A New Approach to Reducing Memory Consumption in Training Large Language Models
- VeLoRA introduces rank-1 sub-token projections to significantly reduce memory requirements during model training.
- The method allows for efficient fine-tuning and pre-training without performance degradation.
- VeLoRA outperforms current memory-efficient methods like QLoRA and GaLore on several benchmarks.
The emergence of large language models (LLMs) has revolutionized the field of natural language processing (NLP), enabling breakthroughs in tasks such as text generation, translation, and comprehension. Despite their impressive capabilities, training and fine-tuning these models demand extensive computational and memory resources, creating a significant bottleneck. VeLoRA, a novel framework introduced in recent research, proposes a solution to this challenge by employing memory-efficient training using rank-1 sub-token projections.
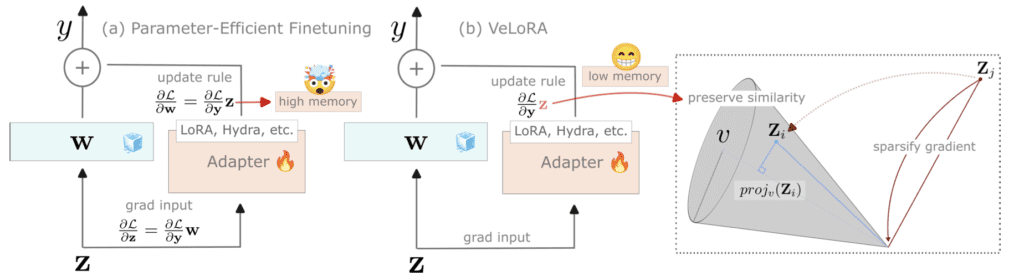
Understanding VeLoRA
VeLoRA (Memory Efficient Training using Rank-1 Sub-Token Projections) is designed to tackle the high memory consumption typically associated with training large language models. This innovative approach divides tokens into smaller sub-tokens and projects them onto a fixed one-dimensional subspace during the forward pass of the training process. These compressed features are then coarsely reconstructed during the backward pass, ensuring that the update rules for optimization are applied effectively.
How It Works
The core idea behind VeLoRA is the efficient compression and reconstruction of intermediate activations, which are crucial for implementing backpropagation in gradient descent. By compressing these activations, VeLoRA significantly reduces the memory footprint required for training, without compromising on model performance. This makes it possible to train larger models on existing hardware, leveraging their full potential.

Complementing Existing Techniques
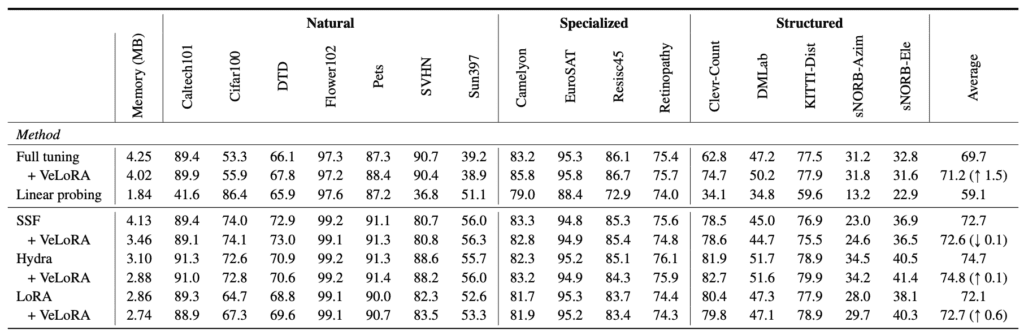
VeLoRA is complementary to many state-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods and demonstrates superior performance on benchmarks like VTAB-1k, MMLU, GLUE, and the large-scale C4 dataset. Compared to other memory-efficient techniques such as QLoRA and GaLore, VeLoRA shows improved efficiency and effectiveness, particularly in reducing GPU memory usage.
Experimental Validation
Extensive experiments validate the effectiveness of VeLoRA. The framework was tested on a variety of tasks and benchmarks, showcasing its ability to handle both moderately-sized vision transformers and large language models. The results indicate that VeLoRA not only meets but often exceeds the performance of existing methods while maintaining a lower memory footprint.
Limitations and Future Directions
Despite its advantages, VeLoRA primarily focuses on Transformer models, which are currently dominant in machine learning and computer vision. However, other important deep learning architectures, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), also play crucial roles in various applications. Future research could explore extending VeLoRA’s principles to these architectures to achieve similar memory efficiencies.
Another challenge is that while VeLoRA reduces memory usage significantly, it does not completely address the issue of training time, which remains a critical factor in the development and deployment of large language models. Continued advancements in hardware and algorithmic efficiency will be necessary to further mitigate these challenges.
VeLoRA represents a significant step forward in the field of large language model training, offering a practical solution to the memory limitations that have long hindered progress. By enabling more efficient use of existing hardware, VeLoRA paves the way for the continued growth and application of powerful language models, ensuring that they remain accessible and effective across a wide range of tasks and environments. This breakthrough has the potential to influence future research directions and set new standards for memory-efficient training in the field of machine learning.