How Opus 4.6 and Sonnet 4.6 are redefining AI reasoning with massive context windows, eliminating premium pricing, and introducing intelligent token management.
- Massive Scale at Standard Pricing: The full 1-million token context window is now generally available for Opus 4.6 and Sonnet 4.6 without any long-context premium multipliers, alongside expanded media limits of up to 600 images or PDF pages.
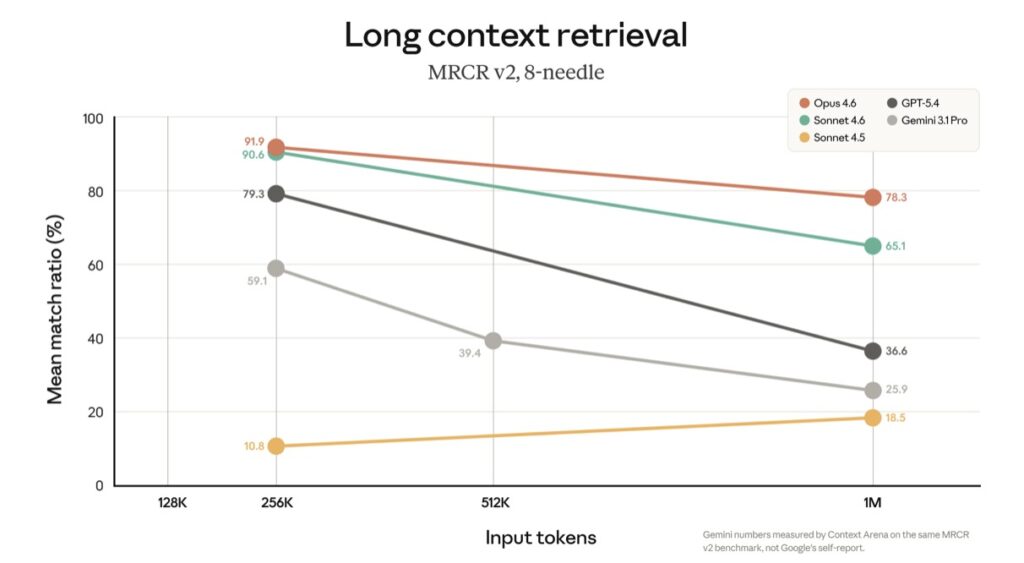
- Uncompromising Recall and Accuracy: Boasting a 78.3% score on the MRCR v2 benchmark, Opus 4.6 can digest entire codebases and massive contracts without the “context rot” or lossy summarization that previously plagued long-context AI.
- Smarter Memory Management: With auto-stripping for extended thinking blocks and new “context awareness” capabilities, Claude dynamically maximizes its token budget, acting like a chef who perfectly paces a dish against a ticking clock.
The landscape of artificial intelligence is fundamentally bound by a concept known as “working memory,” or the context window. Historically, pushing an AI to remember more meant sacrificing accuracy, inflating costs, and bogging down developers with complex workarounds. Today, that paradigm shifts. The general availability of the 1-million token context window for Claude Opus 4.6 and Sonnet 4.6 marks a watershed moment in generative AI, transforming how enterprises, developers, and everyday users interact with massive datasets.
The Democratization of Massive Context
Perhaps the most significant news surrounding this release is the economic model. Previously, utilizing massive context windows meant paying a premium. Now, standard pricing applies across the entire 1M window for both models. Whether you are sending a 9K-token request or a 900K-token request, the per-token rate remains identical—$5/$25 per million tokens for Opus 4.6 and $3/$15 for Sonnet 4.6.
This democratization is paired with a massive upgrade to media processing. Requests can now include up to 600 images or PDF pages, a six-fold increase from the previous 100-item limit. The friction of adopting this technology has also been completely removed. Available natively on the Claude Platform, as well as through Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Azure Foundry, requests over 200K tokens now work automatically without requiring a beta header. For users on Claude Code Max, Team, and Enterprise tiers, Opus 4.6 sessions default to the 1M context automatically, ensuring long-running conversations stay perfectly intact with fewer compactions.
Beyond the Hype: Memory That Actually Holds Up
A million tokens of available space is only as valuable as the model’s ability to accurately recall and reason across that data. As token counts grow, AI models traditionally suffer from “context rot”—a degradation in accuracy and recall. Claude, however, achieves state-of-the-art results that make this massive window practically usable.
