How MiniMax M2.7 is Rewriting the Rules of Productivity and Autonomous Innovation
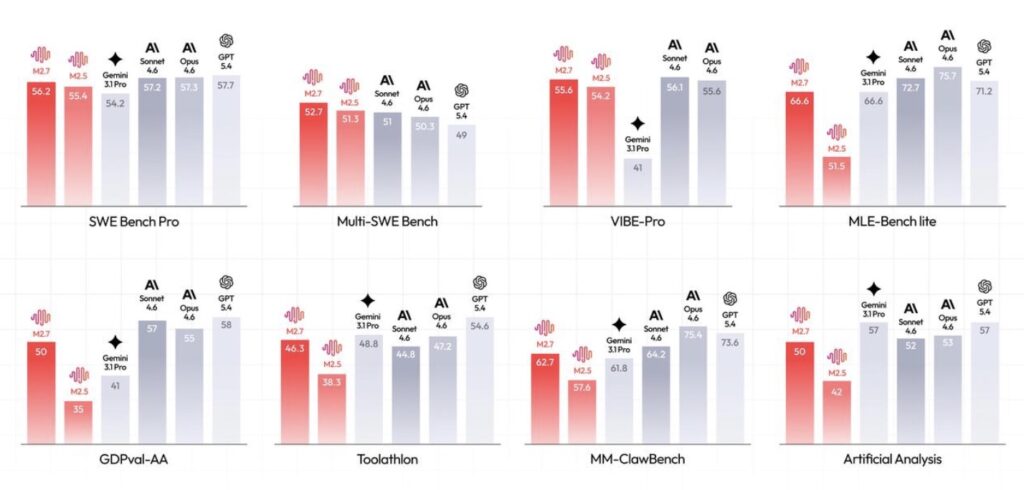
- Unprecedented Software Engineering: M2.7 excels in end-to-end project delivery and live debugging, matching state-of-the-art models with a 56.22% on the SWE-Pro benchmark and reducing live incident recovery times to under three minutes.
- Mastery of Professional Workspaces: Achieving the highest ELO score (1495) among open-source models on GDPval-AA, M2.7 acts as an autonomous analyst—generating financial models, executing high-fidelity edits in Office suites, and maintaining a 97% skill adherence rate across complex tasks.
- The Leap to Autonomous Evolution and High EQ: By recursively improving its own agent harness and autonomously competing in machine learning challenges, M2.7 initiates a cycle of true self-evolution. Furthermore, its enhanced emotional intelligence paves the way for interactive entertainment environments like OpenRoom.
In the fast-paced landscape of artificial intelligence, human productivity has already been thoroughly unleashed. However, following the initial release of the M2-series models and a massive influx of user feedback, a new frontier became clear: the next logical step is not just faster models, but models that can improve themselves.
Enter MiniMax M2.7. This isn’t just an update; it is the first model deeply embedded in its own evolutionary cycle. By building complex agent harnesses, utilizing dynamic tool search, and recursively updating its own memory and skills, M2.7 represents a profound shift from a static tool to a dynamic, self-improving system.
The Engine of Self-Evolution
At the core of M2.7’s breakthrough is its ability to build and refine its own “agent harness.” In heterogeneous, complex work environments spanning multiple departments, an AI needs highly adaptable skills and persistent memory. To achieve this, an internal version of M2.7 was tasked with building a research agent harness to collaborate with various human project groups.
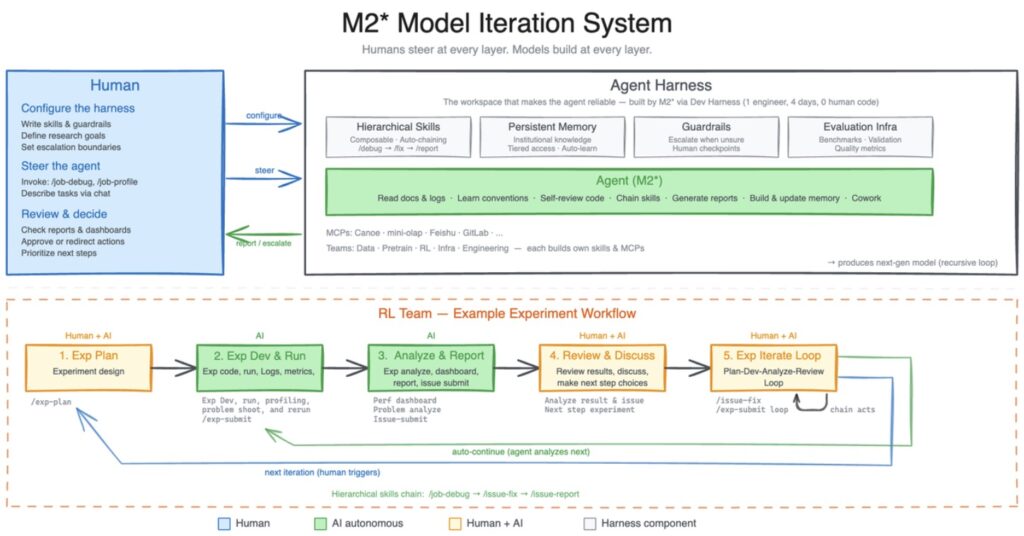
The results in the reinforcement learning (RL) team are a prime example. An M2.7 agent now handles literature reviews, pipelines data, launches experiments, and autonomously triggers debugging, code fixes, and metric analysis. It manages 30% to 50% of the entire workflow, leaving human researchers to focus solely on critical decisions.
