How a new suite of models is democratizing high-fidelity music generation with unprecedented control and lyric clarity.
- The Open-Source Revolution: HeartMuLa represents a significant shift from closed commercial systems, offering a “family” of foundation models that prove commercial-grade music generation is reproducible with academic-scale resources.
- Unmatched Control: The LLM-based architecture supports multi-modal inputs and unique section-specific prompting, allowing users to define different styles for verses, choruses, and intros within a single track.
- Superior Performance: Early comparisons indicate HeartMuLa tops industry heavyweights like Suno v5 and Udio v1.5 specifically in lyric clarity, powered by a robust transcription engine.

For the past year, the generative music landscape has been dominated by closed-source giants. Platforms like Suno and Udio have dazzled users with their ability to conjure radio-ready tracks from simple text prompts, but the “black box” nature of these tools has limited researcher access and deep user control. Move over, Suno—there is a new player in town, and it is blowing the doors off the walled gardens. Enter HeartMuLa, a revolutionary family of open-source music foundation models that is redefining what is possible in AI music production.
A Family, Not Just a Model
What makes HeartMuLa distinct is that it isn’t just a single music generator; it is a comprehensive ecosystem designed to handle the entire pipeline of music understanding and creation. The developers have introduced a framework consisting of four interconnected components that work in harmony:
- HeartCLAP: This is the bridge between language and sound. It is an audio-text alignment model that creates a unified “embedding space,” allowing the system to truly understand music descriptions and perform cross-modal retrieval.
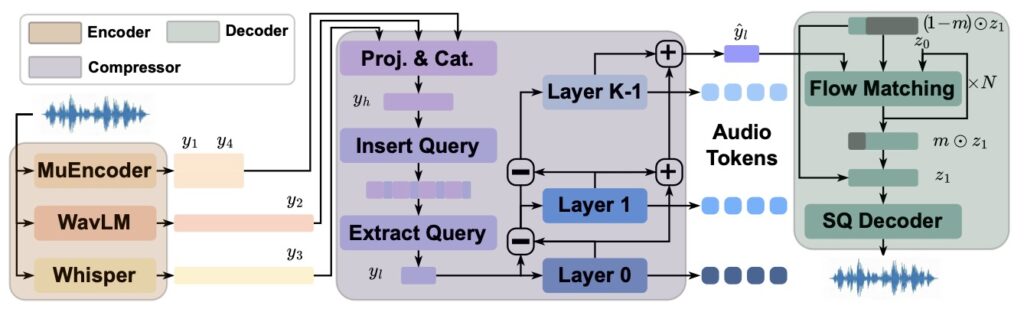
- HeartCodec: The engine room of the operation. This is a high-fidelity music codec tokenizer operating at a remarkably low frame rate of 12.5 Hz. By processing fewer frames without losing quality, it captures long-range musical structures while preserving fine acoustic details, enabling highly efficient modeling.
- HeartTranscriptor: A robust lyric recognition model optimized for real-world scenarios, ensuring the system “hears” words as clearly as it speaks them.
- HeartMuLa: The star of the show—an LLM-based song generation model that synthesizes high-fidelity music based on the groundwork laid by the previous three components.
Precision Control over the Creative Process
The primary frustration with current commercial models is the “slot machine” effect: you pull the lever (prompt) and hope for the best. HeartMuLa changes the game by introducing fine-grained musical attribute control.
Because HeartMuLa functions as a Large Language Model (LLM), it supports multi-modal inputs, including textual style descriptions, explicit lyrics, and even reference audio. However, its standout feature is the ability to apply section-specific style prompts. Users can use natural language to dictate that the intro should be a soft acoustic melody, the verse should transition into lo-fi hip hop, and the chorus should explode into pop-punk. This hierarchical control offers a level of composition usually reserved for DAWs (Digital Audio Workstations), not generative AI.
Additionally, the model includes a specialized mode for short, engaging music generation. This is specifically engineered for the TikTok and YouTube Shorts era, creating punchy background tracks that grab attention instantly.
Breaking the “Commercial Quality” Barrier
Perhaps the most significant achievement of the HeartMuLa project is its proof of concept: for the first time, researchers have demonstrated that a Suno-level system can be reproduced using academic-scale data and GPU resources.