Opus 4.6 currently holds a 78.3% score on MRCR v2, the highest among frontier models at this context length. From a broader perspective, this changes the day-to-day reality of engineering and legal work. You can now load an entire software codebase, thousands of pages of dense legal contracts, or the full, unedited trace of a long-running AI agent—including all tool calls, observations, and intermediate reasoning steps—and query it directly. The tedious engineering workarounds of the past, like lossy summarization and aggressive context clearing, are officially obsolete.
The Architecture of AI Memory
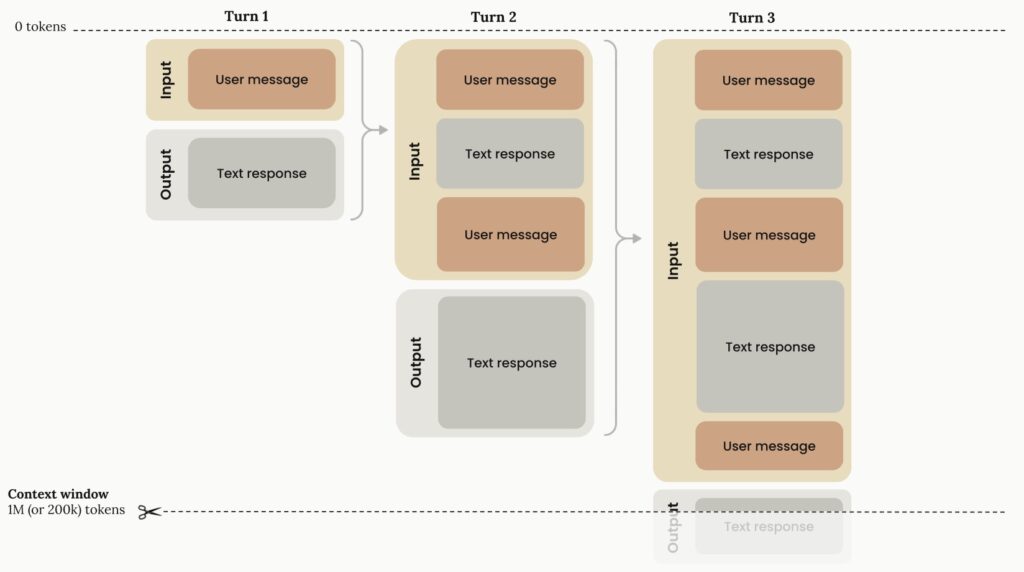
To fully leverage this technology, it is crucial to understand how Claude manages its working memory. The context window grows linearly through progressive token accumulation. In an input-output flow, the “Input phase” contains all previous conversation history plus the current user message, while the “Output phase” generates the text response that becomes part of the future input.
While 1 million tokens provide an incredibly wide canvas, curation remains essential. More context isn’t automatically better if it’s filled with irrelevant noise. This is where Claude’s advanced token management architecture steps in to keep the context window optimized.

Extended Thinking Without the Token Tax
One of the most innovative features of Claude’s new architecture is how it handles “extended thinking.” When Claude tackles complex problems, it uses a thinking budget (a subset of the max_tokens parameter) to reason through the task. With adaptive thinking, Claude dynamically decides how much of this budget to allocate.
Crucially, you are not penalized for Claude’s deep thoughts. While these thinking tokens are billed as output tokens during generation, the Claude API automatically strips previous thinking blocks from the context window for subsequent turns. This means the model’s internal reasoning doesn’t clog up your valuable 1M token capacity as the conversation progresses.
The implementation becomes highly specialized during tool use. In a standard tool-use cycle, the extended thinking block must be returned unmodified with the corresponding tool results, as the system uses cryptographic signatures to verify the block’s authenticity and preserve reasoning continuity. However, once that specific tool use cycle is complete and a new user turn begins, that old thinking block is cleanly dropped, freeing up space for the next phase of the conversation.
The “Cooking Show” Clock: Context Awareness
Finally, Claude Sonnet 4.6, Sonnet 4.5, and Haiku 4.5 introduce a groundbreaking feature: context awareness. Rather than blindly generating text and hoping it doesn’t hit a wall, these models actively track their remaining token budget throughout a conversation.
Imagine competing in a high-stakes cooking show without a clock; it would be nearly impossible to pace your work. For an AI, lacking context awareness is the exact same problem. By explicitly informing the model about its remaining context, Claude 4.5 and 4.6 models can pace themselves, execute complex tasks, and persist until the very end, taking maximum advantage of every single token available to them.
The 1-million token era is no longer just a benchmark; it is a practical, cost-effective, and highly intelligent reality. By combining unprecedented scale with smart memory management, Claude is redefining what is possible in generative AI.