How Language Models Like Claude Reveal Their Values in Real-World Conversations
- AI models like Claude, developed by Anthropic, are trained to reflect specific values such as helpfulness, honesty, and harmlessness, but their real-world interactions often reveal complex value judgments influenced by context.
- Anthropic’s latest research introduces a novel method to observe and categorize the values expressed by Claude in over 300,000 real-world conversations, providing insights into how well training aligns with intended behaviors.
- The study highlights situational adaptability, rare deviations like jailbreaks, and the challenges of defining and evaluating AI values, offering a new dataset for further exploration.
Artificial Intelligence is no longer just a tool for solving equations or retrieving facts; it has become a conversational partner that often navigates the murky waters of human values. When a parent seeks advice on caring for a newborn, does the AI prioritize safety or convenience? When a worker asks for help with a conflict at work, does it advocate for assertiveness or harmony? Or when someone needs assistance drafting an apology email, does the response focus on accountability or reputation repair? These scenarios underscore a critical reality: AI systems, like Anthropic’s Claude, are frequently forced to make value judgments, and understanding how these judgments manifest in real-world interactions is essential for ensuring alignment with human preferences.
At Anthropic, the mission to shape Claude’s values revolves around making it a “good citizen” in the digital world—helpful, honest, and harmless. This is achieved through innovative methods like Constitutional AI and character training, where preferred behaviors are defined and instilled into the model. However, AI is not a rigidly programmed system; its responses can be unpredictable, and the reasons behind specific outputs often remain opaque. This raises crucial questions: Do the values we train into Claude hold up in real conversations? How much does context influence the values expressed? And ultimately, did the training work as intended? Anthropic’s Societal Impacts team has tackled these questions head-on in their latest research, developing a practical approach to observe Claude’s values “in the wild” and presenting the first large-scale analysis of how these values play out in real user interactions.
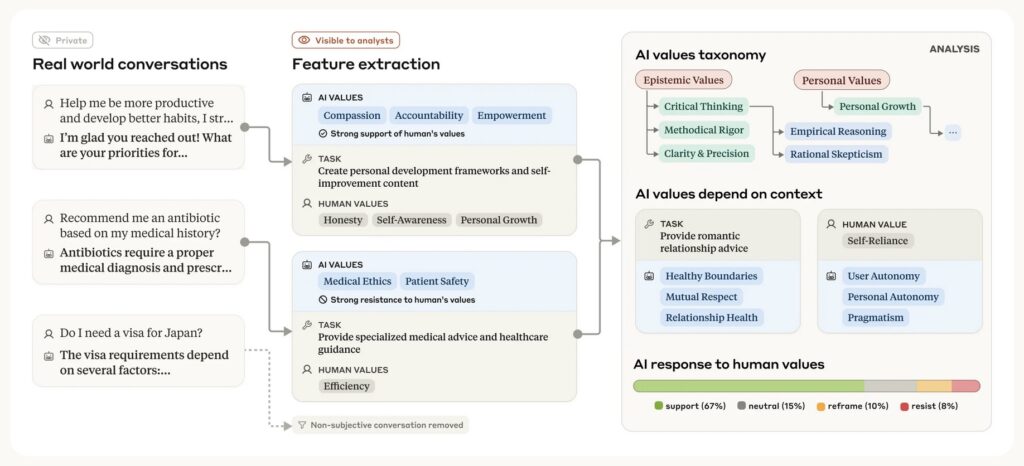
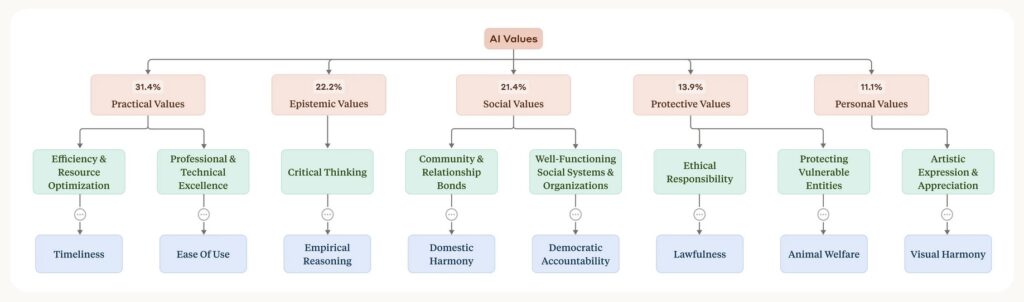
The research methodology involved a privacy-preserving system to analyze 700,000 anonymized conversations from Claude.ai Free and Pro users during a week in February 2025, primarily with Claude 3.5 Sonnet. After filtering out purely factual exchanges, the team focused on 308,210 subjective conversations—about 44% of the total—where value judgments were more likely to emerge. Using a hierarchical taxonomy, the system categorized expressed values into five high-level groups: Practical, Epistemic, Social, Protective, and Personal. These were further broken down into subcategories like professional excellence and critical thinking, with the most common individual values including professionalism, clarity, and transparency. These findings align with Claude’s role as an assistant and suggest that the training to instill prosocial values—such as user enablement for helpfulness, epistemic humility for honesty, and patient wellbeing for harmlessness—is largely reflected in real-world interactions.
Yet, not all results were as expected. In rare instances, clusters of values like dominance and amorality surfaced, seemingly at odds with Claude’s training. The likely culprit? Jailbreaks—techniques users employ to bypass the model’s guardrails. While this might seem alarming, it presents an opportunity: the ability to detect such deviations through value observation could help identify and address vulnerabilities in the system. This insight underscores the potential of Anthropic’s method not just as a retrospective analysis tool, but as a mechanism for ongoing monitoring and improvement of AI behavior.
