A new architectural philosophy aims to move AI past its “ENIAC phase” by abandoning general-purpose GPUs for model-specific hardware.
- The Specialization Shift: To overcome the “astronomical” costs and high latency of current AI, the industry is seeing a move toward total hardware specialization where silicon is custom-built for one specific model.
- Breaking the Memory Wall: By merging storage and computation on a single chip at DRAM-level density, new architectures are eliminating the need for expensive liquid cooling, HBM, and complex interconnects.
- Proven Results: Early implementations of “hard-wired” models are already demonstrating performance jumps of 10x in speed and 20x in cost reduction compared to traditional software-based GPU setups.
For all the talk of an AI revolution, the physical reality of the technology remains surprisingly cumbersome. Today’s most advanced large language models (LLMs) rely on what are essentially room-sized supercomputers—beasts of copper and silicon consuming hundreds of kilowatts, tethered by miles of cabling and kept alive by sophisticated liquid cooling. This “brute force” approach to intelligence has created two massive bottlenecks: high latency that disrupts human flow and an operational cost that makes widespread adoption a financial Everest.
However, a shift is occurring that mirrors the transition from the vacuum tubes of the ENIAC to the era of the transistor. While the industry has largely accepted “data center sprawl” as an inevitability, a startup named Taalas is betting that the path to ubiquitous AI lies in radical simplification and the death of general-purpose hardware.
From Software to “Hardcore” Models
The core of this new movement is a departure from the “one-size-fits-all” nature of GPUs. While GPUs are versatile, they are arguably inefficient for the singular, critical workload of AI inference. Taalas’s philosophy centers on Total Specialization: transforming a specific, previously unseen AI model into custom silicon in just two months.
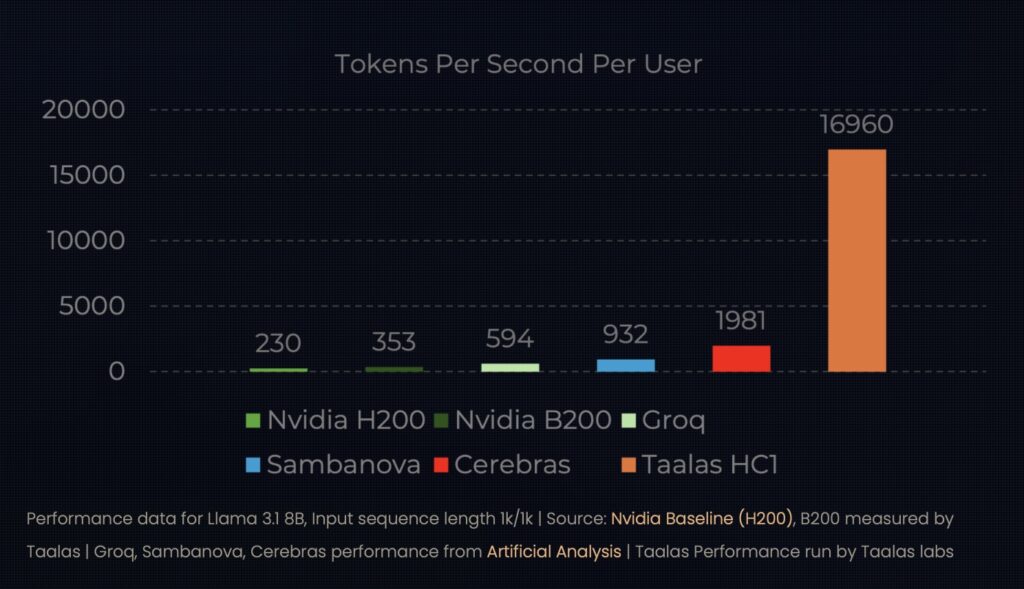
These “Hardcore Models” treat the AI’s weights not as software to be loaded, but as part of the hardware itself. By hard-wiring a model like Llama 3.1 8B into a chip, researchers have achieved speeds of 17,000 tokens per second. To put that in perspective, that is nearly 10 times faster than the current state-of-the-art, while simultaneously consuming 10 times less power.
Merging Storage and Computation
One of the most persistent “paradoxes” in computer science is the divide between memory and compute. Historically, accessing off-chip DRAM is thousands of times slower than on-chip operations, leading to the massive I/O bandwidth and power-hungry HBM (High Bandwidth Memory) stacks seen in modern chips.
The reported breakthrough from Taalas involves eliminating this boundary entirely. By unifying storage and compute on a single chip at DRAM-level density, the architecture removes the need for exotic packaging or 3D stacking. This “radical simplification” doesn’t just make the chips faster; it makes them significantly cheaper to manufacture, potentially reducing total system costs by an order of magnitude.

A Precision Strike in a World of Hype
Perhaps as interesting as the technology is the methodology behind it. In a “deep-tech” sector often defined by massive venture rounds and “medieval” attempts to solve problems with sheer scale, the development of this silicon Llama was handled by a lean team of just 24 people. They spent only $30 million of the $200 million they raised to bring their first product to life—a rarity in a field where billion-dollar “burn rates” are common.
While the first-generation chips (HC1) utilize a custom 3-bit data type—which does result in some quality trade-offs compared to full-precision GPU benchmarks—the roadmap is moving fast. A second-generation platform (HC2) using standard 4-bit floating-point formats is already in the works, promising higher density and even faster execution for “frontier” LLMs by winter.
The Future of Instantaneous AI
The ultimate goal of this hardware shift is to make AI “instantaneous.” When inference runs at sub-millisecond speeds and near-zero cost, the types of applications change. We move from “chatting” with a slow bot to integrating AI into real-time agentic workflows that don’t disrupt the human “state of flow.”
By moving away from the “city-sized data center” model and toward hyper-efficient, specialized silicon, the industry may finally find a way to make intelligence as cheap and accessible as electricity. As these hard-wired models move from the lab to the hands of developers, the “ENIAC era” of AI might be coming to a close sooner than we thought.