Bridging Vision and Speech for Seamless Multimodal Communication
- Innovative Multimodal Model: VITA-1.5 integrates vision and speech through a novel multi-stage training methodology, addressing key challenges in multimodal interactions.
- Efficient Speech-to-Speech Interaction: The model enables real-time, end-to-end dialogue without the need for separate ASR and TTS modules, significantly boosting performance.
- Benchmark Success: VITA-1.5 demonstrates robust capabilities across vision and speech tasks, advancing the field of multimodal Large Language Models (MLLMs).

Recent advancements in Multimodal Large Language Models (MLLMs) have transformed how AI interacts with humans by integrating visual and textual data. Yet, the role of speech, a critical component in natural communication, has received less attention. Speech not only enhances the naturalness of interactions but also serves as a vital channel for information exchange. Despite its importance, integrating vision and speech into a unified model presents significant challenges due to inherent differences in these modalities.
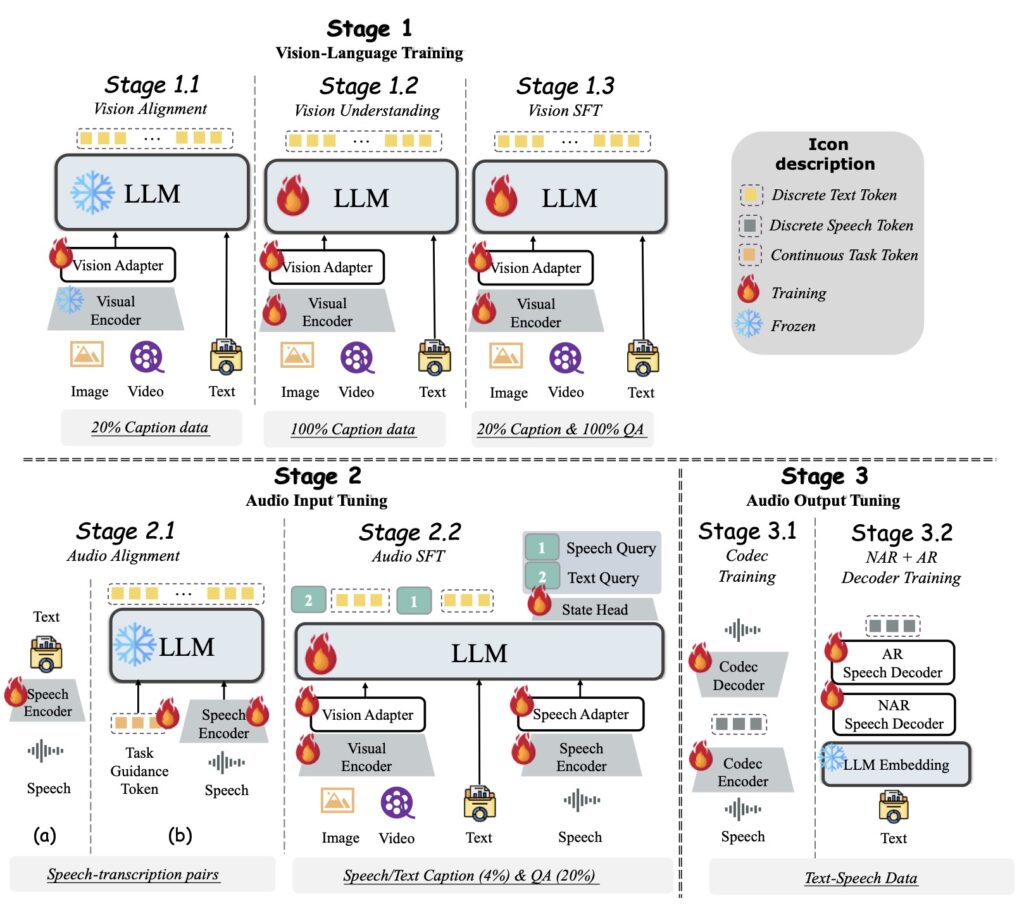
Enter VITA-1.5—a groundbreaking multimodal model designed to merge vision and speech seamlessly. By leveraging a novel three-stage training strategy, VITA-1.5 achieves robust capabilities in both modalities, enabling near real-time vision and speech interaction. This innovation not only builds on the legacy of its predecessor, VITA-1.0, but also sets a new benchmark for the field.
