Unlocking Versatile Control in Video Diffusion Models with TIC-FT
- Temporal In-Context Fine-Tuning (TIC-FT) introduces a groundbreaking, efficient method for adapting pretrained video diffusion models to diverse conditional generation tasks, requiring minimal data and no architectural changes.
- By concatenating condition and target frames along the temporal axis with noise-buffered intermediate frames, TIC-FT ensures smooth transitions and superior condition fidelity, outperforming traditional methods like ControlNet.
- Extensive experiments with large-scale models like CogVideoX-5B demonstrate TIC-FT’s exceptional performance in tasks such as image-to-video and video-to-video generation, even under low-data and low-compute conditions.

The world of video synthesis has seen remarkable strides in recent years, with text-to-video diffusion models reaching quality levels that rival professional productions. Yet, achieving precise control over video generation—tailoring outputs to specific conditions or styles—has remained a formidable challenge. Enter Temporal In-Context Fine-Tuning (TIC-FT), a novel approach that promises to redefine how we adapt pretrained video diffusion models for versatile, high-quality conditional generation. Unlike traditional methods that demand extensive datasets and complex architectural tweaks, TIC-FT offers an elegant, efficient solution that works with as few as 10 to 30 training samples, making controllable video creation more accessible than ever.
At its core, TIC-FT leverages a simple yet powerful idea: concatenating condition and target frames along the temporal axis while inserting intermediate buffer frames with progressively increasing noise levels. These buffer frames act as a bridge, facilitating smooth transitions between the condition input (like a single image or short video clip) and the desired output. This alignment with the pretrained model’s temporal dynamics ensures that the fine-tuning process doesn’t disrupt the model’s inherent capabilities. The result? Videos that not only look visually stunning but also adhere closely to the provided conditions, whether it’s transforming a static image into a dynamic motion sequence or converting a real video into an animated style.

Traditional fine-tuning approaches, such as ControlNet or IP-Adapter, often stumble due to their reliance on external encoders and rigid frameworks. These methods typically require large training datasets and are constrained to spatially aligned conditioning—meaning the input condition must match the target video’s length or be awkwardly replicated across frames. For instance, conditioning a video on a single image often involves duplicating that image across the temporal dimension, leading to inefficiencies and memory bloat. Moreover, these methods frequently lose fine-grained details during encoding, resulting in outputs that may look plausible but fail to capture the nuances of the input condition. TIC-FT sidesteps these issues entirely by working within the pretrained model’s existing architecture, eliminating the need for additional components or extensive retraining.



The inspiration for TIC-FT partly stems from in-context learning (ICL), a training-free paradigm that has shown immense success in large language models by using input examples to guide outputs. While ICL has been less explored in diffusion models for video generation, TIC-FT adapts its principles to create a unified framework for diverse tasks. Unlike concurrent approaches like in-context LoRA, which struggle with video models due to their poor suitability for grid-like outputs, TIC-FT is tailored for temporal dynamics. It avoids the pitfalls of training-free inpainting strategies that degrade performance and offers a flexible solution for mismatches between condition and target frame lengths, ensuring efficiency in both training and inference.
To put TIC-FT to the test, researchers conducted extensive experiments using large-scale base models like CogVideoX-5B and Wan-14B. The tasks ranged from image-to-video (I2V) generation—such as object-to-motion and character-to-video—to video-to-video (V2V) transformations like style transfer from real footage to animation. The results were striking. Even with limited training data (just 20 samples over 6,000 steps on a single NVIDIA H100 80GB GPU), TIC-FT outperformed established baselines in both condition fidelity and visual quality. Evaluation metrics, including VBench for temporal and spatial coherence, GPT-4o for aesthetic and semantic alignment, and perceptual similarity scores like CLIP-I and LPIPS, consistently highlighted TIC-FT’s edge. For instance, while methods like ControlNet scored well on visual plausibility, they faltered in aligning with the input condition, especially in tasks involving viewpoint shifts.

