. Perhaps even more impressive is the stability of the method: there were zero reported accuracy regressions.
Unlike complex prompting strategies that might improve math scores while hurting creative writing, prompt repetition appears to be universally beneficial for non-reasoning models. It effectively raises the floor of the model’s capabilities by ensuring it fully “understands” the input before speaking.
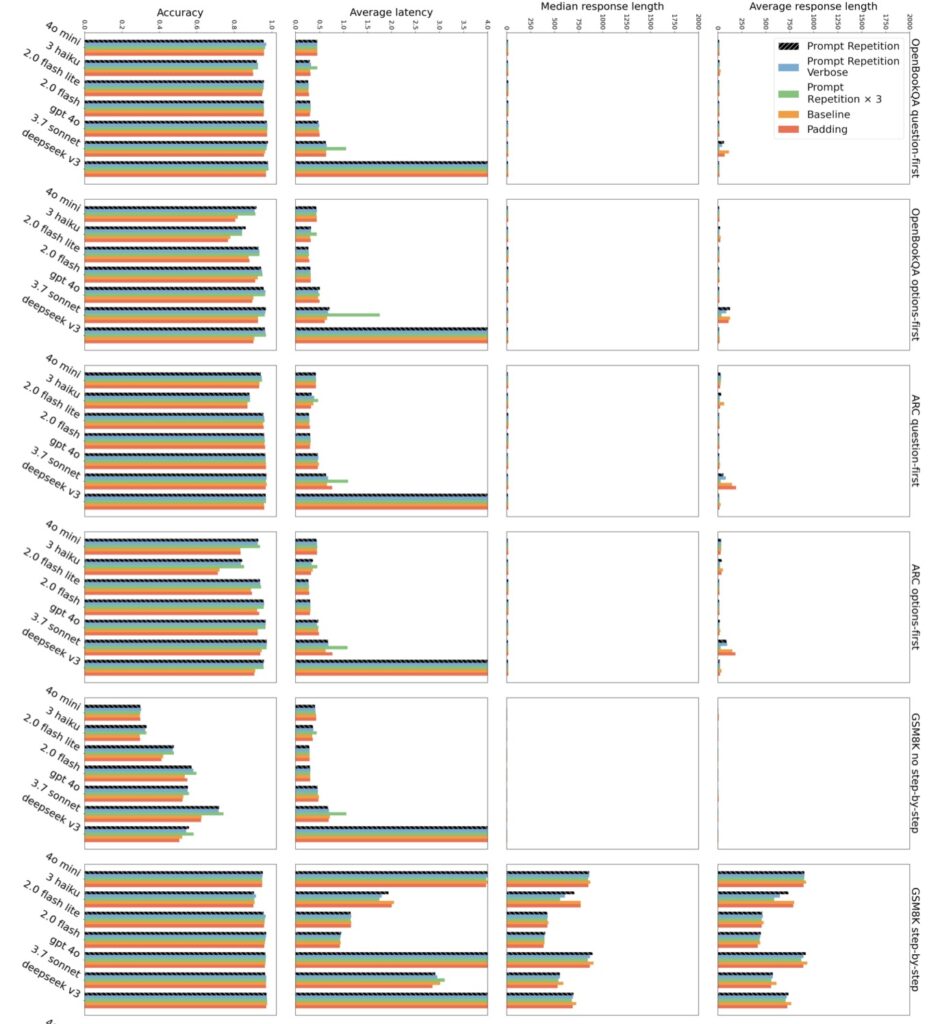
The “Free Lunch”: No Latency, No Extra Tokens
The most surprising aspect of this research is the lack of downside. One might assume that doubling the input length would double the processing time, but that isn’t the case.
- No Latency Cost: The “pre-fill” stage (reading the prompt) is highly parallelizable in modern GPU architectures. The time it takes to process the input is negligible compared to the time it takes to generate the output.
- Same Output Length: The model does not ramble or produce longer answers; it just produces better answers.
- Drop-in Deployment: Because the output format remains exactly the same, this change requires no re-engineering of existing data pipelines.
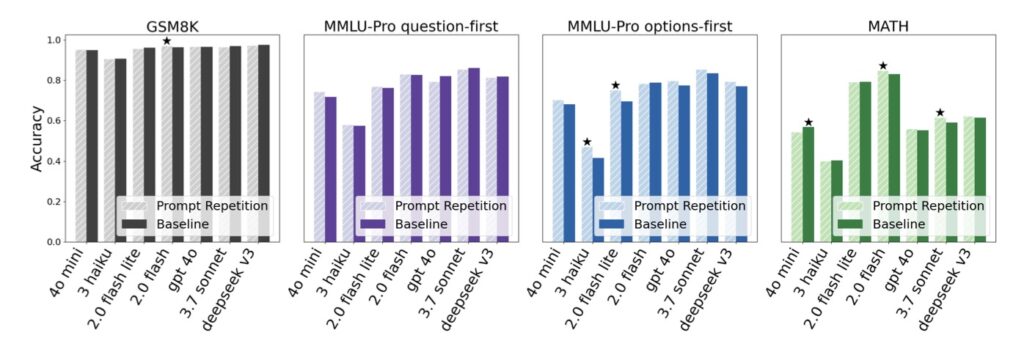
A New Default?
The study suggests that prompt repetition creates a “drop-in” upgrade for existing AI applications. You get higher accuracy simply by copying and pasting the input once.
Given that this method incurs no latency penalties while consistently outperforming single-pass prompts, the researchers suggest it might be a good default setting for many models and tasks where reasoning steps are not explicitly used. In a field obsessed with complexity, sometimes the best solution is simply to repeat yourself.