From “Vibe Coding” to Precision Production—How the Latest Frontier Model is Redefining Professional AI
- Massive Scale and Efficiency: GLM-5 jumps to 744B parameters (40B active) and 28.5T tokens, utilizing DeepSeek Sparse Attention (DSA) to deliver frontier-level intelligence with reduced deployment costs.
- Infrastructure Breakthroughs: The introduction of “slime,” a novel asynchronous reinforcement learning infrastructure, solves training throughput bottlenecks to bridge the gap between model competence and excellence.
- From Chat to Work: Moving beyond simple dialogue, GLM-5 is designed for long-horizon agentic tasks, capable of end-to-end document creation (.docx, .pdf, .xlsx) and complex systems engineering.
The landscape of Artificial General Intelligence (AGI) is shifting. We are moving away from the era of “vibe coding”—where models provided plausible-sounding but often fragile snippets of logic—and entering the era of Agentic Engineering. Leading this charge is GLM-5, a model specifically engineered for complex systems and long-horizon tasks that require more than just a quick chat; they require a deep, sustained cognitive “think mode.”
Scaling Intelligence and Efficiency
At the heart of GLM-5 lies a commitment to the belief that scaling is the most vital path toward AGI efficiency. The jump from its predecessor, GLM-4.5, is staggering. The model has grown from 355B parameters to a massive 744B parameters, with 40B active parameters ensuring that the model remains responsive and efficient. This physical growth is fueled by an expanded pre-training dataset of 28.5 trillion tokens.
To manage this scale without spiraling deployment costs, GLM-5 integrates DeepSeek Sparse Attention (DSA). This allows the model to maintain an expansive long-context capacity while significantly lowering the computational overhead usually associated with frontier-class models.
Mastering the Post-Training Gap
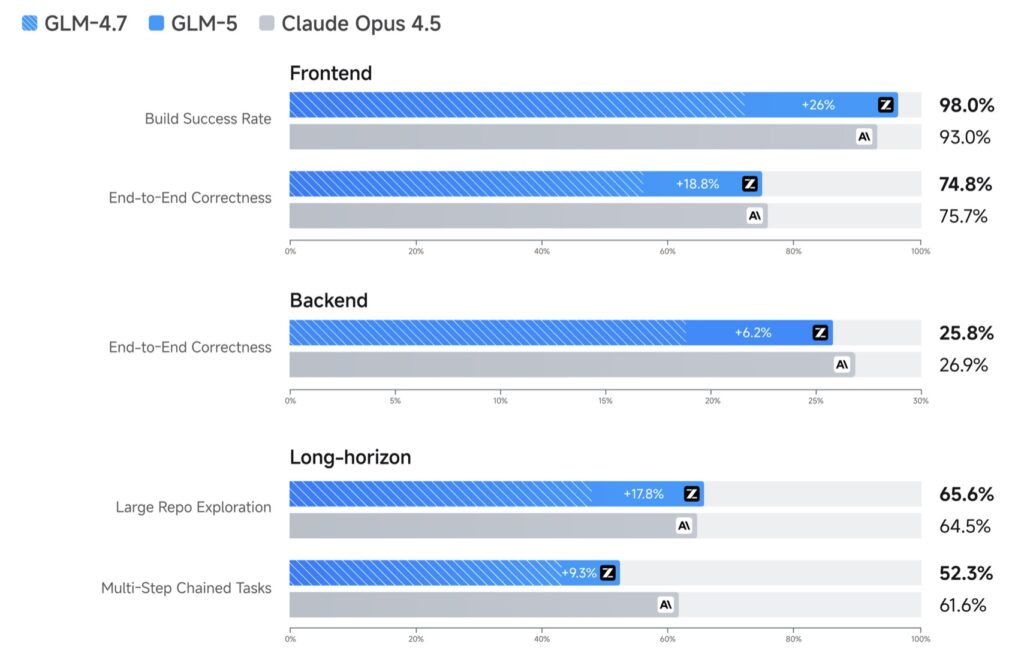
Pre-training creates competence, but reinforcement learning (RL) creates excellence. Historically, scaling RL for Large Language Models has been hindered by training inefficiencies. To solve this, the development team created “slime”—a novel, asynchronous RL infrastructure. By substantially improving training throughput, “slime” enables more fine-grained post-training iterations, allowing GLM-5 to achieve best-in-class performance among open-source models on reasoning, coding, and agentic benchmarks.