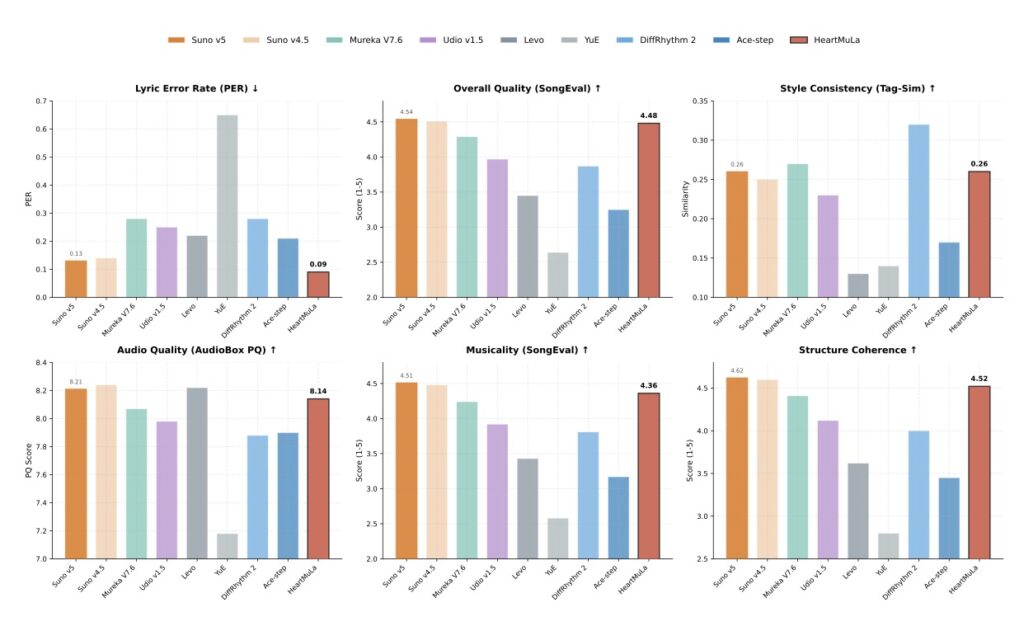
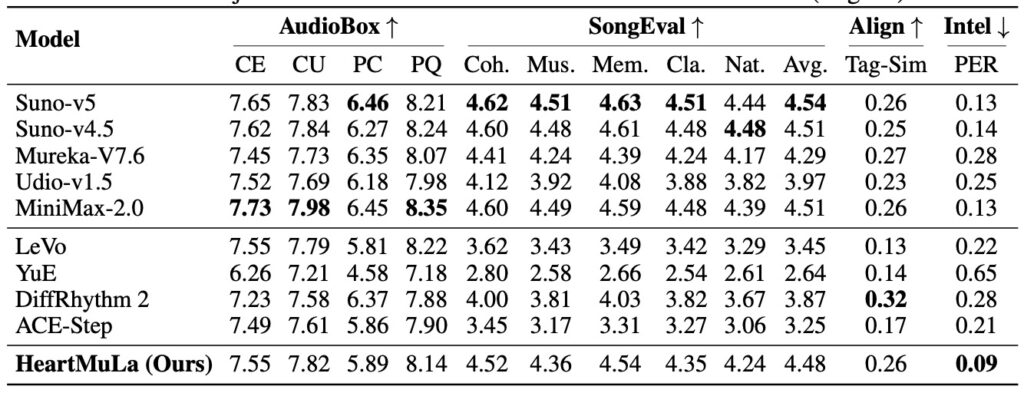
When scaled to 7 billion parameters, HeartMuLa doesn’t just match the competition; in specific areas, it beats them. The integration of the HeartTranscriptor and HeartCodec allows for exceptional vocal rendering. Reports suggest that HeartMuLa actually tops Suno v5 and Udio v1.5 on lyric clarity, solving the “mumble” problem that often plagues AI vocals.

By open-sourcing this suite, the creators have provided a robust baseline for future research. HeartMuLa is not just a tool for creating songs; it is a foundation for the next generation of multimodal content production, proving that the future of AI music is open, controllable, and crystal clear.