How a simple prompting trick called Verbalized Sampling overcomes the “Typicality Bias” that makes LLMs predictable.
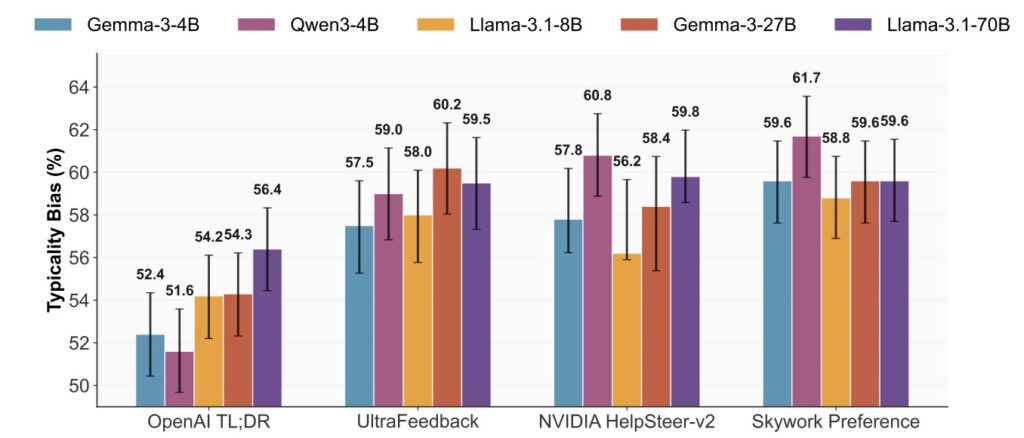
- The Root Cause: Research identifies “Typicality Bias”—a cognitive psychological tendency where human annotators consistently favor familiar, conventional text—as the primary driver behind mode collapse in aligned Large Language Models (LLMs), rather than just algorithmic flaws.
- The Solution: A novel, training-free strategy called Verbalized Sampling (VS) prompts models to explicitly generate a probability distribution over multiple responses, effectively bypassing the restrictive filter of post-training alignment.
- The Impact: VS significantly restores model diversity (by 1.6–2.1× in creative writing) and enhances performance across dialogue and synthetic data tasks, with the strongest benefits observed in the most capable models.

In the race to build safer and more helpful artificial intelligence, developers rely heavily on post-training alignment. This process fine-tunes Large Language Models (LLMs) based on human feedback to ensure they behave politely and accurately. However, this safety comes at a steep price: Mode Collapse.
Mode collapse occurs when an AI, despite having seen the vast breadth of human literature during pre-training, begins to output a narrow, repetitive range of responses. Until recently, researchers believed this was largely an algorithmic failure—a bug in the math of reinforcement learning. However, new findings suggest the problem isn’t just in the code; it is in the mirror. The issue stems from a fundamental property of the human mind known as Typicality Bias.
The Psychology of “Boring” AI
When human annotators are asked to rate AI responses during training, they unconsciously follow a pattern established in cognitive psychology: we prefer what we know. Humans have a systematic tendency to favor conventional, familiar, and “typical” responses over novel or complex ones.
When we train models on this data, we aren’t just teaching them to be safe; we are teaching them to be average. We effectively lobotomize the model’s creativity, forcing it to suppress the diverse distribution it learned during pre-training in favor of the narrow band of “safe” answers that humans tend to click “Like” on. This data-level driver creates a feedback loop where the model becomes increasingly confident in producing generic text, leading to the homogeneous outputs users often complain about.
Enter Verbalized Sampling (VS)
To combat this, researchers have introduced a surprisingly simple, training-free remedy called Verbalized Sampling (VS). Rather than retraining the model or changing the underlying alignment algorithms, VS changes how we ask the model to think.
Standard prompting asks the model for the single “best” answer, which triggers the aligned, typicality-biased response. Verbalized Sampling, however, leverages the model’s hidden statistical knowledge. It prompts the model to verbalize a probability distribution over a set of possible outcomes.
Example of a VS Prompt: “Generate 5 jokes about coffee and their corresponding probabilities.”
By asking the model to list options and assign probabilities, VS forces the LLM to reach back into its pre-trained “subconscious.” It brings the diverse, low-probability (but often highly creative) options back to the surface, bypassing the rigid filter imposed by human preference tuning.
