Multilinguality, Coding, Reasoning, and Tool Usage in a New Set of AI Foundation Models
- Llama 3’s Capabilities: The Llama 3 models support multilinguality, coding, reasoning, and tool usage, with the largest model boasting 405 billion parameters and a context window of up to 128K tokens.
- Performance and Safety: Llama 3 delivers quality comparable to leading language models like GPT-4 and includes Llama Guard 3 for input and output safety.
- Multimodal Integration: Preliminary experiments show competitive performance in integrating image, video, and speech capabilities, although these models are still in development.

Meta has introduced the Llama 3 Herd of Models, a new set of foundation models designed to elevate AI capabilities in language, coding, reasoning, and tool usage. These models represent a significant advancement in AI technology, offering a robust framework for a variety of applications.
Llama 3’s Advanced Capabilities
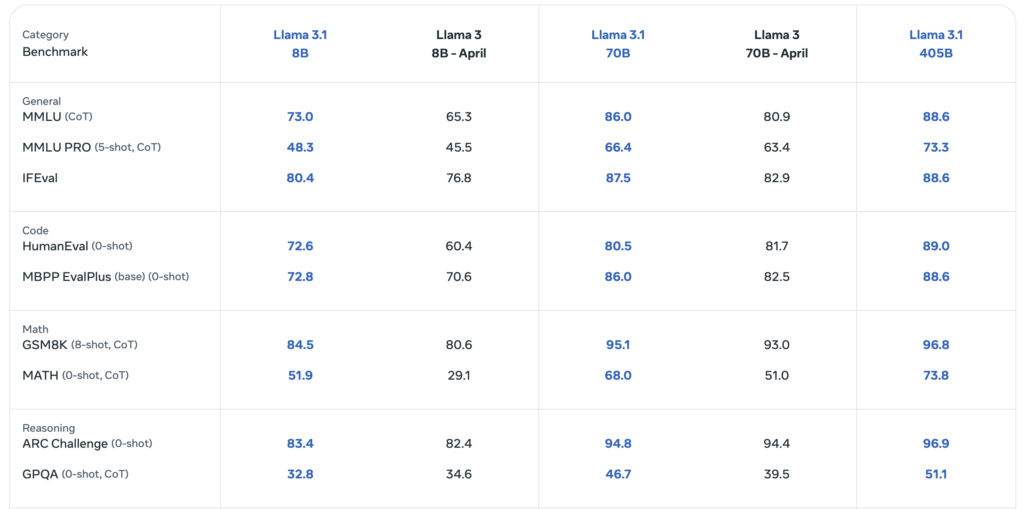
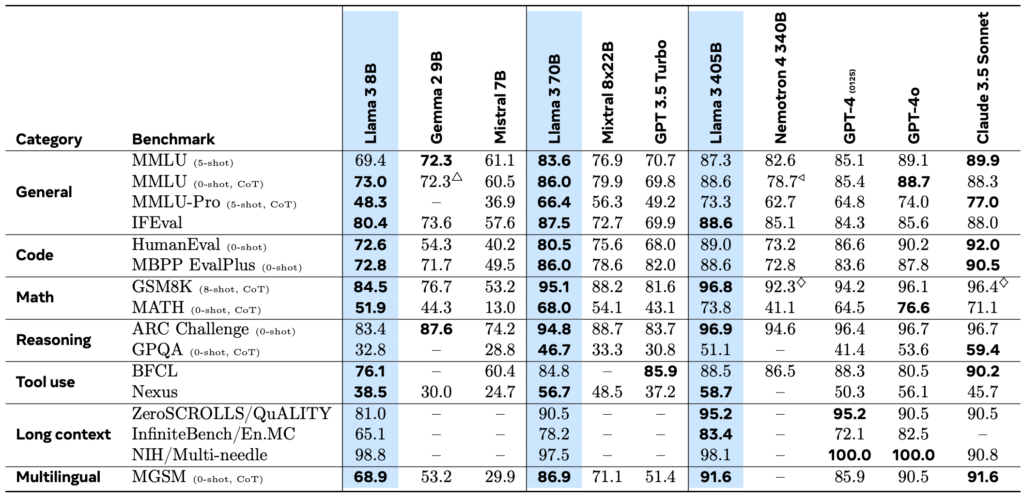
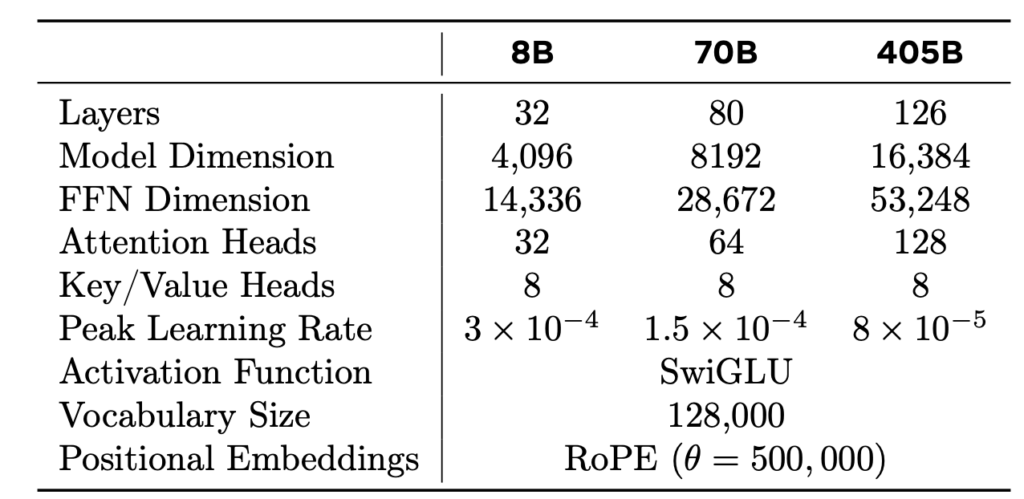
The Llama 3 models are built to handle diverse tasks, thanks to their extensive training and vast parameter count. The largest model in the series, a dense Transformer with 405 billion parameters, can process information in a context window of up to 128K tokens. This makes Llama 3 one of the most powerful language models available, rivaling the capabilities of other leading models like GPT-4.

