Uncovering fundamental flaws in GRPO and introducing History-Aware Adaptive Difficulty Weighting (HA-DW) as the critical fix.
- The Hidden Flaw: While Group Relative Policy Optimization (GRPO) is a standard for training reasoning models, new research reveals its advantage estimator is inherently biased, leading to flawed learning dynamics.
- The Imbalance: This bias systematically underestimates the value of solving “hard” problems while overestimating “easy” ones, causing the model to explore and exploit inefficiently.
- The Solution: A new method called History-Aware Adaptive Difficulty Weighting (HA-DW) corrects this by dynamically adjusting based on the model’s evolving history, showing consistent improvements across five major benchmarks.
In the rapidly evolving landscape of Large Language Model (LLM) post-training, the quest for superior reasoning capabilities has led researchers toward Reinforcement Learning from Verifier Rewards (RLVR). This approach has become the bedrock for teaching models how to “think” through complex tasks. Within this domain, group-based methods—specifically Group Relative Policy Optimization (GRPO) and its variants—have gained massive adoption.
The appeal of GRPO is logical: it relies on group-relative advantage estimation. By comparing a model’s output against a group of its own generations, developers can avoid the computational expense and complexity of training separate “learned critics.” However, while widely used, the theoretical properties of this shortcut have remained poorly understood—until now.
The Diagnosis: A Fundamental Bias
Recent theoretical analysis has uncovered a critical issue at the heart of group-based RL: the group-relative advantage estimator is inherently biased relative to the true, expected advantage. While the method was designed for efficiency, it introduces a distortion in how the model perceives its own success.

The research identifies a specific, systematic failure in how these algorithms handle difficulty:
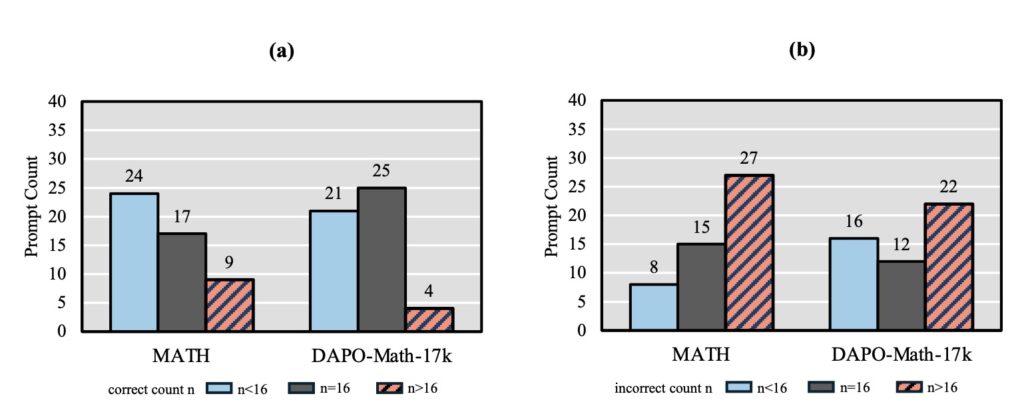
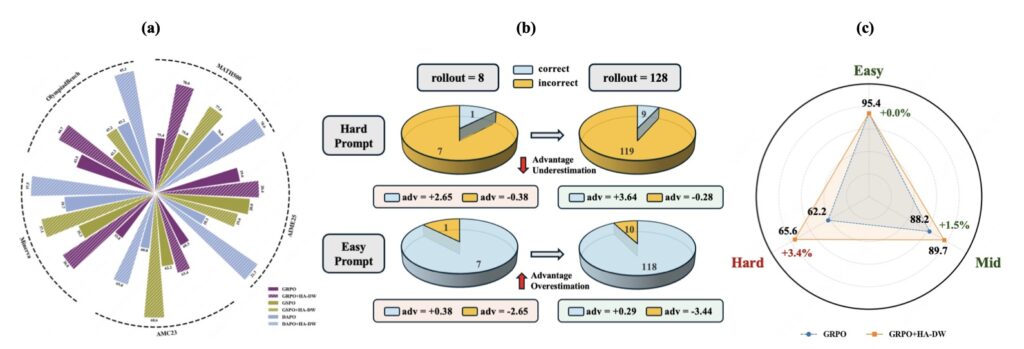
- Hard Prompts: The system systematically underestimates the advantage gained from solving difficult problems. This discourages the model from attempting to learn from complex reasoning paths where the payoff is highest.
- Easy Prompts: Conversely, it overestimates the advantage for easy prompts. This leads the model to over-focus on trivial tasks where it already performs well.
This distortion results in imbalanced exploration and exploitation. The model fails to push its boundaries on hard tasks because the feedback signal is dampened, while it wastes resources perfecting tasks it has already mastered.
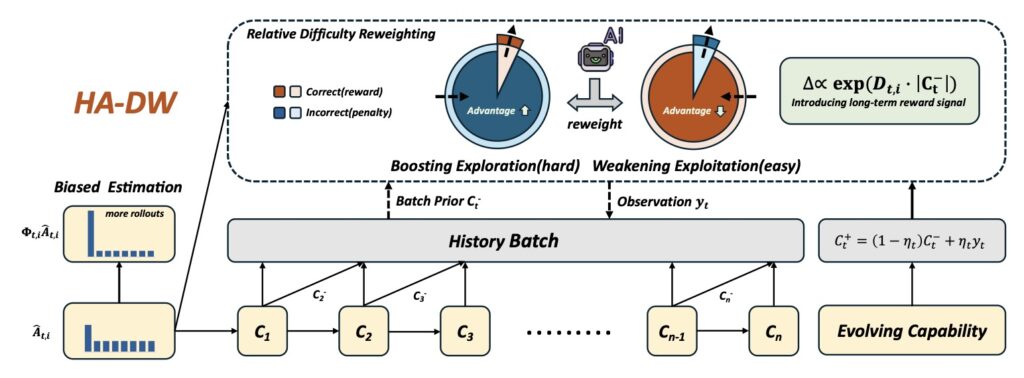
The Solution: History-Aware Adaptive Difficulty Weighting (HA-DW)
To correct this fundamental imbalance, researchers have proposed a novel solution: History-Aware Adaptive Difficulty Weighting (HA-DW).