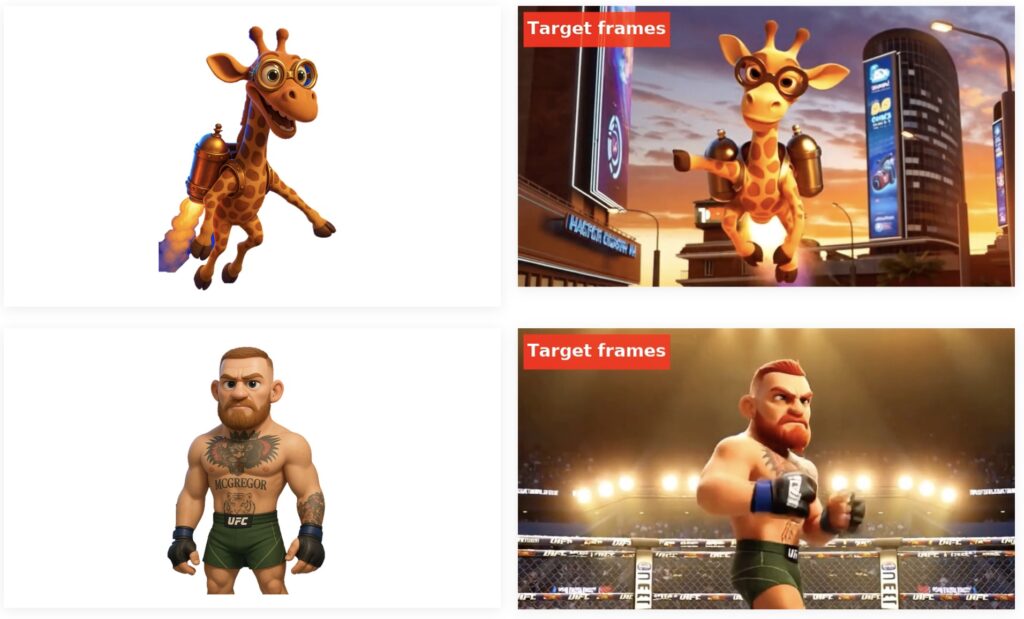
Qualitative comparisons further underscored TIC-FT’s prowess. Across diverse scenarios—virtual try-on, ad-video creation, and action transfer—the method produced outputs that not only looked better but also preserved the essence of the conditioning input. Zero-shot performance tests revealed another strength: even without additional training, TIC-FT generated plausible outputs by leveraging the pretrained capabilities of video diffusion models. Removing the buffer frames, however, led to abrupt discontinuities and degraded results, proving their critical role in maintaining smooth transitions and condition alignment.
What makes TIC-FT particularly exciting is its efficiency. Achieving competitive results after just 2,000 training steps, it outpaces other methods that require far more optimization to reach similar quality. This is a game-changer for creators and researchers operating under low-data or low-compute constraints. Imagine being able to fine-tune a video model for a specific style or action with just a handful of examples, without needing a supercomputer or months of data collection. TIC-FT brings that vision closer to reality, democratizing advanced video synthesis for a wider audience.

That said, TIC-FT isn’t without limitations. Currently, due to memory constraints, it’s restricted to condition inputs shorter than 10 seconds—a hurdle that future research aims to overcome. But even with this caveat, the method’s potential is undeniable. It offers a glimpse into a future where video generation isn’t just about creating content but crafting it with precision and intent, tailored to the creator’s vision with minimal effort. As the field of video diffusion continues to evolve, TIC-FT stands as a beacon of innovation, proving that sometimes the simplest ideas—concatenating frames with a touch of temporal finesse—can yield the most transformative results. So, whether you’re an artist dreaming up the next viral animation or a developer pushing the boundaries of AI, TIC-FT is a tool worth watching. What creative possibilities could it unlock for you?