Unlocking Potential Without Sacrificing Safety
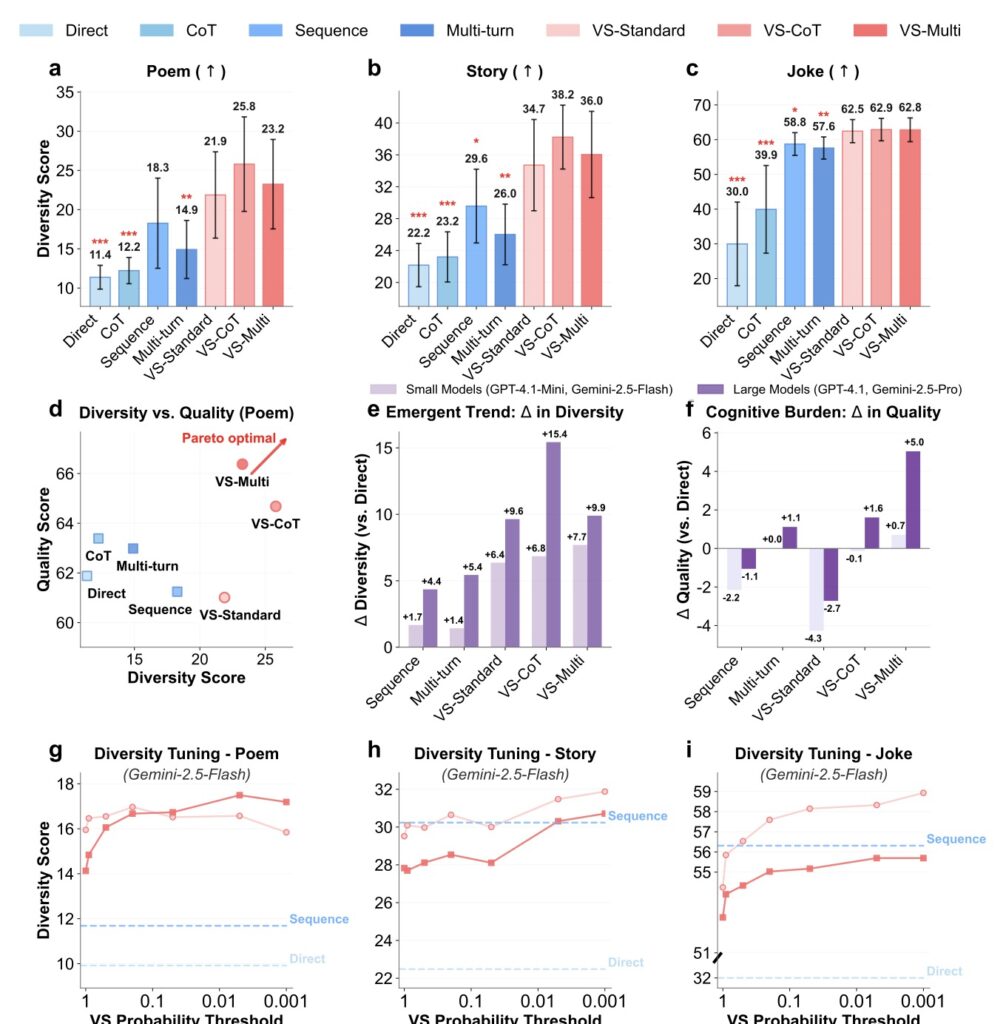
The results of this method are stark. Comprehensive experiments demonstrate that Verbalized Sampling acts as a key to unlock pre-trained generative diversity. In creative writing tasks—such as composing poems, stories, and jokes—VS increased diversity by 1.6 to 2.1 times compared to direct prompting.
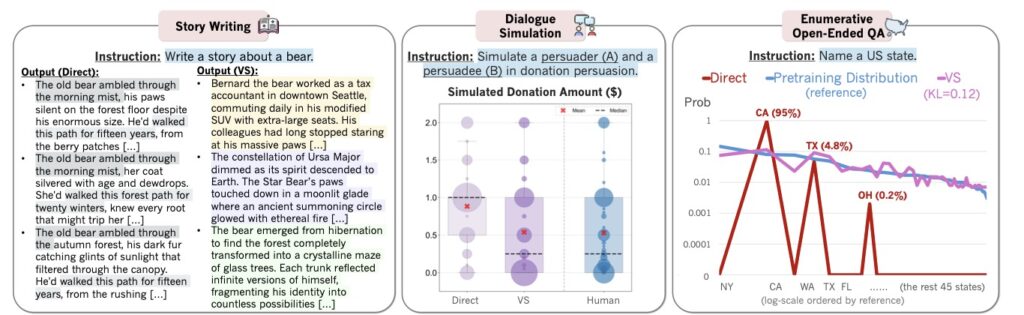
Crucially, this explosion in creativity does not come at the expense of utility. The method was tested across various domains, including:
- Dialogue Simulation: Creating more realistic and varied conversational agents.
- Open-Ended QA: Providing richer answers to complex questions.
- Synthetic Data Generation: Creating diverse datasets for training other models.
In all cases, the models maintained their factual accuracy and safety standards. The method effectively separates the “safety” of alignment from the “boredom” of typicality bias.
The “Smarter Model” Effect
Perhaps the most intriguing finding is an emergent trend regarding model capability. The study observed that more capable models benefit more from Verbalized Sampling.
Because stronger models have a better grasp of probability and a richer pre-trained knowledge base, they are more adept at verbalizing these distributions when prompted. This suggests that as LLMs continue to grow in power, techniques like VS will become even more effective, serving as a practical, inference-time switch to toggle between “safe and predictable” and “diverse and creative.”
By diagnosing mode collapse as a data-centric issue rooted in human psychology, we can stop fighting the algorithm and start working with the model’s inherent probability distributions. Verbalized Sampling offers a lightweight, powerful way to ensure that the future of AI remains not just safe, but surprisingly creative.