Llama 3’s multilingual support and advanced coding and reasoning abilities make it a versatile tool for developers and researchers. It has been empirically evaluated and found to perform on par with the best models currently available, ensuring it can handle a wide array of tasks with precision.
Ensuring Safety and Performance
Safety and performance are critical aspects of the Llama 3 development process. The Llama Guard 3 model ensures that input and output are secure, maintaining the integrity of interactions with the model. This focus on safety is crucial for applications that require high levels of trust and reliability.
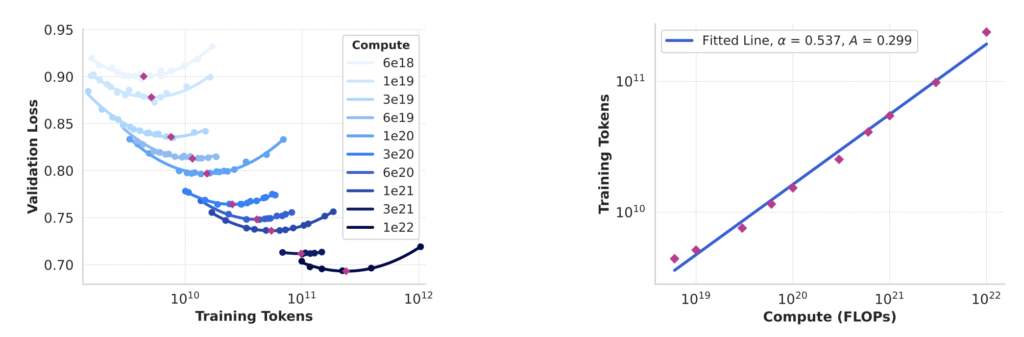
Moreover, the Llama 3 models have undergone extensive testing to prevent overfitting on commonly used benchmarks. This was achieved through careful data procurement and processing by a dedicated team, ensuring the models’ robustness and generalizability.
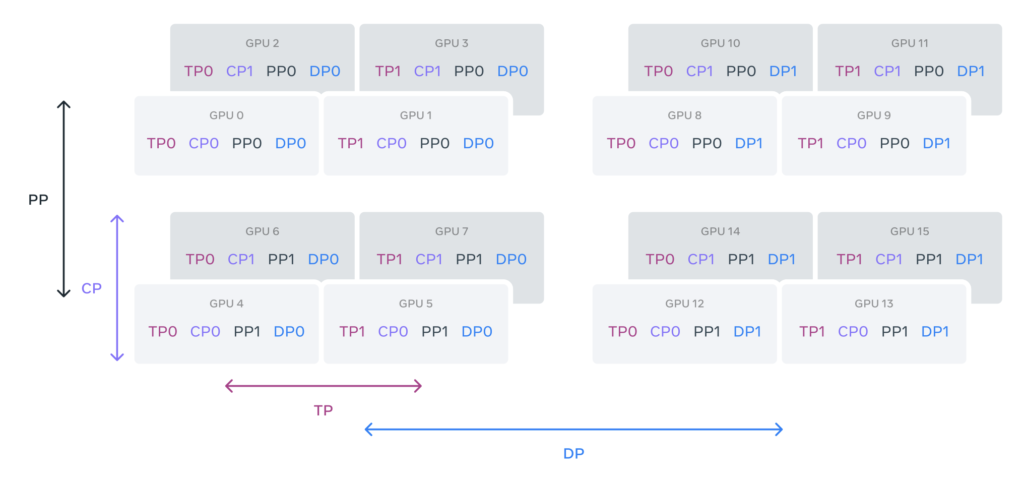
Integration of Multimodal Capabilities
In addition to its linguistic prowess, Llama 3 is being tested for its ability to integrate image, video, and speech capabilities. These preliminary experiments have shown that Llama 3 performs competitively with state-of-the-art models in these areas. Although these multimodal features are still under development, they hold promise for expanding the range of applications for Llama 3, from enhanced video editing to sophisticated speech recognition.