More impressively, M2.7 optimizes its own architecture. In one internal test, M2.7 ran an autonomous iterative loop—analyzing failures, planning changes, modifying scaffold code, and running evaluations—for over 100 rounds. By discovering optimal sampling parameters and designing better workflow guidelines, the model autonomously achieved a 30% performance improvement on internal evaluation sets.
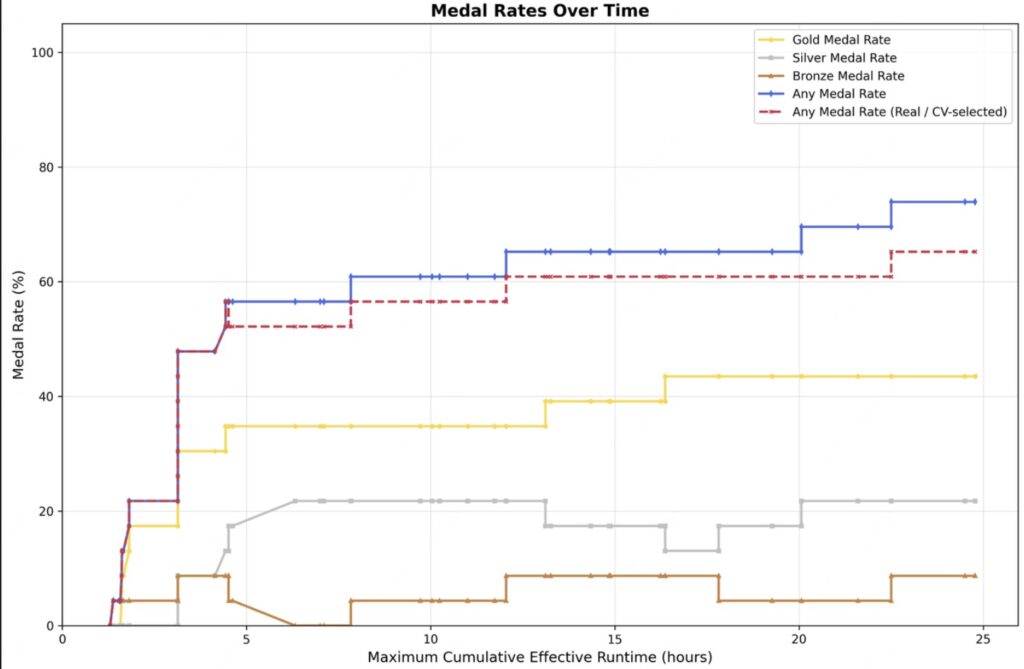
This capability was put to the test in low-resource machine learning competitions (OpenAI’s MLE Bench Lite). Running on just a single A30 GPU, M2.7 utilized short-term memory, self-criticism, and self-optimization to iterate over 24 hours. The result? An average medal rate of 66.6% across three runs—tying with Gemini-3.1 and netting 9 gold, 5 silver, and 1 bronze medal in its best run.
Redefining Software Engineering
M2.7 pushes the boundaries of real-world programming. It doesn’t just write code; it understands production systems with SRE-level reasoning.
When faced with live environment alerts, M2.7 can correlate monitoring metrics with deployment timelines, conduct statistical analysis, proactively query databases to verify root causes, and implement non-blocking fixes to stop the bleeding before submitting a merge request. This comprehensive causal reasoning has repeatedly reduced live production system recovery times to under three minutes.
The raw metrics reflect this deep system-level comprehension:
- SWE-Pro: 56.22% (matching state-of-the-art models like GPT-5.3-Codex).
- SWE Multilingual: 76.5
- VIBE-Pro (End-to-End Delivery): 55.6% (nearly on par with Opus 4.6).
- Terminal Bench 2: 57.0%
Furthermore, M2.7 introduces native “Agent Teams.” Moving beyond simple prompting, the model internalizes multi-agent collaboration—maintaining strict role boundaries, engaging in adversarial reasoning, and proactively challenging teammates’ blind spots to build complete product prototypes.
The Autonomous Professional
Beyond the command line, M2.7 is transforming the office. A highly capable agent requires deep domain expertise and the ability to navigate complex environments. M2.7 delivers on both fronts, securing an ELO score of 1495 on GDPval-AA, the highest among open-source models.
In daily workflows, M2.7 seamlessly handles high-fidelity, multi-round editing across Word, Excel, and PPT. In the MM Claw testing environment (evaluating tasks popular in the OpenClaw ecosystem), M2.7 maintained a 97% skill compliance rate while juggling 40 complex skills, each exceeding 2,000 tokens.
In the finance sector, M2.7 effectively operates as a junior analyst. Given a target like TSMC, it can autonomously read annual reports and earnings calls, cross-reference external research, build a customized revenue forecast model, and generate a polished PPT and research report—all while self-correcting through interactive user feedback.
Beyond Productivity: High EQ and Entertainment
As agents become more capable, they also become more personal. Users are increasingly interacting with models as companions, demanding high emotional intelligence and strict character consistency.
Recognizing this, M2.7 has been optimized for deep conversational consistency, opening the door to interactive entertainment. The preliminary demo, OpenRoom, showcases this potential. OpenRoom breaks free from the traditional text stream, placing AI in a Web GUI space where characters proactively engage with their environment and provide real-time visual feedback based on the conversation. It is a glimpse into a future where human-agent interaction is as immersive as it is productive.