The Evolution of Multimodal Interaction
The integration of visual information into Large Language Models has led to remarkable progress in multimodal tasks. However, as human-computer interaction evolves, the need for incorporating speech alongside vision has become increasingly critical. Multimodal dialogue systems benefit greatly from speech, which enhances the convenience and natural flow of communication.
VITA-1.5 addresses this need by unifying vision and speech in a single model. Through its carefully designed training methodology, the model effectively overcomes conflicts between the two modalities, preserving strong vision-language capacity while introducing efficient speech-to-speech dialogue capabilities.
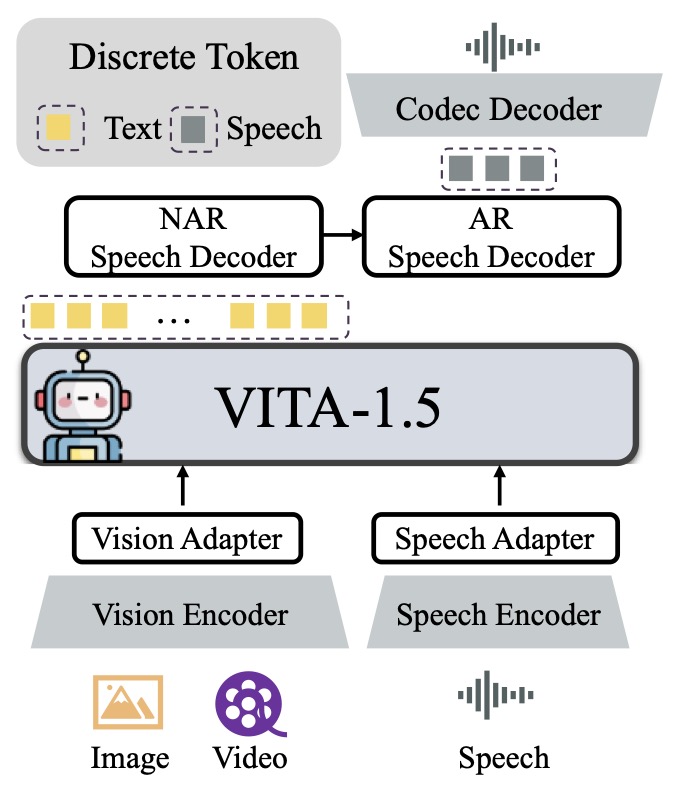
How VITA-1.5 Works
VITA-1.5 employs a multi-stage training strategy that progressively integrates visual and speech data. Unlike traditional approaches that rely on separate Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) modules, VITA-1.5’s architecture enables direct speech-to-speech interactions. This eliminates unnecessary processing layers, significantly accelerating response times.
By preserving robust vision-language understanding while enabling advanced speech capabilities, VITA-1.5 bridges the gap between modalities. Its streamlined design not only improves efficiency but also enhances the quality of multimodal interactions.
Benchmark Performance
VITA-1.5’s performance on multimodal benchmarks highlights its potential as a leader in the field. The model’s ability to handle image, video, and speech tasks demonstrates its versatility and effectiveness. By achieving competitive results across these domains, VITA-1.5 establishes itself as a powerful tool for real-time applications.
Moreover, the model’s open-source framework fosters collaboration and innovation, encouraging researchers to build upon its success. As the successor to VITA-1.0, VITA-1.5 paves the way for future advancements in real-time multimodal interaction.
VITA-1.5 represents a significant leap forward in the integration of vision and speech for multimodal communication. By addressing longstanding challenges and enabling efficient, real-time interactions, the model sets a new standard for MLLMs. Its innovative architecture, combined with robust performance across benchmarks, positions VITA-1.5 as a key player in the future of human-computer interaction.
As we look ahead, the potential applications of VITA-1.5 are vast, spanning fields from virtual assistants to accessibility technologies. By bridging vision and speech, this model brings us closer to seamless, intuitive multimodal communication.