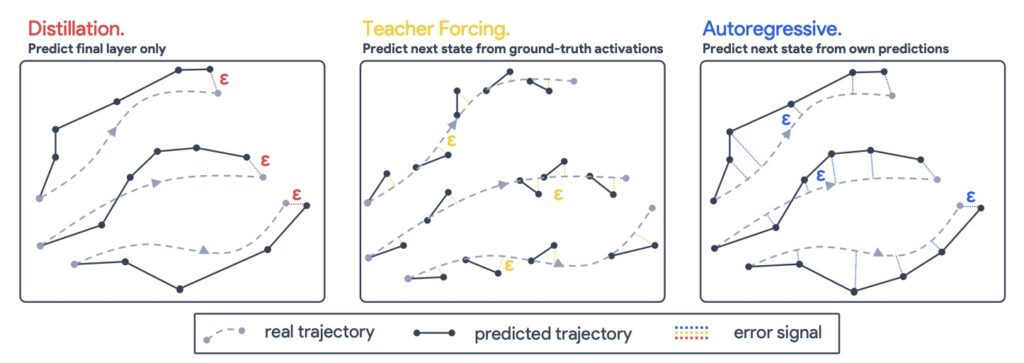
Unveiling the “Block-Recurrent Hypothesis” and the emergence of dynamical simplicity in deep learning.
- The Block-Recurrent Hypothesis (BRH): Deep Vision Transformers (ViTs) often operate like recurrent systems, where distinct layers can be accurately modeled as a loop of repeated computational blocks.
- Raptor as Proof: By creating surrogate models called “Raptor,” researchers demonstrated that a massive DINOv2 model could recover 96% of its accuracy using only 2 distinct blocks applied recurrently.
- Dynamical Interpretability: Analyzing these models as dynamical systems reveals that they function through “attractors,” where data flows into stable states with self-correcting trajectories and low-dimensional convergence.
As Vision Transformers (ViTs) cement their status as the standard backbone for computer vision, a fundamental question remains unanswered: How do they actually “think”? While we understand the architecture—stacks of attention and feed-forward layers—we lack a clear mechanistic account of their computational phenomenology.
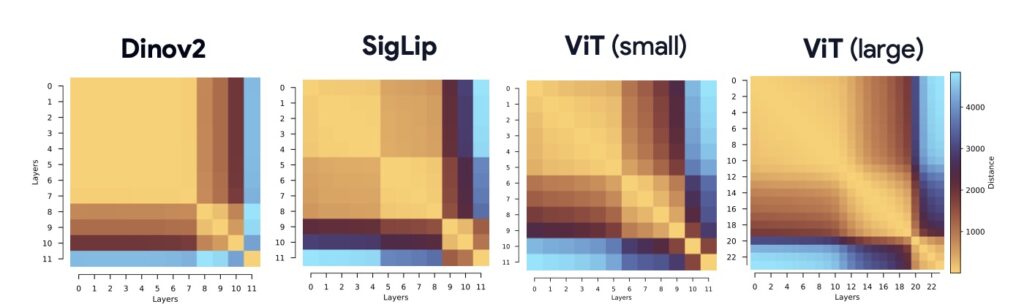
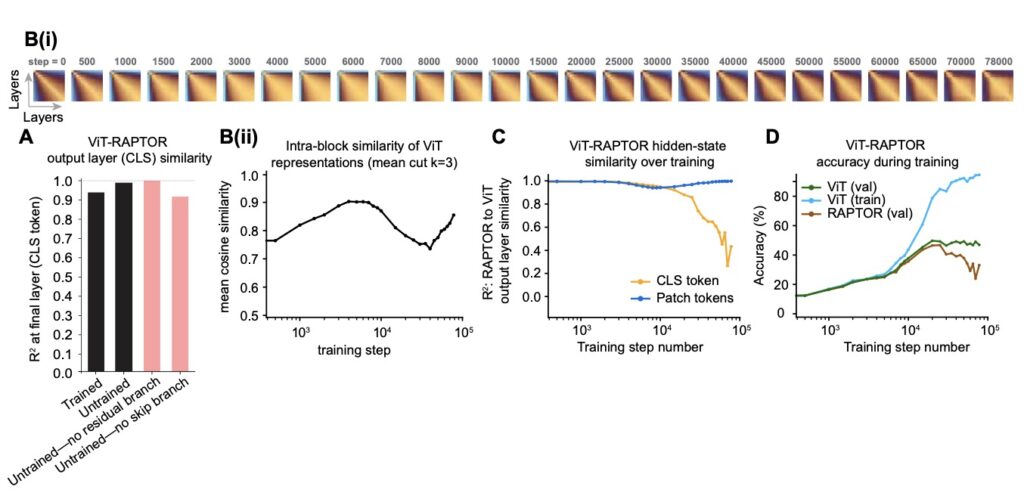
Traditionally, we view the depth of a Transformer as a hierarchy of distinct features. However, architectural cues have long hinted at a different structure. Despite having distinct weights at every layer, trained ViTs show remarkable similarity between layers. This has led to the proposal of the Block-Recurrent Hypothesis (BRH). The hypothesis argues that trained ViTs possess a hidden structure where the computation of the original L blocks can be rewritten using only kdistinct blocks applied recurrently (where k≪L). In essence, the model isn’t climbing a ladder of unique steps; it is iterating through a loop.
From Similarity to Function: Introducing Raptor
Observing that layers look similar (representational similarity) is one thing; proving they act similar (functional similarity) is another. To bridge this gap, researchers operationalized the BRH by creating Raptor (Recurrent Approximations to Phase-structured TransfORmers).
