Apple’s Cynical Take on Large Reasoning Models Reveals Deep Flaws in AI’s Thinking Process
- Apple’s AI researchers have taken a critical stance on Large Reasoning Models (LRMs), publishing papers that highlight their inability to generalize beyond certain complexity thresholds.
- Through controlled puzzle environments, studies reveal LRMs’ strengths at moderate complexity but expose complete performance collapses at high complexity and surprising inefficiencies at low complexity.
- Apple’s own AI offerings, like Siri and Apple Intelligence, lag behind competitors, raising questions about whether their critical research reflects broader industry challenges or internal shortcomings.
Artificial intelligence has long promised to mimic human reasoning, with the latest frontier being Large Reasoning Models (LRMs)—systems designed to generate detailed thought processes before delivering answers. These models, built on the backbone of large language models (LLMs), have shown impressive gains on reasoning benchmarks, fueling optimism about AI’s potential to solve complex problems. However, Apple’s AI researchers have emerged as vocal skeptics, publishing a series of papers that challenge the hype surrounding LRMs. Their work, including the recent study titled “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity,” argues that these models face fundamental barriers to true, generalizable reasoning. This article dives into Apple’s critical perspective, explores the broader implications of their findings, and examines whether their cynicism reflects deeper issues in AI development—including their own underwhelming AI products like Siri and Apple Intelligence.
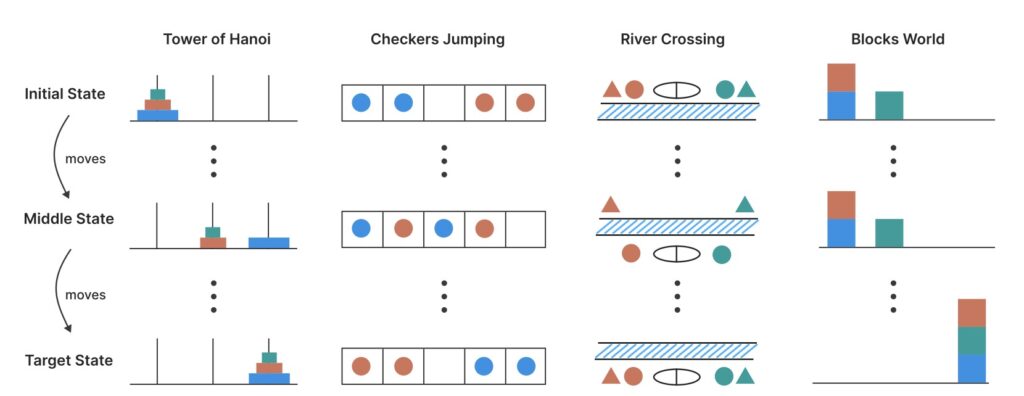
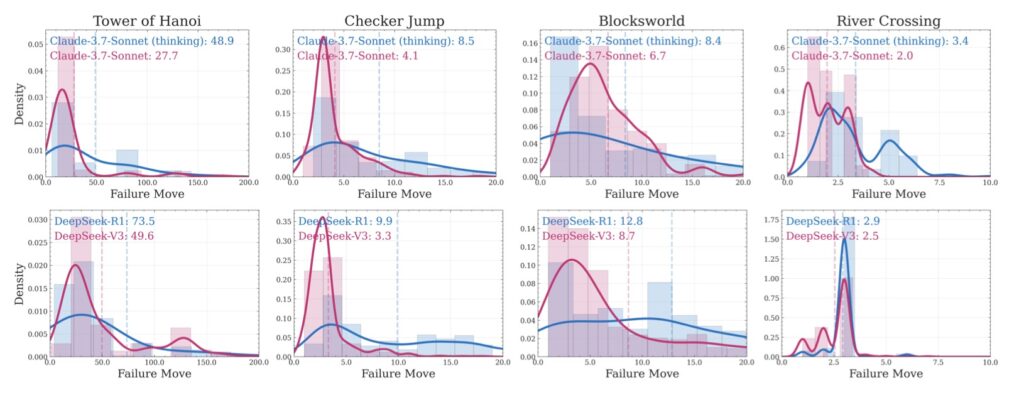
Apple’s researchers have taken a unique approach to dissecting LRMs by using controllable puzzle environments, such as the Tower of Hanoi and River Crossing puzzles, to manipulate compositional complexity while maintaining consistent logical structures. This method allows for a granular analysis of not just the final answers but also the internal reasoning traces—essentially, how these models “think.” Their findings are striking: while LRMs can outperform standard LLMs on tasks of moderate complexity, they collapse entirely when faced with high-complexity problems. Even more surprising, at low-complexity tasks, standard LLMs often outshine their reasoning-focused counterparts, suggesting that the additional “thinking” mechanisms in LRMs can sometimes be a hindrance rather than a help. This paints a picture of AI systems that are not as robust as their benchmarks suggest, raising doubts about their scalability and real-world applicability.
