How a new AI framework is bridging the gap between 4D geometry and realistic video editing.
- The Challenge: Inserting objects into video (VOI) has historically failed to look realistic due to complex lighting, shadows, and moving occlusions in 4D space.
- The Solution: “InsertAnywhere” is a new framework that combines 4D scene geometry with diffusion models to place objects that respect both the physical space and the lighting of the video.
- The Enabler: To train this system, the researchers developed ROSE++, a massive illumination-aware dataset that allows the AI to learn from realistic “before and after” insertion scenarios.
Recent years have seen an explosion in the capabilities of AI video generation. From creating surreal landscapes to animating static images, the technology is moving fast. However, for industries like commercial advertising and film post-production, a specific hurdle has remained stubbornly high: Video Object Insertion (VOI). It is one thing to generate a new video from scratch; it is an entirely different challenge to seamlessly insert a new object into an existing video clip so that it looks like it was there all along.
The problem lies in the complexity of the real world. A video isn’t just a series of flat images; it is a representation of a 4D scene (3D space plus time). Current methods often struggle because they lack “4D scene understanding.” When you paste a virtual soda can onto a table in a video, standard editors often fail to account for how the light hits the can, how the can casts a shadow on the table, or how a passing hand might obscure (occlude) the can. These failures break the illusion, making the edit look cheap and artificial.
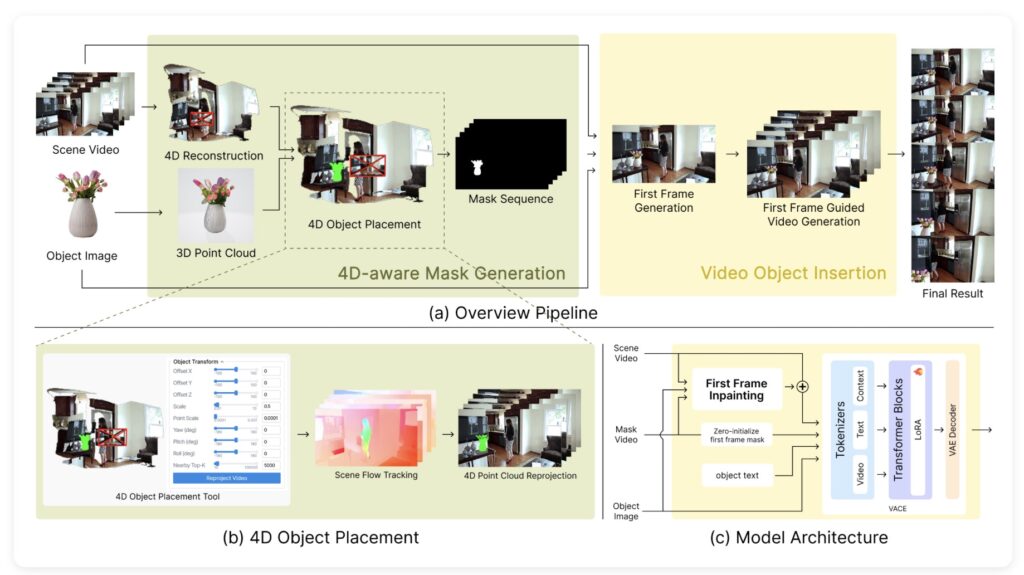
Enter InsertAnywhere, a groundbreaking VOI framework designed to solve these specific pain points. This new method moves beyond simple 2D editing by bridging the gap between 4D scene geometry and modern diffusion-based synthesis. The result is an object placement that is not only geometrically consistent—staying “glued” to the spot even as the camera moves—but also photometrically realistic, reacting naturally to the environment’s lighting.

