AI-Driven Exploration with Interactive, Infinite Realities from a Single Image
- Innovative Framework: Yume introduces a preview version of an interactive world generation model that transforms static images into dynamic, explorable environments using keyboard controls, powered by four key components for high-fidelity video generation.
- Technical Breakthroughs: By quantizing camera motions, employing a Masked Video Diffusion Transformer with memory, enhancing sampling mechanisms, and accelerating models, Yume enables infinite autoregressive video creation with remarkable consistency and quality.
- Future Potential and Challenges: As a long-term project trained on the Sekai dataset, Yume sets a foundation for advanced AI interactions, though it faces hurdles in visual quality, efficiency, control accuracy, and expanding features like object manipulation.

In the ever-evolving landscape of artificial intelligence, where virtual realities are no longer confined to science fiction, Yume emerges as a groundbreaking model that’s pushing the boundaries of interactive world generation. Imagine uploading a single image—a serene landscape, a bustling city street, or an abstract artwork—and watching it spring to life as a fully explorable, dynamic world. This isn’t just passive viewing; it’s an immersive experience where you navigate using simple keyboard inputs, turning left, right, forward, or backward as if stepping into a living dream. Yume, which aptly means “dream” in Japanese, aims to bridge the gap between static media and interactive realities, allowing users to explore and control these worlds via peripheral devices or even neural signals in future iterations. While the full vision is ambitious, the preview version already showcases impressive capabilities, creating infinite videos from an input image and enabling real-time exploration.
At its core, Yume’s magic lies in its well-designed framework, comprising four main components that work in harmony to deliver high-fidelity, interactive video worlds. The journey begins with Camera Motion Quantization (QCM), a clever technique that translates complex camera trajectories into intuitive, user-friendly controls. Instead of dealing with intricate paths, QCM simplifies movements into directional commands like forward, backward, left, and right, along with rotational actions such as turning left or right, and tilting up or down—all mapped directly to keyboard inputs. This quantization embeds spatiotemporal context into the control signals without needing extra learnable modules, ensuring stable training and seamless user interaction. It’s a foundational step that makes Yume accessible, turning what could be a technically daunting process into something as straightforward as playing a video game.

Building on this, Yume’s Video Generation Architecture introduces the Masked Video Diffusion Transformer (MVDT), enhanced with a memory module for infinite video generation in an autoregressive manner. Unlike previous models limited by text-based controls, which often struggled with consistency over long sequences, MVDT overcomes these hurdles by maintaining temporal coherence and visual fidelity across extended explorations. The memory module acts like a digital storyteller, remembering previous frames to generate the next ones seamlessly, allowing the world to unfold endlessly without breaking immersion. This autoregressive approach means the generated video builds upon itself, creating a living, breathing environment that evolves as you navigate. Trained on the high-quality Sekai dataset, which focuses on world exploration scenarios, Yume achieves remarkable results across diverse scenes—from natural landscapes to urban settings—demonstrating its versatility in various applications.
To elevate the visual quality and precision, Yume incorporates advanced sampling mechanisms that refine the output without additional training. The Anti-Artifact Mechanism (AAM) is a training-free innovation that polishes latent representations, enhancing details and reducing unwanted distortions for crisper, more realistic visuals. Complementing this is the Time Travel Sampling based on Stochastic Differential Equations (TTS-SDE), which uses future-frame guidance to ensure temporal coherence, making movements feel natural and fluid. These samplers address common pitfalls in video generation, like artifacts or jittery transitions, resulting in a more precise and controlled experience. Together, they transform raw generative power into something polished and engaging, allowing users to lose themselves in the world without technical glitches pulling them back to reality.
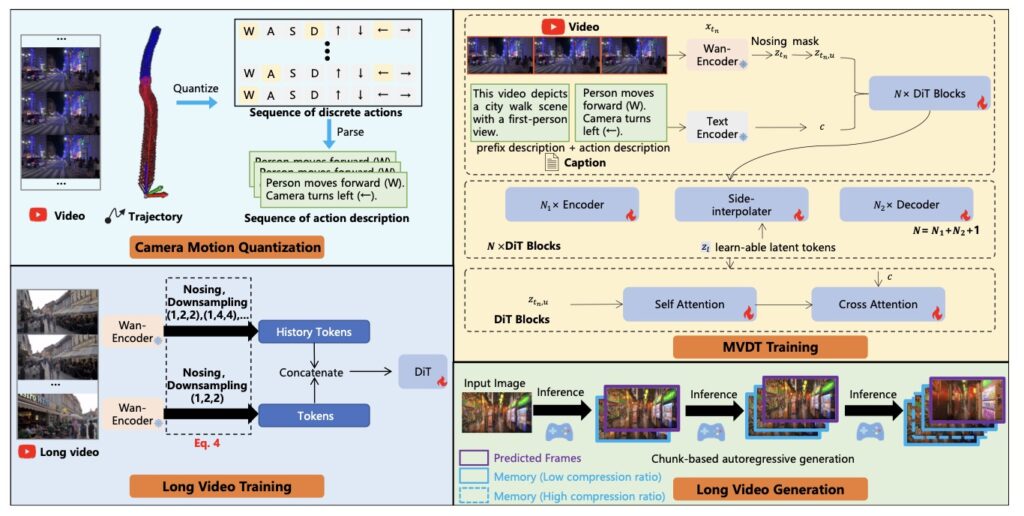
Efficiency is another pillar of Yume’s design, tackled through model acceleration via synergistic optimization. By combining adversarial distillation—which refines the model through competitive learning—and caching mechanisms that store and reuse computations, Yume boosts sampling efficiency by up to three times while preserving visual fidelity. This means faster generation times without sacrificing quality, making interactive exploration practical for real-world use. In a broader perspective, these optimizations highlight Yume’s forward-thinking approach, addressing the computational demands of AI models that often hinder scalability. As AI continues to integrate into daily life, such efficiencies could pave the way for applications in gaming, virtual tourism, education, and even therapeutic simulations, where immersive worlds help users practice skills or escape stressors.
Yet, Yume is more than a technical showcase; it’s a long-term project laying a solid foundation for the future of interactive AI. Trained on the Sekai dataset, it already excels in creating realistic, dynamic worlds from images, but challenges remain. Improving visual quality to photorealistic levels, enhancing runtime efficiency for broader accessibility, and refining control accuracy are key areas for development. Moreover, expanding functionalities—like enabling interactions with objects within the world—will unlock even greater potential, allowing users to not just explore but manipulate and engage with their generated environments. In a world where neural signals could one day control these realms, Yume represents a step toward truly mind-bending virtual experiences.

From a broader viewpoint, Yume exemplifies the rapid advancements in AI-driven creativity, blurring the lines between human imagination and machine execution. It invites us to ponder ethical questions, such as data privacy in neural interfaces or the societal impact of hyper-realistic simulations. As researchers continue to iterate, Yume could democratize world-building, empowering artists, educators, and everyday users to craft personalized realities. Whether for entertainment, training, or innovation, this model is a tantalizing preview of what’s possible when AI dreams big—turning a single image into an infinite adventure at the press of a key.