Exploring the connection between code in pretraining and the emergent abilities of large language models
Key Points:
- GPT-3.5 models, including ChatGPT, exhibit impressive capabilities, raising questions about the sources of these abilities.
- Code in pretraining might be a crucial factor, with the original Codex paper indicating 159GB of code in their final dataset.
- LLaMA pretraining shows only 4.5% from GitHub, highlighting the potential importance of code in developing emergent abilities.
- A comprehensive roadmap is proposed to understand the evolution of GPT-3.5 and its capabilities.
- The RedPajama project aims to create leading, fully open-source large language models, but its initial dataset may lack sufficient code.
The GPT-3.5 series, including OpenAI’s ChatGPT, has been a game-changer in the field of natural language processing, boasting a wide range of capabilities. Researchers are now keen to understand how these abilities emerged and the role of code in pretraining large language models (LLMs) such as LLaMA.
A recent document by @Francis_YAO_ discusses the improvement of GPT-3 models due to the code seen during training. The initial GPT-3 model gains its generation ability, world knowledge, and in-context learning from pretraining. However, it’s the code used in training that might be the secret ingredient for GPT-3.5’s remarkable capabilities.
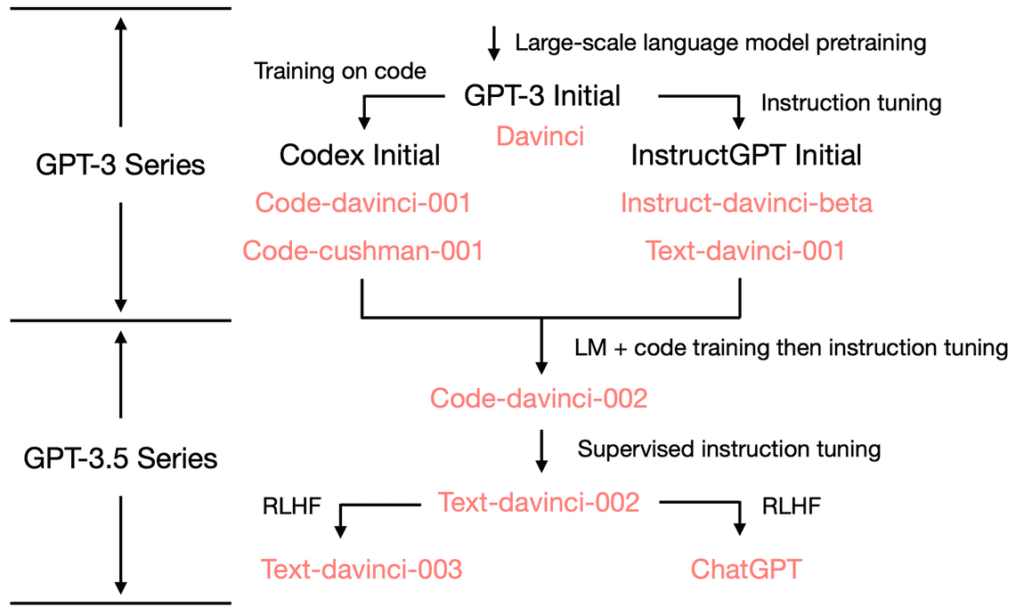
LLaMA pretraining shows only 4.5% of its dataset sourced from GitHub, which is significantly less than the 159GB of code used in the original Codex model. This difference might be a crucial factor in the emergent abilities of LLMs.
The RedPajama project, which aims to create leading, fully open-source LLMs, has released a 1.2 trillion token dataset following the LLaMA recipe. However, the dataset seems to have an even smaller portion of GitHub code than LLaMA, which may impact its performance.
The impact of code in pretraining LLMs, such as GPT-3.5, highlights the importance of considering code and instruction tuning when developing advanced models. Understanding the role of code can pave the way for even more impressive language models in the future.