Google’s New Suite of Sparse Autoencoders Enhances AI Safety and Research
- Gemma Scope introduces an open suite of Sparse Autoencoders (SAEs) designed to improve interpretability and safety in AI models.
- The SAEs are trained on multiple layers of Gemma 2 models, providing researchers with tools to better understand and debug neural networks.
- This initiative aims to address critical issues like AI hallucinations and model manipulation, fostering safer AI deployment.

In a significant advancement for AI research and safety, Google has unveiled Gemma Scope, an innovative suite of Sparse Autoencoders (SAEs) designed to enhance the interpretability of neural networks. By opening up these tools to the broader AI community, Google aims to facilitate groundbreaking research in AI safety, with a particular focus on making complex AI models more transparent and reliable.
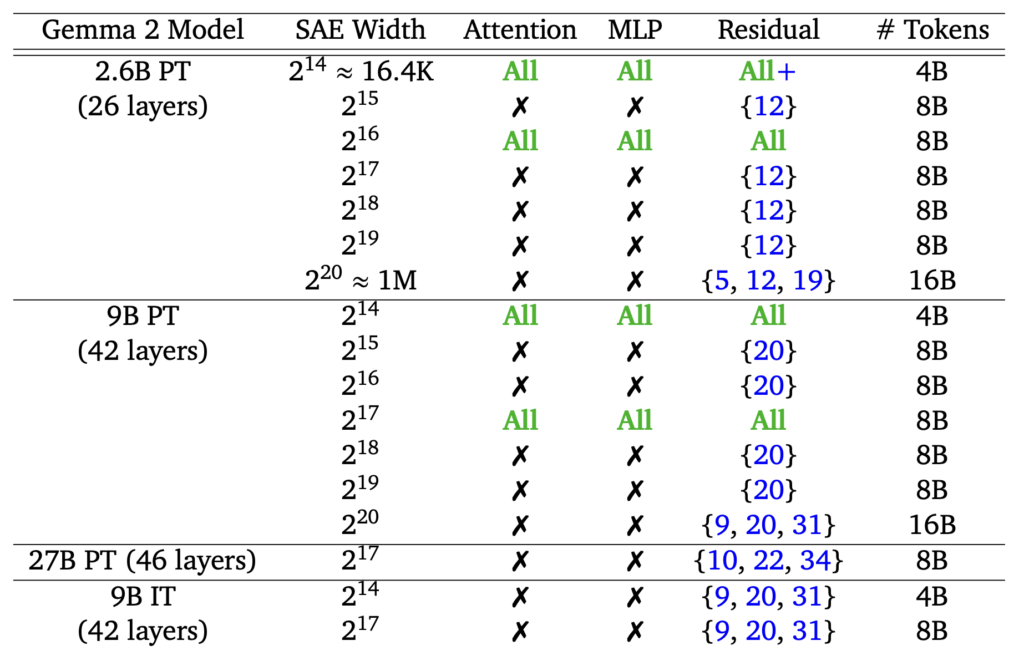
The Promise of Sparse Autoencoders
Sparse Autoencoders are a type of unsupervised learning model that excel at breaking down neural network activations into sparse, interpretable features. This ability to decompose complex neural network representations into simpler, more understandable components is a crucial step toward demystifying how AI models make decisions. With Gemma Scope, researchers can now access a comprehensive suite of SAEs trained on different layers of Google’s Gemma 2 models, including the base models with 2 billion, 9 billion, and even 27 billion parameters.
Advancing AI Safety and Interpretability
Gemma Scope’s SAEs hold the potential to tackle some of the most pressing challenges in AI safety. By providing a clearer understanding of the latent features within neural networks, these tools can help detect and correct issues such as AI hallucinations, where a model generates incorrect or misleading information. Additionally, they can be used to debug unexpected behaviors in AI systems, and even prevent potential manipulation or deception by autonomous AI agents.
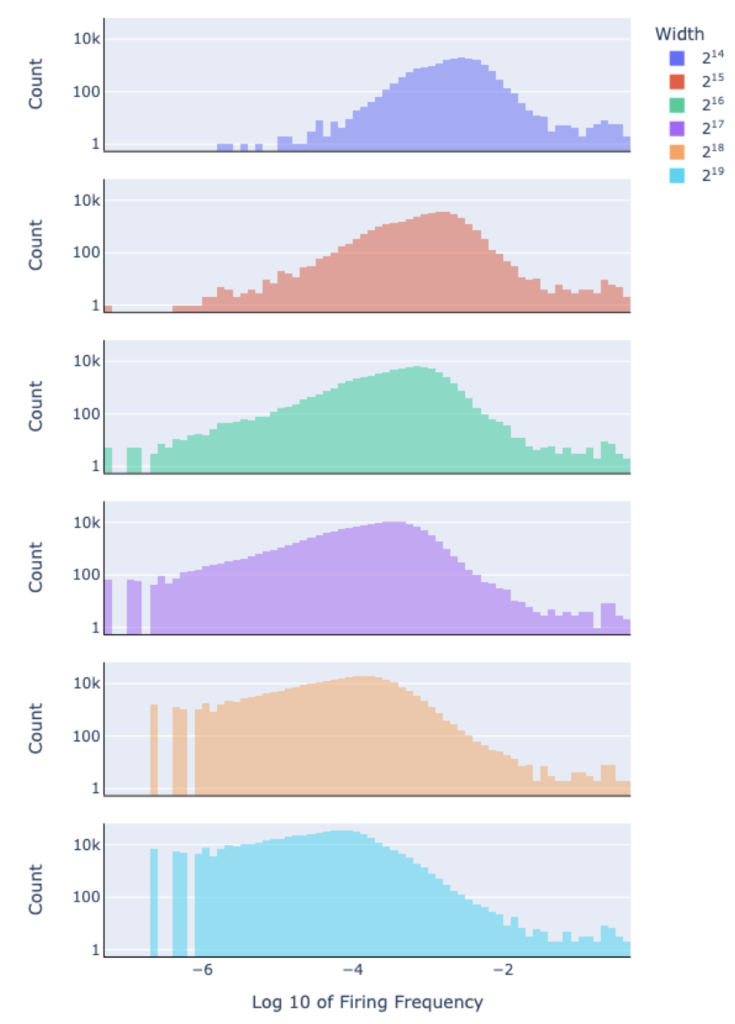
The suite also includes SAEs trained on both pre-trained (PT) and instruction-tuned (IT) versions of the Gemma 2 models, allowing for comparative analysis. This dual approach helps researchers explore how fine-tuning affects model interpretability and performance, offering insights that could lead to more robust and reliable AI systems.
