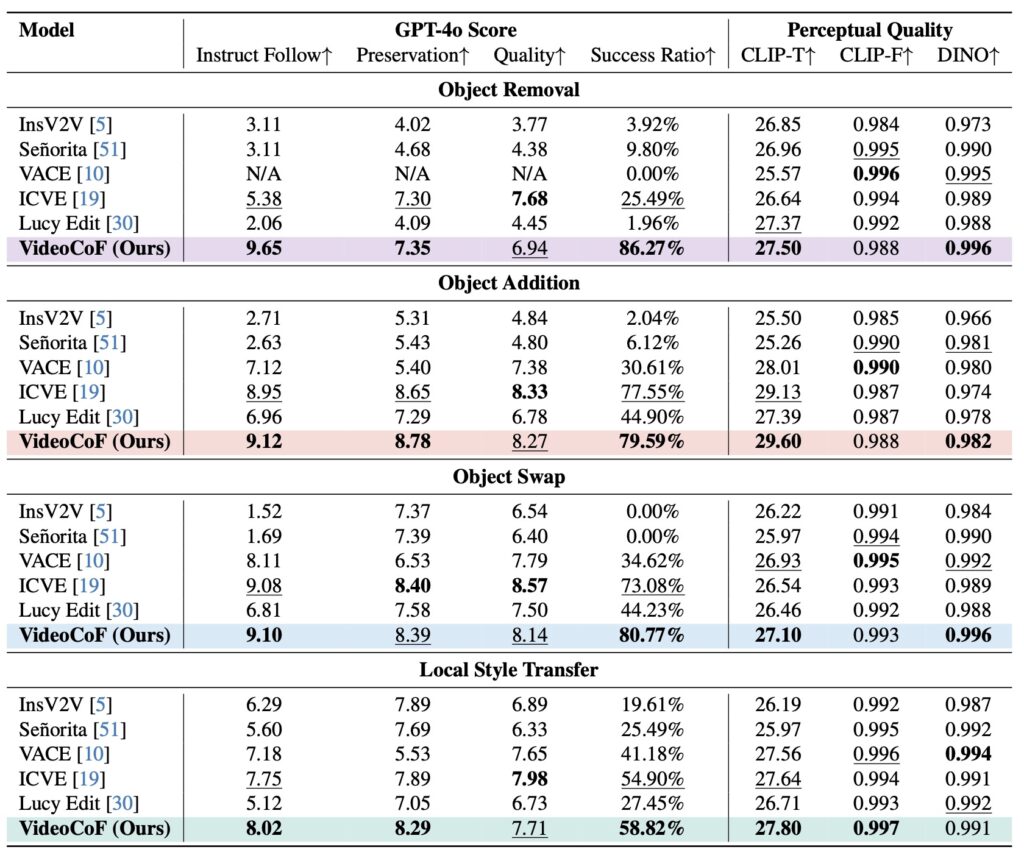
Bridging the gap between precision and flexibility with a novel “Chain-of-Frames” approach.
- The Precision Paradox: Current video editing AI faces a critical trade-off between expert models that require manual masking for precision and unified models that are easy to use but suffer from “spatial amnesia” and imprecise edits.
- The “See-Reason-Edit” Breakthrough: VideoCoF introduces a “Chain-of-Frames” mechanism that forces the AI to internally predict where to edit before it decides how to edit, eliminating the need for user-provided masks.
- Efficiency Meets Performance: By utilizing a specialized RoPE alignment strategy, the model achieves state-of-the-art performance and 4x length extrapolation using a training dataset of only 50,000 video pairs.

The landscape of artificial intelligence is currently witnessing a massive surge in video generation capabilities, yet a persistent bottleneck remains in the realm of video editing. Until now, researchers and developers have been stuck navigating a frustrating compromise. On one side of the spectrum lie “expert models.” These are precise tools that can execute specific tasks flawlessly, but they rely heavily on task-specific priors—specifically, user-provided masks. This reliance hinders unification, making the tools cumbersome and difficult to scale for general use.

On the other side are “unified temporal in-context learning models.” These are mask-free and more flexible, theoretically allowing for a broader range of edits. However, they lack explicit spatial cues. Without a clear understanding of “where” to look, these models often struggle with instruction-to-region mapping, leading to imprecise localization and edits that drift away from the user’s intent.
To resolve this conflict, researchers have introduced VideoCoF, a unified model for universal video editing that utilizes a Temporal Reasoner to bridge the gap between precision and flexibility.
The “Chain-of-Frames” Philosophy
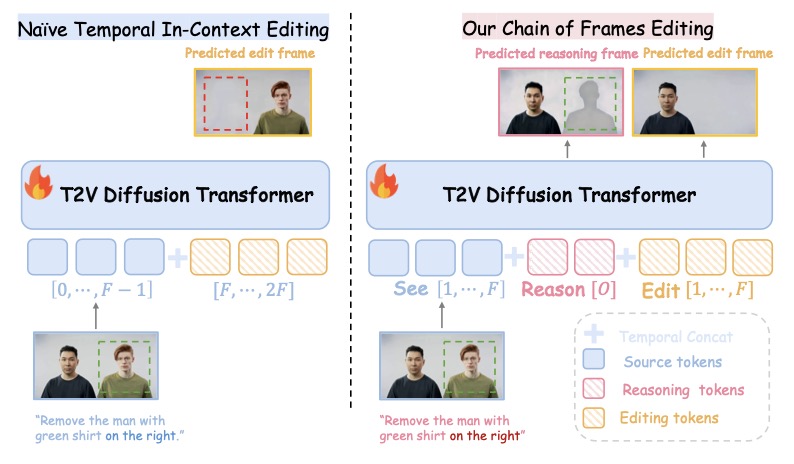
The core innovation behind VideoCoF is inspired by the “Chain-of-Thought” reasoning often seen in Large Language Models (LLMs). Just as an LLM performs better when it “thinks” through a problem step-by-step, a video model performs better when it reasons about space before generating pixels.
VideoCoF enforces a strict “see → reason → edit” procedure. Instead of jumping straight to generating the final video, the model is compelled to first predict “reasoning tokens”—essentially, the latents of the region that needs editing. Only after it has established where the change needs to happen does it generate the target video tokens.