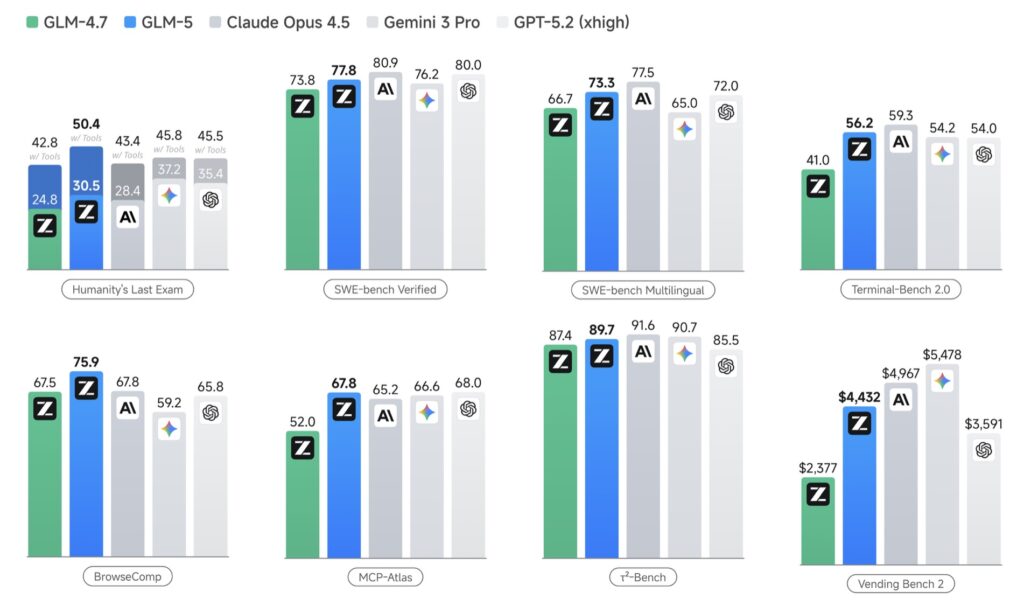
Benchmarking the Future
GLM-5 doesn’t just promise performance; it proves it across the most grueling evaluations in the industry. In Humanity’s Last Exam (HLE), the model was evaluated with a generation length of up to 131,072 tokens, proving its ability to maintain “trains of thought” over massive distances. In the SWE-bench and Terminal-Bench 2.0 suites, GLM-5 demonstrated its mastery of real-world software engineering, operating within 128K to 200K context windows to solve complex, multi-file bugs and terminal-based challenges.
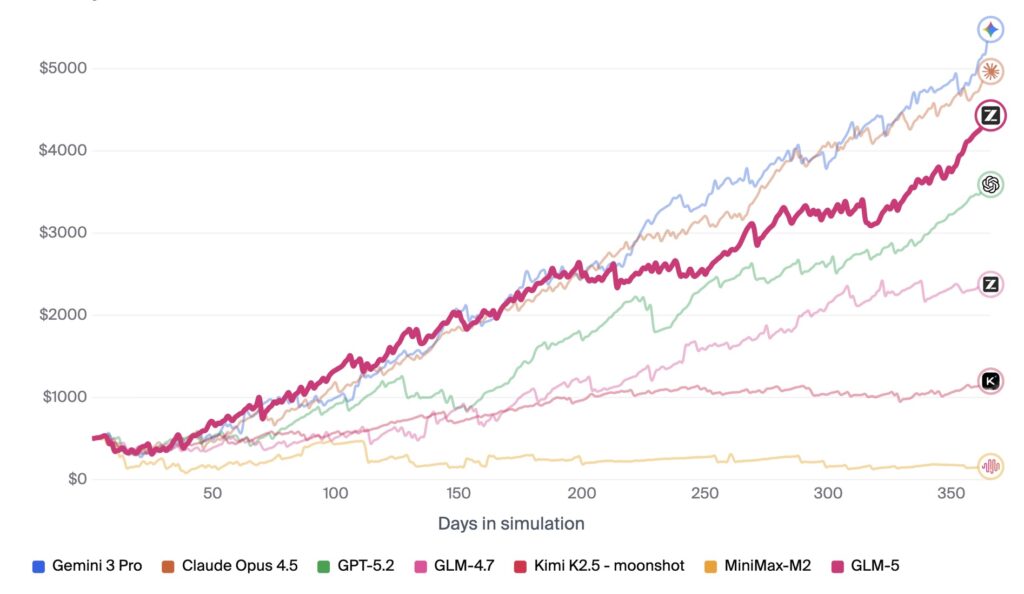
From CyberGym’s security tasks to MCP-Atlas’s tool-use evaluations, GLM-5 consistently closes the gap with the world’s most advanced closed-source models. It is no longer a “chatbot”; it is a digital colleague capable of navigating retail, telecom, and airline domains with high-precision fixes and adjusted logic.
Tangible Deliverables: Moving Beyond the Text Box
Perhaps the most exciting evolution is GLM-5’s transition from “chat” to “work.” Much like the transition from a typewriter to a modern Office suite, GLM-5 is built to deliver. It can transform raw source materials directly into professional-grade .docx, .pdf, and .xlsx files. Whether you need a Financial Report, a PRD, or a complex Spreadsheet, GLM-5 delivers these end-to-end as ready-to-use documents.
Through the official Z.ai application, users can access an Agent Mode that utilizes built-in skills for document creation and multi-turn collaboration. For developers, GLM-5 integrates seamlessly into existing coding agents like Claude Code, OpenHands, and Roo Code. For those needing a full-scale environment, Z Code offers an agentic development space where multiple agents can be controlled remotely to collaborate on the most demanding engineering projects.
Accessibility and Local Deployment
In a move toward true democratization, the model weights for GLM-5 are publicly available on HuggingFace and ModelScope. While it excels on NVIDIA hardware via vLLM and SGLang, the team has performed extensive kernel optimization to support non-NVIDIA chips, including Huawei Ascend, Moore Threads, and Kunlun Chip. This ensures that the power of 744B parameters is accessible regardless of the underlying silicon.
Whether used as a personal assistant through the OpenClaw framework or as the backbone of a corporate engineering pipeline, GLM-5 represents the next leap in AI: a model that doesn’t just talk about the work but does the work.