The magic of InsertAnywhere begins with its “4D-aware mask generation module.” Before generating the final pixels, the system reconstructs the geometry of the scene. It propagates the user’s desired object placement across all frames, ensuring temporal coherence. This means if the camera pans or an object moves in front of the insertion spot, the system understands the depth and handles the occlusion correctly. It builds a spatial foundation that respects the laws of physics before it even begins to paint the object.
Once the geometry is locked in, the framework employs an extended diffusion-based video generation model. This isn’t just about rendering the object; it is about “joint synthesis.” The model generates the inserted object while simultaneously synthesizing the surrounding local variations. It calculates how the object should be illuminated and, crucially, how it should cast shadows or reflect light onto its surroundings. This dual approach ensures the inserted item feels anchored in the reality of the footage.

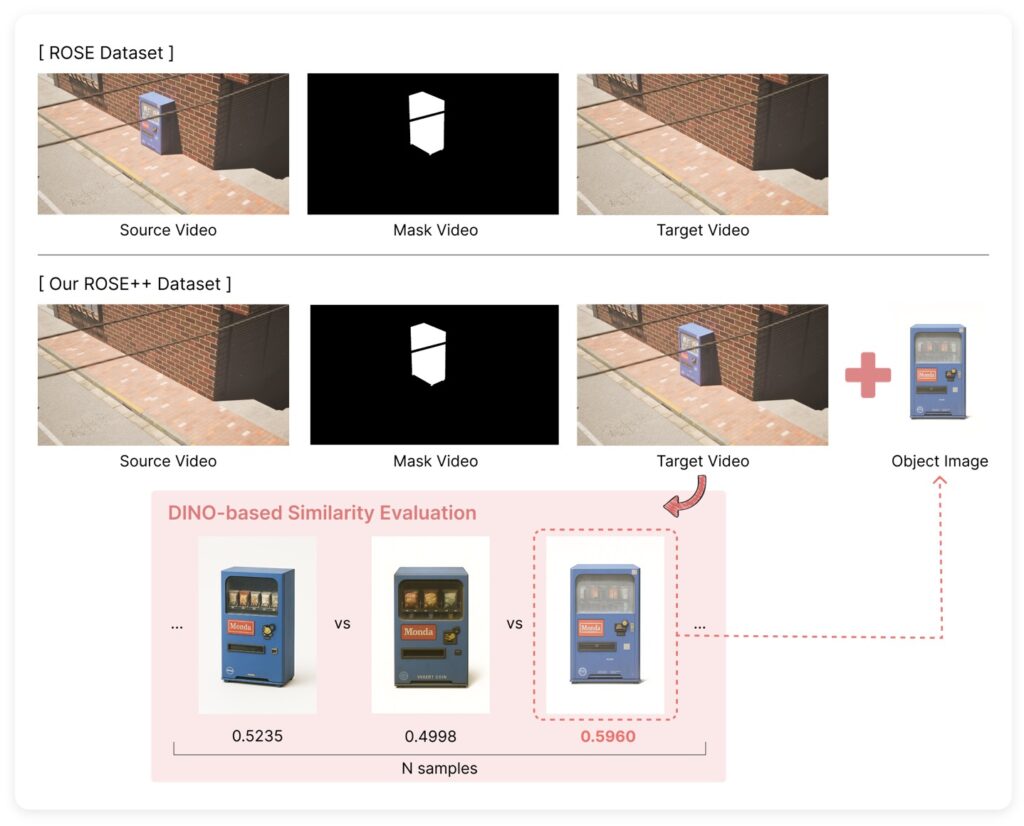
To teach an AI to do this effectively, the researchers needed high-quality data, which led to the creation of ROSE++. This is a novel, illumination-aware synthetic dataset. By taking the existing ROSE object-removal dataset and transforming it using Visual Language Model (VLM) generated reference images, they created triplets of data: videos with objects, videos without them, and the reference imagery. This supervised training ground allowed InsertAnywhere to learn the nuances of light and shadow in a way previous models could not.

The implications for this technology are significant. Through extensive experiments in diverse real-world scenarios, InsertAnywhere has demonstrated that it significantly outperforms both existing research methods and current commercial models. The quality is now high enough for production environments, opening the door for seamless virtual product placement and dynamic branded content generation. With InsertAnywhere, the line between what was filmed and what was generated is becoming invisible.