This explicit reasoning step is a game-changer. It effectively removes the need for users to painstakingly draw masks over their footage. The AI generates its own internal understanding of the spatial constraints, achieving precise instruction-to-region alignment and fine-grained video editing that was previously the domain of mask-dependent expert models.

Mastering Time and Motion with RoPE
Spatial precision is only half the battle in video editing; the other half is temporal consistency. A common failure point in generative video is that the edit falls apart as the video gets longer. To address this, the VideoCoF team introduced a RoPE (Rotary Positional Embeddings) alignment strategy.
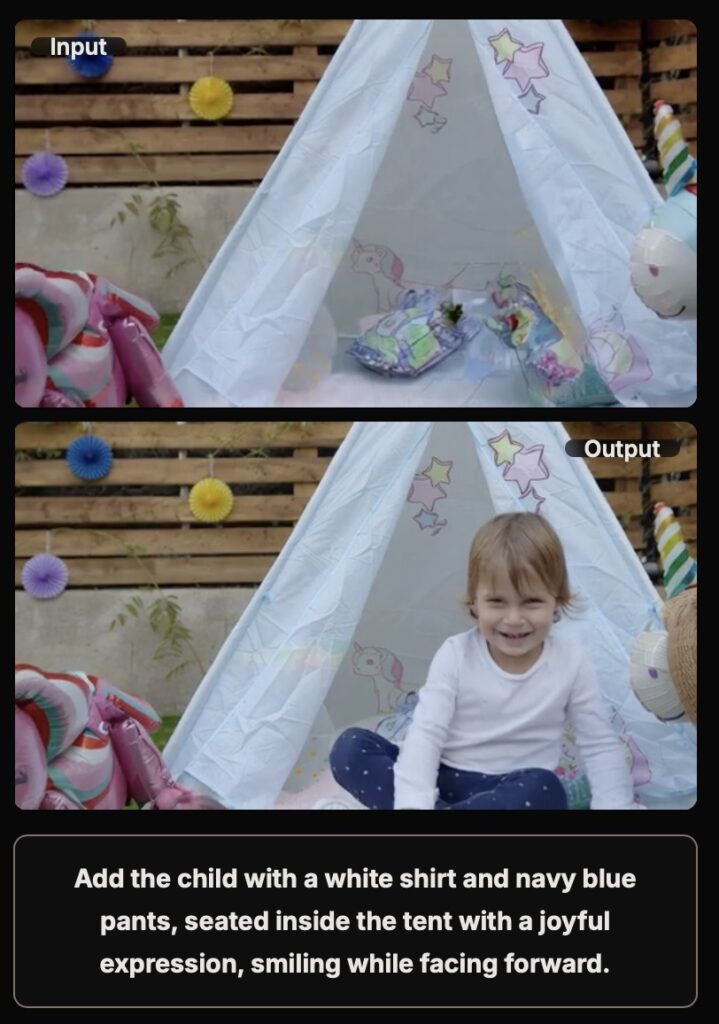
This paradigm leverages the reasoning tokens generated in the first step to ensure motion alignment throughout the clip. Crucially, this design enables length extrapolation. While many models degrade when asked to generate video beyond their training parameters, VideoCoF’s alignment strategy allows for 4 times exploration during inference. This means the model can generate coherent, edited video sequences that are significantly longer than the clips it was trained on.
Efficiency in Training
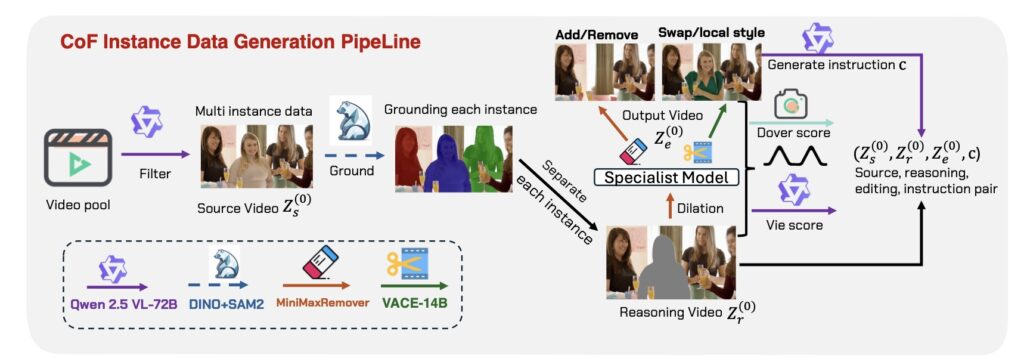
Perhaps the most surprising aspect of VideoCoF is its efficiency. In an era where AI advancements are often associated with massive datasets and exorbitant compute costs, VideoCoF demonstrates that smarter architecture beats brute force.

The model achieves State-of-the-Art (SOTA) performance on the VideoCoF-Bench benchmark with a minimal data cost of only 50,000 video pairs. This validates the effectiveness of the temporal reasoning design. By forcing the model to “reason” before it edits, VideoCoF not only solves the trade-off between precision and unification but does so with remarkable computational efficiency. This approach paves the way for the next generation of video editing tools—ones that are intuitive, precise, and capable of understanding the user’s intent without needing their hand held through the process.