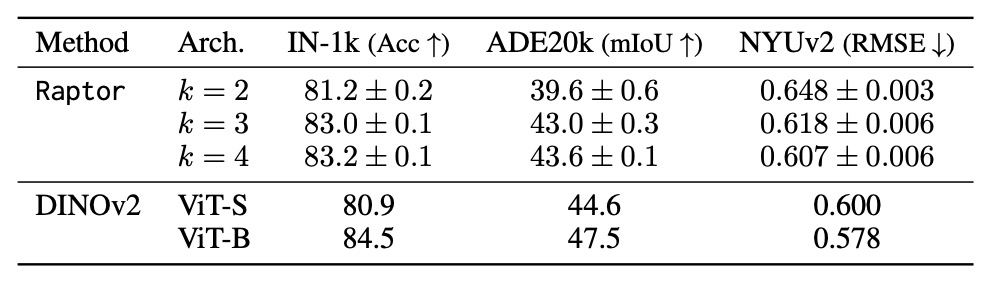
Raptor acts as a block-recurrent surrogate for pre-trained ViTs. The results provide a striking existence proof for the hypothesis. When applied to foundation models, the researchers showed they could train a Raptor model to recover 96% of DINOv2 ImageNet-1k linear probe accuracy using only 2 distinct blocks. This was achieved while maintaining equivalent computational costs to the original model.
This suggests that the vast parameter space of deep ViTs collapses into a “recurrence induced simplicity bias.” The diverse layers of a massive model are effectively performing the same few operations over and over again.
Dynamical Interpretability: Viewing Depth as a Flow
If ViTs are recurrent, they can be studied using the principles of dynamical systems—physics-based analysis of how states change over time (or in this case, over depth). This approach, termed Dynamical Interpretability, views the model’s depth as a “flow on directions.” The findings reveal a fascinating internal choreography:
- Attractors and Self-Correction: The data processing within the model shows directional convergence into “angular basins.” Much like a ball rolling to the bottom of a bowl, the representation flows toward specific attractors. Crucially, these trajectories are self-correcting; under small perturbations, the model naturally adjusts its path back toward the attractor.
- Token-Specific Dynamics: Not all tokens behave the same. The
clstoken (the classification token) executes sharp, late-stage reorientations—essentially making its final decision at the last moment. In contrast,patchtokens exhibit a “mean-field effect,” converging rapidly toward a mean direction with strong coherence. - Low-Rank Collapse: In the later depths of the model, the updates collapse to a low rank. This is consistent with convergence to low-dimensional attractors, meaning the model simplifies the data into a very specific, manageable subspace before outputting a result.