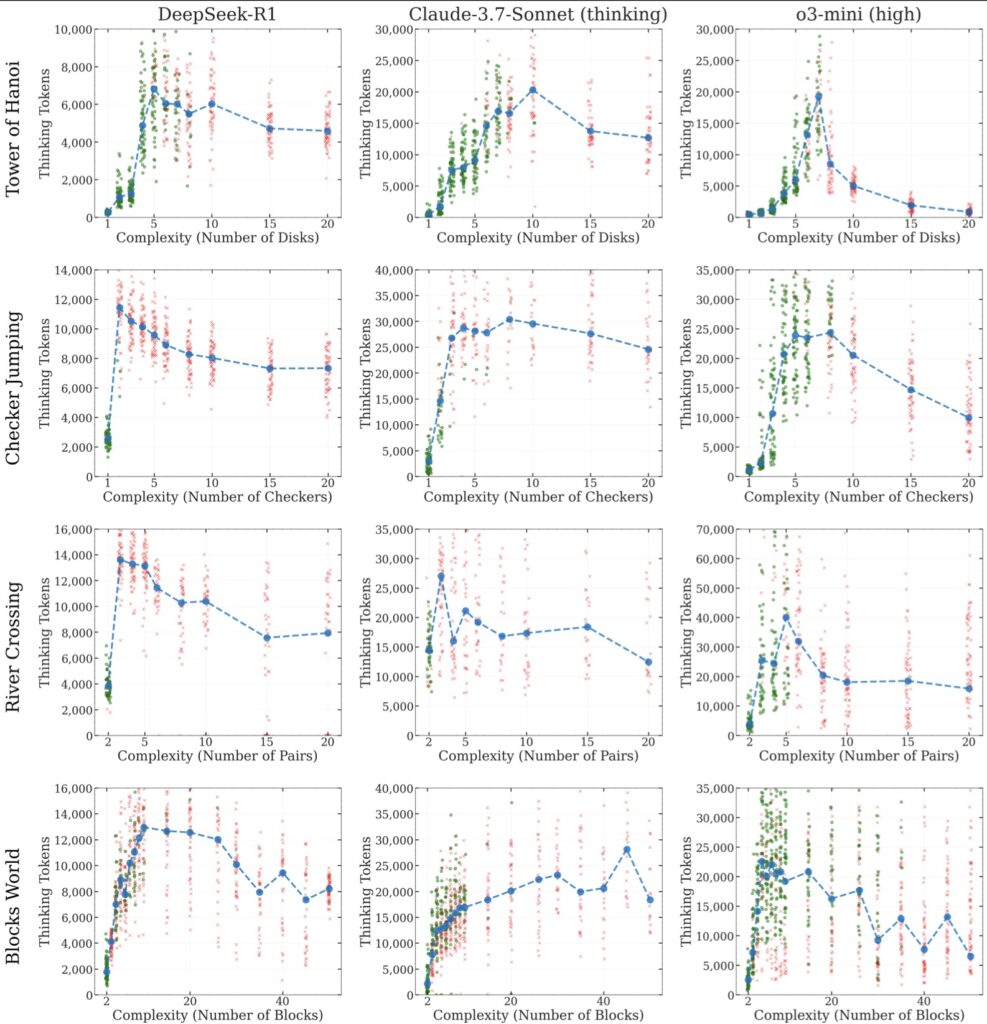
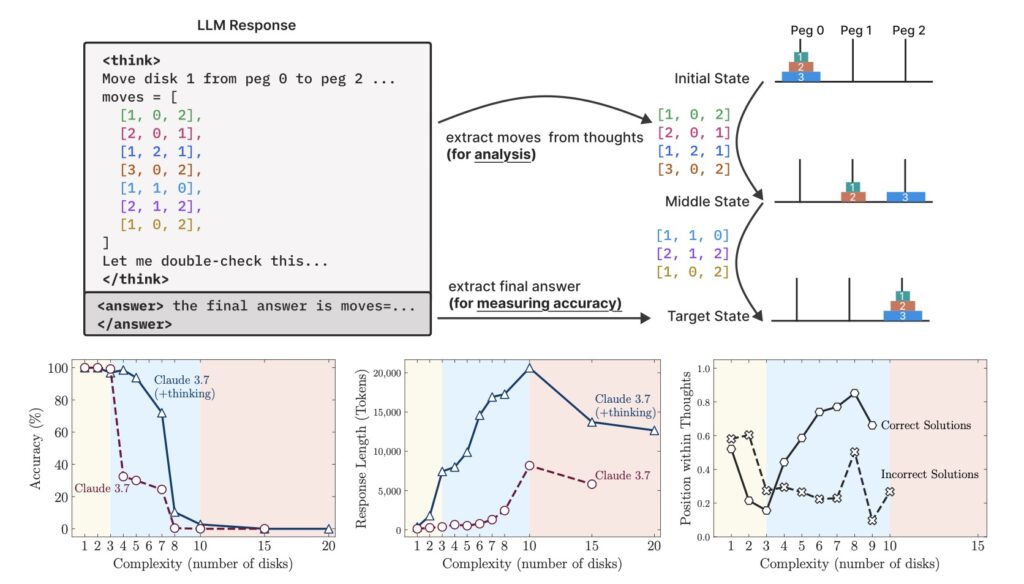
One of the most intriguing revelations from Apple’s study is the counterintuitive scaling limit in LRMs. As problem complexity increases, the models initially ramp up their reasoning effort, generating longer and more detailed thought processes. However, beyond a certain threshold, their effort inexplicably declines, even when they have ample computational resources (or token budgets) to continue. This suggests an inherent limitation in how these models allocate compute power, hinting at deeper architectural flaws. The researchers also noted that LRMs struggle with exact computation, failing to leverage explicit algorithms even when provided with them. For instance, when given the solution algorithm for the Tower of Hanoi, the models showed no improvement in performance. This inability to consistently apply logical rules across different puzzles—evidenced by their ability to make 100 correct moves in Tower of Hanoi but only five in River Crossing—further underscores their lack of generalizable reasoning.