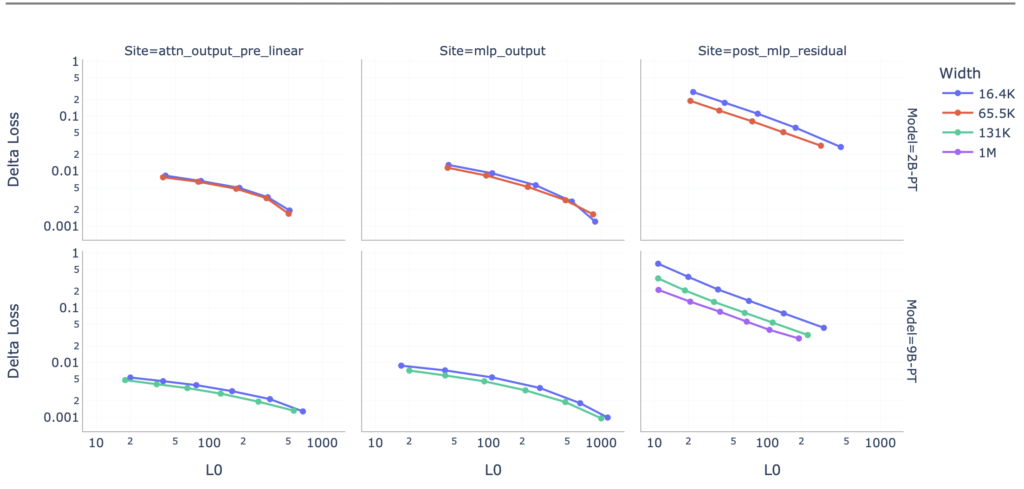
A Step Towards Safer AI
The introduction of Gemma Scope is not just about improving AI model transparency—it’s about making AI safer for broader use. By enabling the identification of meaningful features within models, researchers can better predict and mitigate risks associated with AI deployment. This is particularly important in applications like circuit analysis, where precision and reliability are paramount.
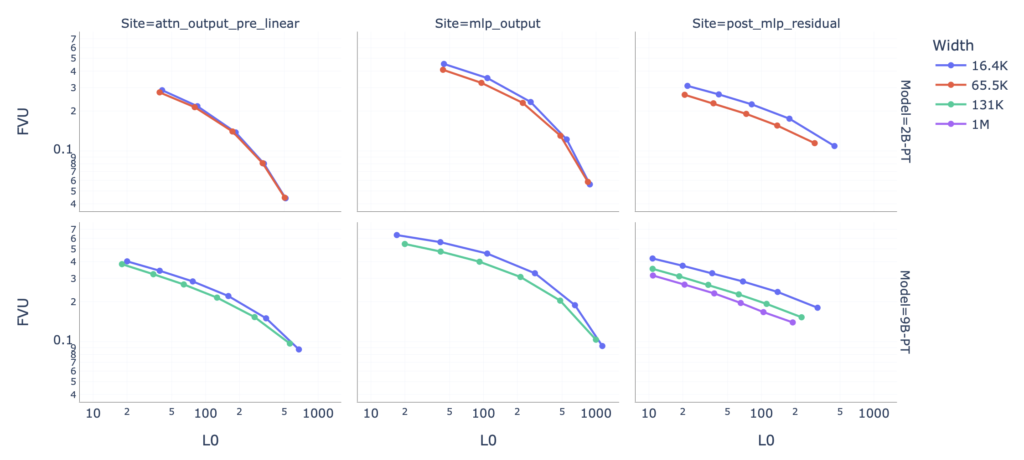
Google’s release of Gemma Scope represents a significant contribution to the AI community. By making these advanced tools available, the company is empowering researchers to push the boundaries of AI safety and interpretability. As AI continues to evolve, initiatives like Gemma Scope will play a crucial role in ensuring that these powerful technologies are developed and deployed responsibly.
{kind=link}