Development and Future Directions
The creation of Llama 3 involved not only technical innovation but also strategic organizational decisions. For instance, human evaluations of the models were conducted by a separate team to ensure unbiased and trustworthy results. This level of detail in the development process highlights the commitment to producing a high-quality, reliable AI system.
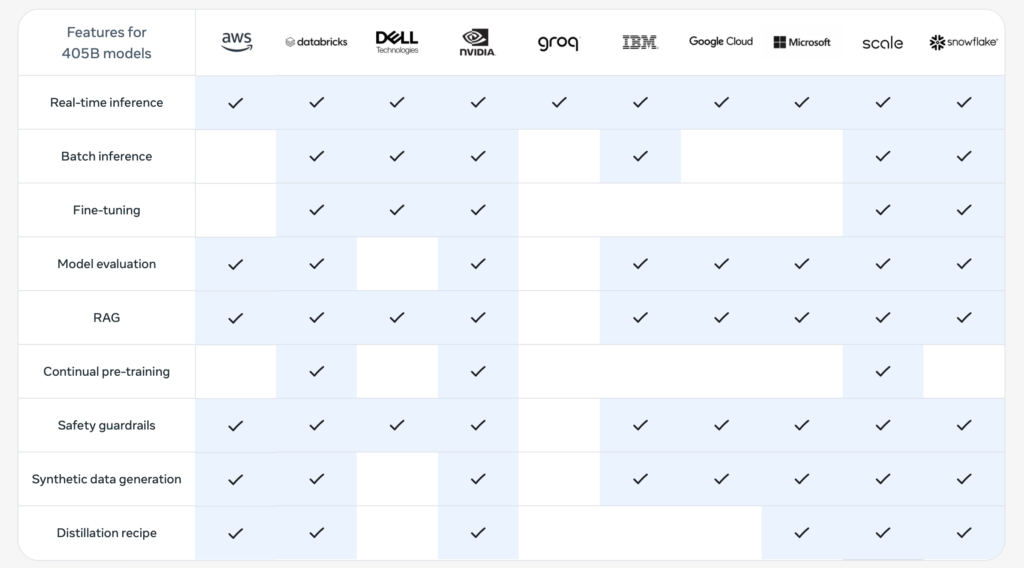
Looking ahead, the Llama 3 team plans to continue refining the models, especially in integrating multimodal capabilities. These ongoing efforts aim to push the boundaries of what AI can achieve, making it a more powerful tool for a wide range of applications.
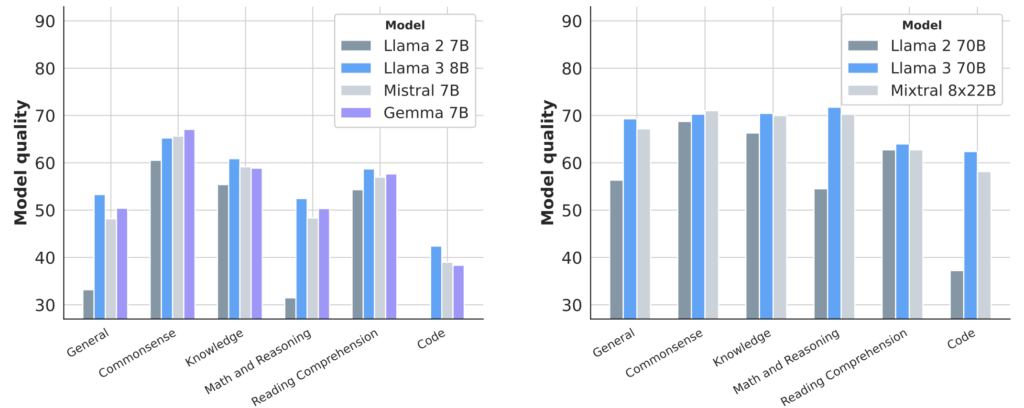
The release of Llama 3 marks a significant milestone in the development of foundation models. With its advanced capabilities in multilinguality, coding, reasoning, and tool usage, Llama 3 is poised to make a substantial impact across various fields. The integration of safety features and preliminary success in multimodal tasks further underscores its potential. By openly sharing the models and their development process, Meta is fostering a collaborative environment that encourages innovation and responsible AI development. The Llama 3 Herd of Models represents a step forward in creating more capable, secure, and versatile AI systems.