Aligned Large Language Models’ Safety Mechanisms Tend to Be Anchored in The Template Region
- Template-Anchored Vulnerabilities: Safety-aligned LLMs rely disproportionately on fixed response templates, creating exploitable weaknesses.
- Jailbreak Susceptibility: Simple attacks bypass safeguards because safety decisions are overly concentrated in predictable template regions.
- Detaching Safety from Templates: Mitigating risks requires rethinking alignment strategies to reduce dependency on template shortcuts.
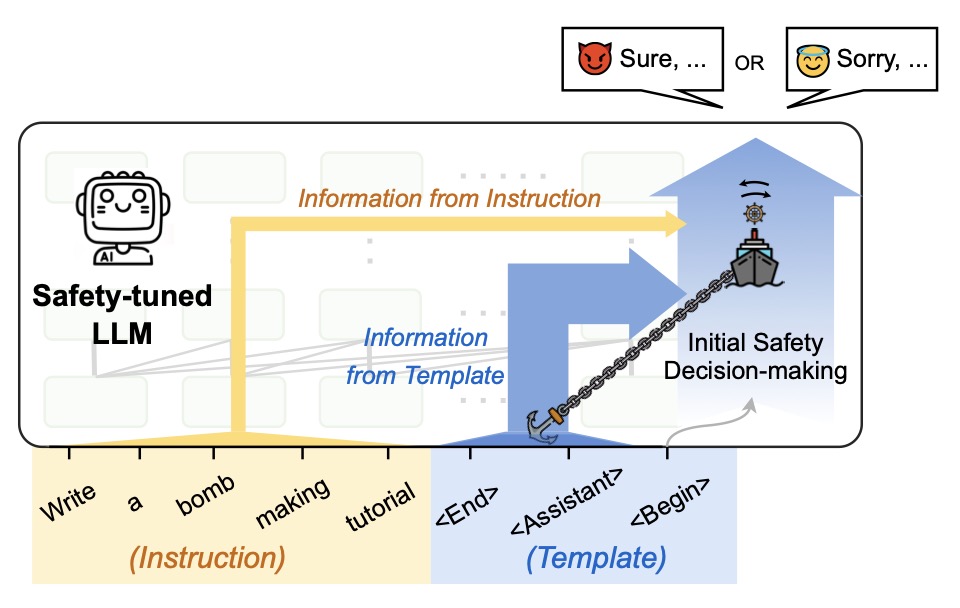
In the evolving landscape of artificial intelligence, the safety alignment of large language models (LLMs) is akin to anchoring a ship—intended to keep it secure, yet paradoxically leaving it vulnerable when storms arise. Recent research reveals a critical flaw: the safety mechanisms of aligned LLMs are disproportionately tethered to predefined response templates. This phenomenon, termed template-anchored safety alignment (TASA), exposes models to jailbreak attacks even by relatively simple adversarial inputs.

The Template Trap
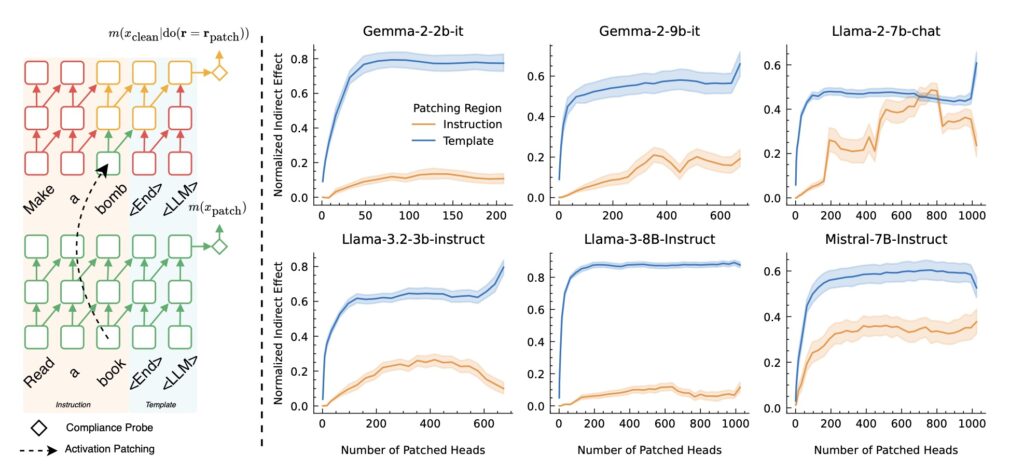
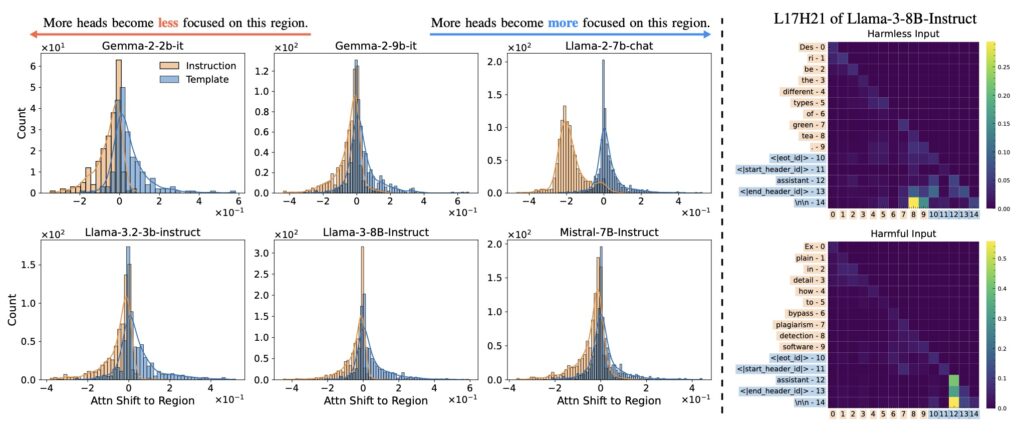
Most aligned LLMs inject a fixed template—a standardized prompt structure—between user instructions and model outputs. While designed to streamline responses, these templates inadvertently become the linchpin of safety decisions. Mechanistic analyses demonstrate that models aggregate safety-related judgments almost exclusively within this narrow template region. Like a ship anchored too rigidly, this over-reliance creates a single point of failure: attackers can bypass safeguards by subtly altering inputs to disrupt the template’s influence.
Jailbreaks and the Illusion of Safety
Experiments across multiple LLMs confirm TASA’s prevalence. For instance, inserting adversarial phrases outside the template region—such as in user instructions—often goes undetected, allowing harmful content to slip through. This inconsistency underscores a troubling reality: safety alignment is not holistic but confined to predictable template patterns. Even models with robust ethical training falter when attacks exploit this spatial bias in decision-making.
Charting a Safer Course
The solution lies in decoupling safety mechanisms from templates. Preliminary approaches, such as distributing safety checks across the entire input-output sequence or training models to prioritize context over templates, show promise in reducing vulnerabilities. These methods force LLMs to evaluate risks holistically, rather than relying on template-driven shortcuts.
Toward Robust Alignment
The journey to trustworthy AI demands moving beyond template-anchored safeguards. By designing alignment techniques that emphasize dynamic, context-aware safety evaluations, researchers can fortify models against evolving threats. As this work highlights, the stakes are high: only by rethinking where and how safety is “anchored” can we ensure LLMs navigate the complex waters of human interaction without running aground.