Delving deeper into the reasoning traces, Apple’s team identified distinct performance regimes based on problem complexity. At low complexity, LRMs tend to overthink, wasting computational effort on problems that standard LLMs solve more efficiently. At moderate complexity, the additional reasoning steps in LRMs provide a clear advantage, aligning with the improvements seen in benchmarks. However, at high complexity, both LRMs and standard LLMs experience a total accuracy collapse, unable to navigate the intricate demands of the tasks. These patterns reveal a troubling inconsistency in how LRMs approach problem-solving, oscillating between inefficient overthinking and complete failure depending on the context. Such findings challenge the prevailing narrative that more sophisticated self-reflection mechanisms will inevitably lead to better reasoning capabilities.
Apple’s critical stance on LRMs also invites scrutiny of their own AI ecosystem. Despite their rigorous research, products like Siri and Apple Intelligence are widely regarded as lagging behind competitors such as Google Assistant or OpenAI’s offerings. Siri, in particular, has been criticized for its limited understanding and clunky user experience, while Apple Intelligence—Apple’s broader AI initiative—has yet to make a significant impact. This raises an important question: is Apple’s skepticism toward LRMs a reflection of broader industry challenges, or does it stem from their own struggles to innovate in this space? Their research may be a way to deflect attention from internal shortcomings, positioning them as thought leaders in identifying AI’s limitations rather than pioneers in overcoming them.
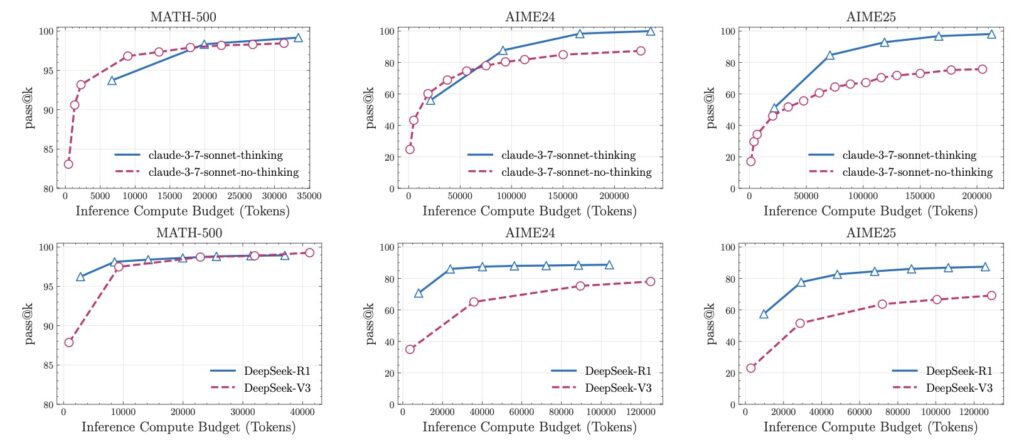
The implications of Apple’s findings extend far beyond their own products, casting a shadow over the AI industry’s rush to develop ever-larger reasoning models. If LRMs indeed face fundamental barriers to generalizable reasoning, as the study suggests, then current approaches may need a radical rethink. The researchers themselves acknowledge that their work raises more questions than answers, particularly around why LRMs fail at exact computation and why their reasoning effort diminishes at critical complexity thresholds. They call for future investigations into these anomalies, suggesting that understanding the computational behavior and reasoning patterns of LRMs could unlock new pathways for development—or reveal insurmountable limits.
Apple’s critique of Large Reasoning Models serves as a sobering reminder that AI, for all its advancements, remains far from achieving human-like reasoning. Their controlled experiments with puzzle environments have exposed critical weaknesses in how these models process complexity, challenging the assumption that more compute or more sophisticated mechanisms will inevitably lead to better outcomes. As the AI community grapples with these insights, the path forward may require not just technical innovation but a deeper philosophical reckoning with what “thinking” truly means for machines. For now, Apple’s research stands as both a warning and a call to action: the illusion of thought in AI is a powerful one, but illusions, by their nature, are not reality.