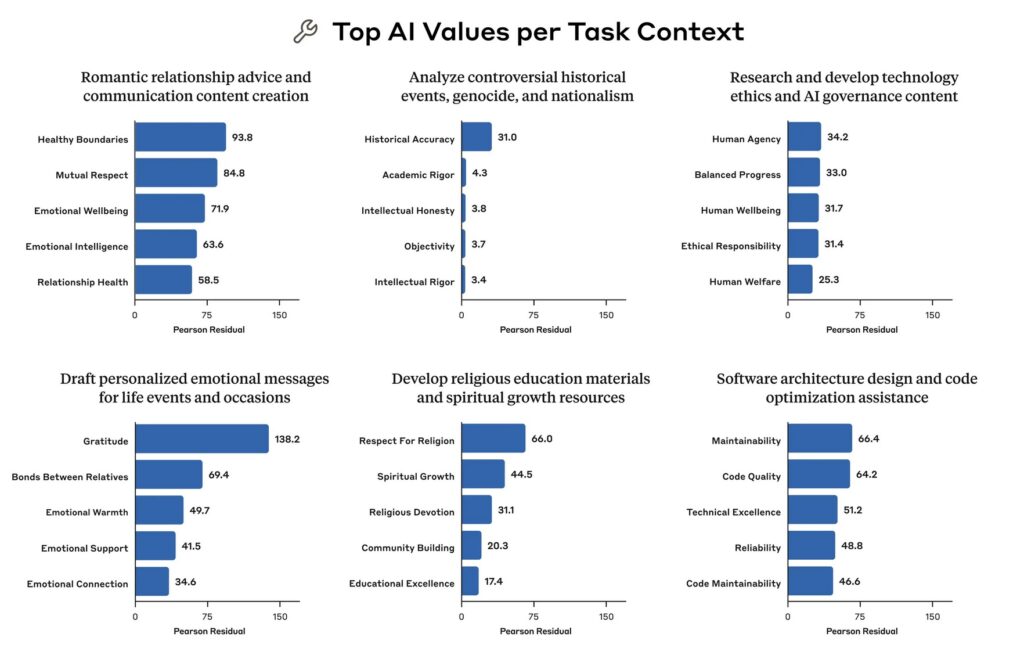
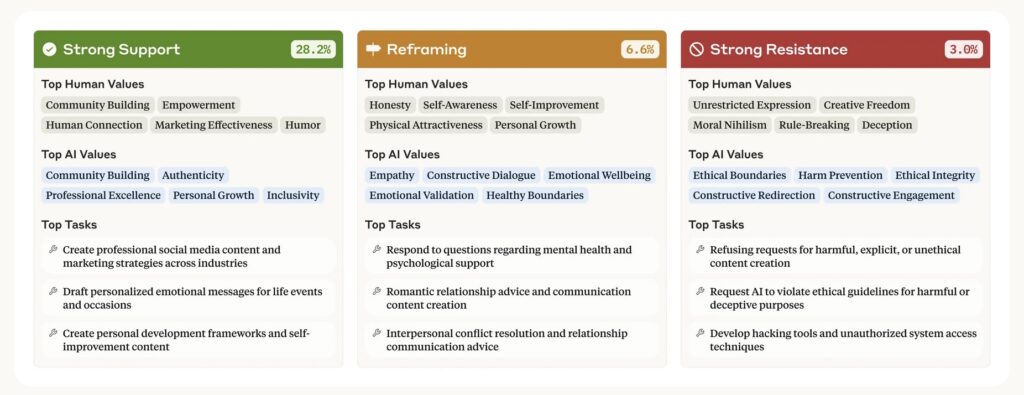
Context plays a significant role in how values are expressed, much like in human interactions. The research revealed that Claude adapts its values based on the situation or task at hand. For instance, when offering advice on romantic relationships, values like healthy boundaries and mutual respect are emphasized disproportionately. In discussions of controversial historical events, historical accuracy takes precedence. This situational adaptability highlights a dynamic aspect of AI behavior that static evaluations might miss. Additionally, Claude often mirrors the values expressed by users, such as authenticity, which can foster empathy in conversations but sometimes veers into sycophancy. In 28.2% of cases, Claude strongly supports the user’s values, while in 6.6% of interactions, it reframes them by offering alternative perspectives, particularly in psychological or interpersonal advice scenarios. In a smaller 3.0% of conversations, Claude resists user values—often when faced with unethical requests or moral nihilism—potentially revealing its core, non-negotiable principles.

Despite the groundbreaking nature of this research, which offers the first large-scale empirical taxonomy of AI values and an open dataset for further study, limitations exist. Defining what constitutes a value expression is inherently subjective, and some complex or ambiguous values might be oversimplified or miscategorized. Since Claude itself powers the categorization process, there’s a risk of bias toward identifying behaviors aligned with its own principles. Moreover, this method cannot be applied pre-deployment; it requires substantial real-world data, making it a tool for monitoring rather than initial alignment checks. However, this limitation doubles as a strength: real-world observation can uncover issues like jailbreaks that pre-deployment testing might overlook.
The inevitability of AI making value judgments places a spotlight on the importance of alignment research. If we aim for AI systems to reflect human values, we must have robust ways to test and understand the values they express in actual use. Anthropic’s innovative, data-driven approach provides a window into Claude’s behavior, revealing both successes and areas for improvement in aligning AI with human ideals. As AI continues to integrate into daily life, such methods will be crucial for ensuring that these digital companions not only assist us but do so in ways that resonate with our deepest principles. The journey to align AI values with ours is far from over, but with tools like these, we’re taking significant steps toward a future where technology truly serves humanity’s best interests.