The Role of Training and Stochastic Depth
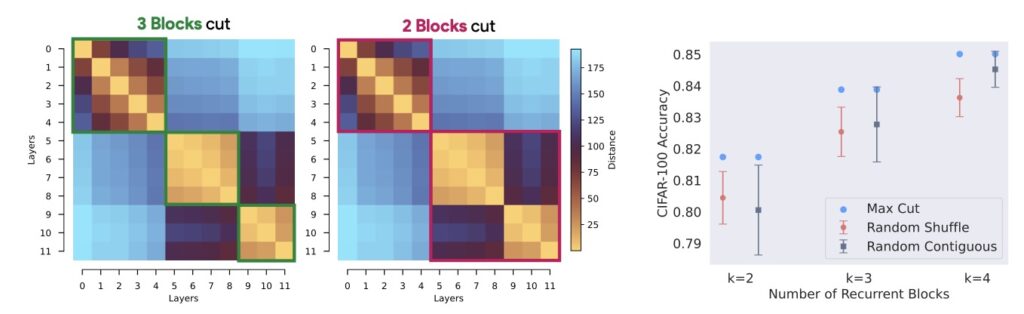
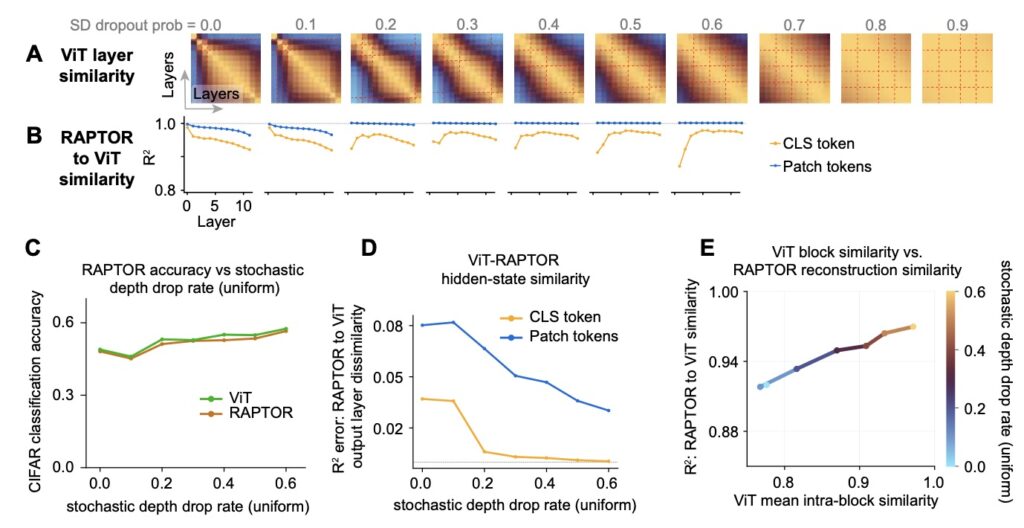
What causes this recurrent structure to emerge? Experiments with small-scale ViTs suggest that specific training techniques, particularly stochastic depth (randomly dropping layers during training), play a significant role in promoting this block structure. Furthermore, residual pathways seem implicated in facilitating this recurrence.
While the Raptor models show that two tied blocks can recover most of a model’s performance, a small residual gap remains. This suggests that while recurrence is the dominant behavior, there may be subtle, time-varying components or “punctuated transitions” that require further study.
The Block-Recurrent Hypothesis offers a transformative view of modern deep learning. It suggests that despite their immense size, Vision Transformers naturally gravitate toward low-complexity, normative solutions. By recognizing that these models admit a recurrent structure, we can move away from treating them as black boxes of distinct layers and instead analyze them through principled dynamical systems analysis. The “deep” network is, in many ways, a simple loop refining its understanding through repeated iteration.