New cross-frame textual guidance module promises more dynamic and coherent videos from AI models
- Temporal Logic Improvements: FancyVideo introduces a new framework to improve temporal consistency in AI-generated videos by incorporating frame-specific textual guidance.
- State-of-the-Art Performance: The model has achieved leading results on the EvalCrafter benchmark, setting a new standard for text-to-video (T2V) generation.
- Innovative Modules: FancyVideo incorporates the Temporal Information Injector (TII), Temporal Affinity Refiner (TAR), and Temporal Feature Booster (TFB) to enhance cross-frame consistency.
As AI continues to make strides in video generation, one of the persistent challenges is maintaining dynamic motion and temporal consistency across extended sequences. Existing text-to-video (T2V) models often rely on spatial cross-attention mechanisms to guide video generation, but this approach falls short when it comes to preserving the natural flow of motion from frame to frame. Addressing these shortcomings, researchers have introduced FancyVideo, a groundbreaking video generation framework designed to tackle the complex challenge of generating long-duration videos with coherent and dynamic motion.
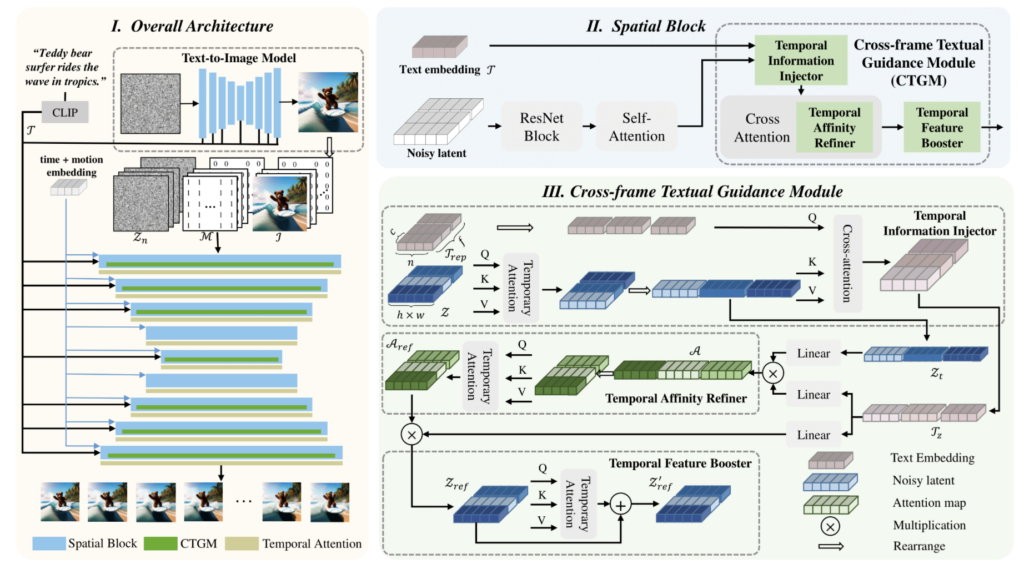
FancyVideo’s primary innovation lies in its Cross-frame Textual Guidance Module (CTGM), which enhances traditional text-control mechanisms with three core components: the Temporal Information Injector (TII), Temporal Affinity Refiner (TAR), and Temporal Feature Booster (TFB). These modules work together to ensure that text prompts not only guide each frame individually but also maintain the consistency of movement and visual logic across all frames, resulting in videos that flow more naturally from beginning to end.
Tackling Temporal Inconsistency
The main limitation of current T2V models stems from their inability to interpret and maintain temporal logic. Traditional models often treat each frame as a separate entity, which leads to inconsistencies when generating videos that require continuous motion or extended storytelling. FancyVideo’s solution to this problem starts with the Temporal Information Injector (TII), which infuses frame-specific data into the text conditions that guide video generation. By introducing this temporal awareness at the onset of the generation process, the model gains a deeper understanding of how different frames relate to one another, enabling it to generate videos that feel more connected and fluid.
Following this, the Temporal Affinity Refiner (TAR) plays a crucial role in refining the relationships between frames. TAR modifies the correlation matrix between the text prompts and the latent features across the time dimension, ensuring that the temporal connections are refined and reinforced throughout the video. This helps maintain smooth transitions between frames, which is particularly important when generating videos with intricate motion patterns or complex scene transitions.
Finally, FancyVideo employs the Temporal Feature Booster (TFB), which acts as a final pass to enhance the temporal consistency of the latent features. TFB ensures that even as the video reaches its later stages, the features remain coherent, preventing issues such as jittery motion or abrupt changes in scene dynamics. Together, these three modules allow FancyVideo to produce videos with a far greater level of detail and consistency than its predecessors.
Performance on the EvalCrafter Benchmark
FancyVideo’s performance has been rigorously tested on the EvalCrafter benchmark, a widely recognized evaluation framework for video generation models. FancyVideo consistently outperformed competing models, demonstrating its ability to generate not only more visually appealing videos but also videos that adhere more closely to the intended motion and scene progression. Human evaluators also confirmed that the videos produced by FancyVideo were smoother and more engaging, particularly as the number of frames increased.
This breakthrough in frame-specific textual guidance offers a glimpse into the future of AI video generation, where models can be trusted to generate extended video sequences with dynamic, believable motion. As AI-generated content continues to grow in popularity across industries such as entertainment, advertising, and social media, innovations like FancyVideo are setting the stage for more advanced and reliable video creation tools.
Practical Implications and Future Developments
The implications of FancyVideo’s technology are far-reaching. With the ability to generate longer and more consistent videos, FancyVideo could enable a range of applications—from virtual cinematography to automated video content creation for marketing and entertainment industries. Filmmakers, content creators, and even social media influencers could benefit from AI tools that can seamlessly transform text prompts into high-quality video productions with minimal manual input.
Looking ahead, the researchers behind FancyVideo are planning to further refine the model by incorporating additional layers of control, such as specific style and tone guidance, as well as improving the model’s ability to generate videos across a wider variety of genres and contexts. They also aim to optimize the efficiency of FancyVideo, reducing the computational costs associated with extended video generation without sacrificing quality.
FancyVideo represents a significant leap forward in the field of video generation. By introducing frame-specific textual guidance through its Cross-frame Textual Guidance Module, FancyVideo addresses the limitations of previous models that struggled to maintain coherent motion across extended sequences. As a result, FancyVideo offers a more robust solution for dynamic and consistent video generation, opening up new possibilities for creative AI applications.