HA-DW moves beyond the static snapshot of the current group. Instead, it introduces an adaptive reweighting scheme that adjusts advantage estimates based on two critical factors:
- The Evolving Difficulty Anchor: It contextualizes the current problem’s difficulty relative to what the model has faced before.
- Training Dynamics: It monitors the model’s history to ensure the reward signal remains accurate as the model gets smarter.
By dynamically adjusting the weights based on the model’s evolving state, HA-DW neutralizes the bias. It ensures that hard problems yield the high reward signal they deserve, encouraging the model to tackle complex reasoning tasks head-on.
Validating the Fix
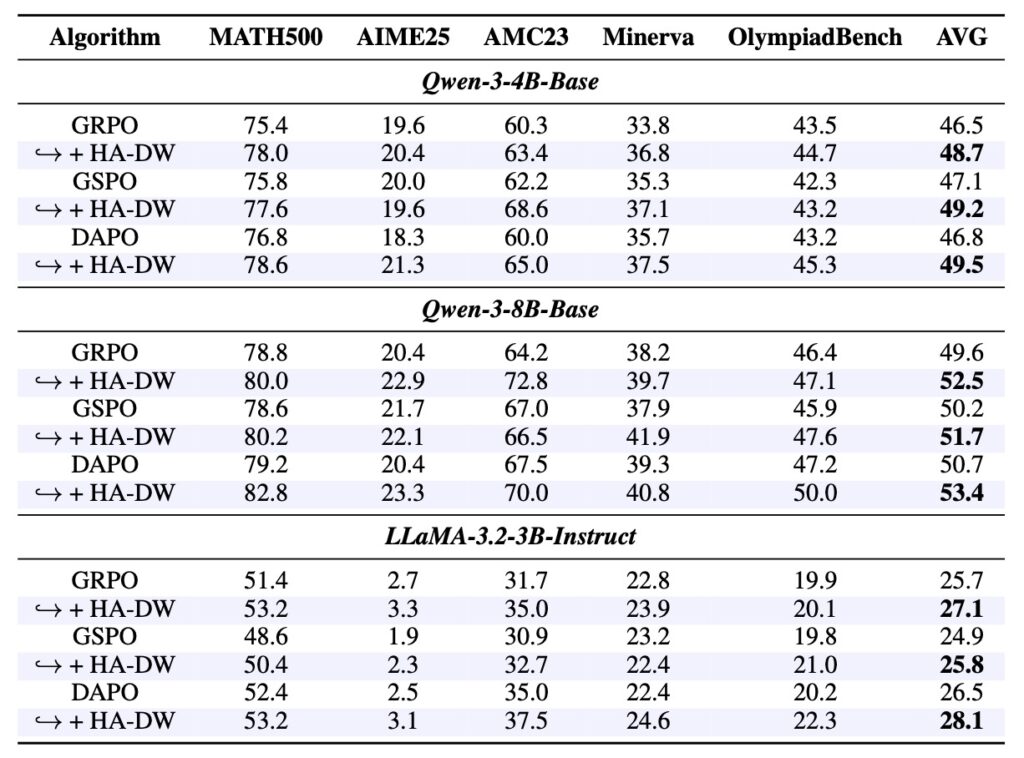
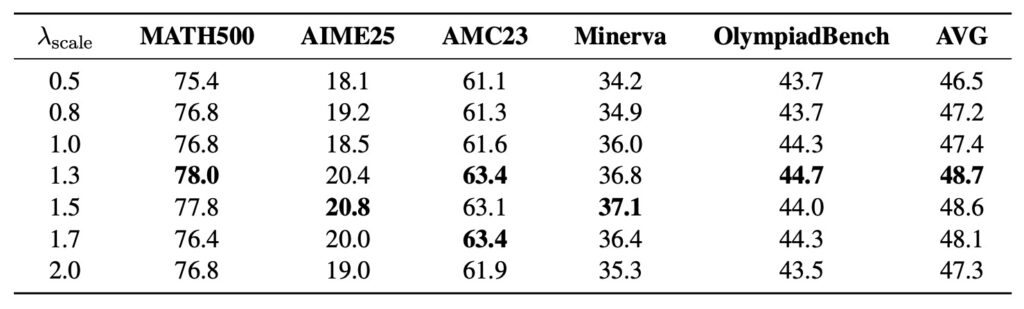
The effectiveness of HA-DW is not merely theoretical; it has been rigorously stress-tested. Extensive experiments conducted on five mathematical reasoning benchmarks demonstrate that HA-DW consistently outperforms standard methods when integrated into GRPO and its variants.
The results are clear: correcting biased advantage estimation is not an optional optimization—it is critical for robust and efficient RLVR training. By implementing HA-DW, developers can ensure their reasoning models are learning from the right signals, leading to smarter, more capable AI.