A new era of open-source AI with the power of Mixture-of-Experts and unrivaled edge efficiency.
- A Complete Family: The release includes Mistral Large 3 (a massive 675B parameter MoE) and the Ministral 3 series (3B, 8B, and 14B), all under the Apache 2.0 license.
- Unmatched Performance: Mistral Large 3 achieves parity with top instruction-tuned models, debuting at #2 on the LMArena leaderboard, while Ministral offers the best performance-to-cost ratio in its class.
- Hardware Synergy: Developed in close collaboration with NVIDIA, vLLM, and Red Hat, these models are optimized for hardware ranging from massive H200 clusters to local RTX laptops.
The landscape of open-source artificial intelligence has shifted dramatically today with the announcement of Mistral 3. This next-generation family of models represents a commitment to distributed intelligence, empowering the developer community by placing frontier-grade AI into the hands of everyone. By open-sourcing these models under the permissive Apache 2.0 license, Mistral is providing a transparent, scalable foundation for innovation, ranging from the massive data center to the edge device in your backpack.
Mistral Large 3: The New Heavyweight Champion
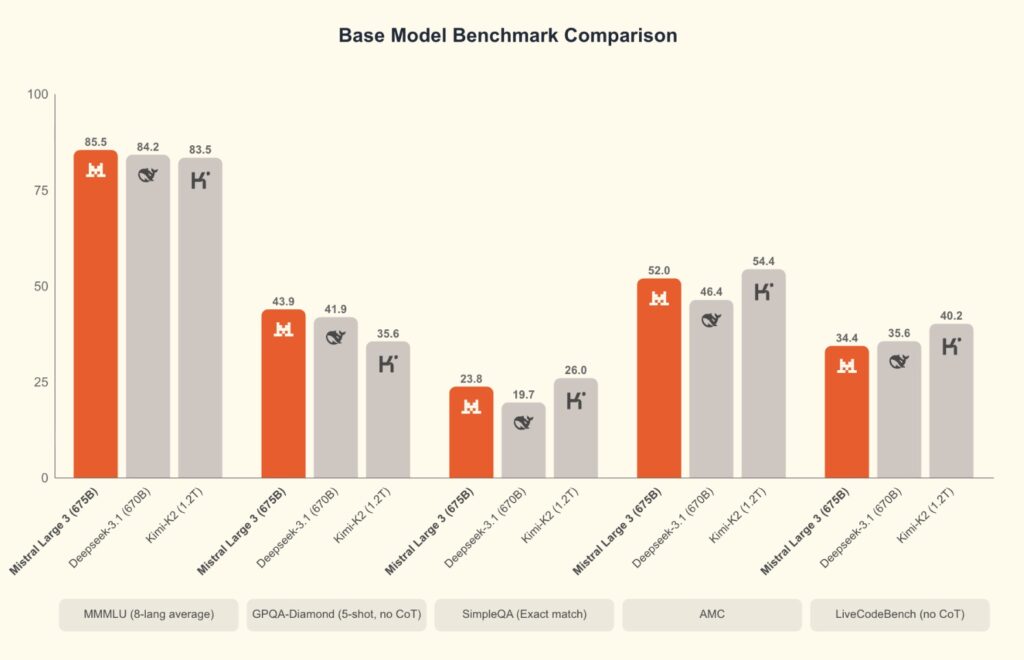
Leading the charge is Mistral Large 3, the company’s most capable model to date. This is not just a standard upgrade; it is a sparse Mixture-of-Experts (MoE) model featuring 41B active parameters within a massive 675B total parameter architecture.
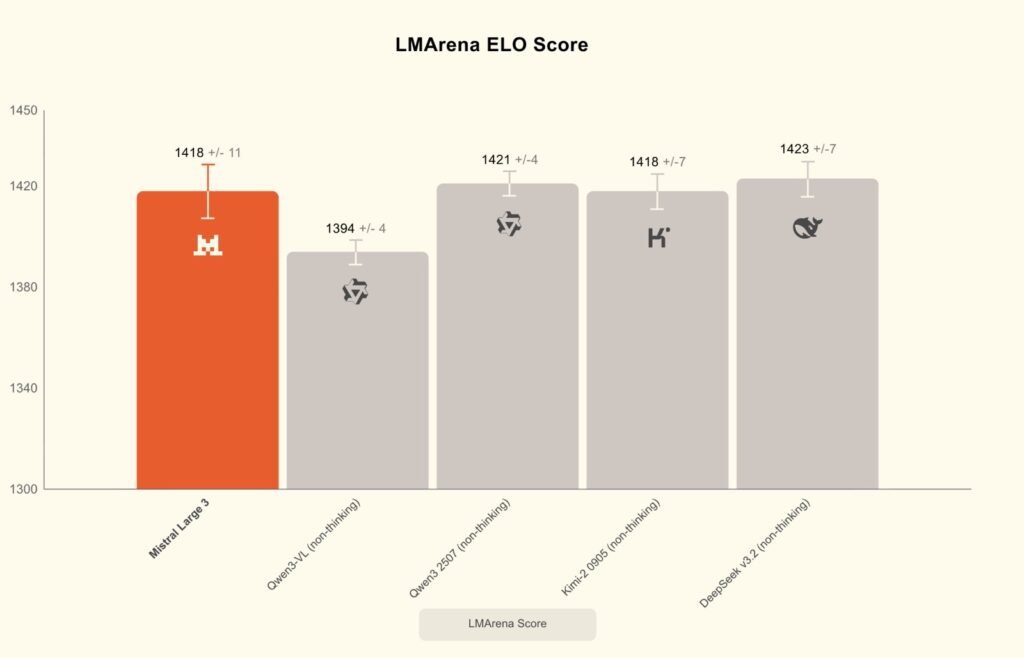
Trained from scratch on 3,000 of NVIDIA’s cutting-edge H200 GPUs, Mistral Large 3 represents a significant leap in pretraining techniques. It has already made waves in the community, debuting at #2 in the OSS non-reasoning models category (#6 overall) on the LMArena leaderboard.
Mistral Large 3 achieves parity with the best instruction-tuned open-weight models on the market. Beyond standard text generation, it boasts:
- Image Understanding: Native multimodal capabilities.
- Multilingual Mastery: Best-in-class performance on non-English/Chinese conversations.
- Future-Proofing: While the base and instruct versions are available now, a reasoning-specific version is coming soon.

Ministral 3: Frontier Intelligence at the Edge
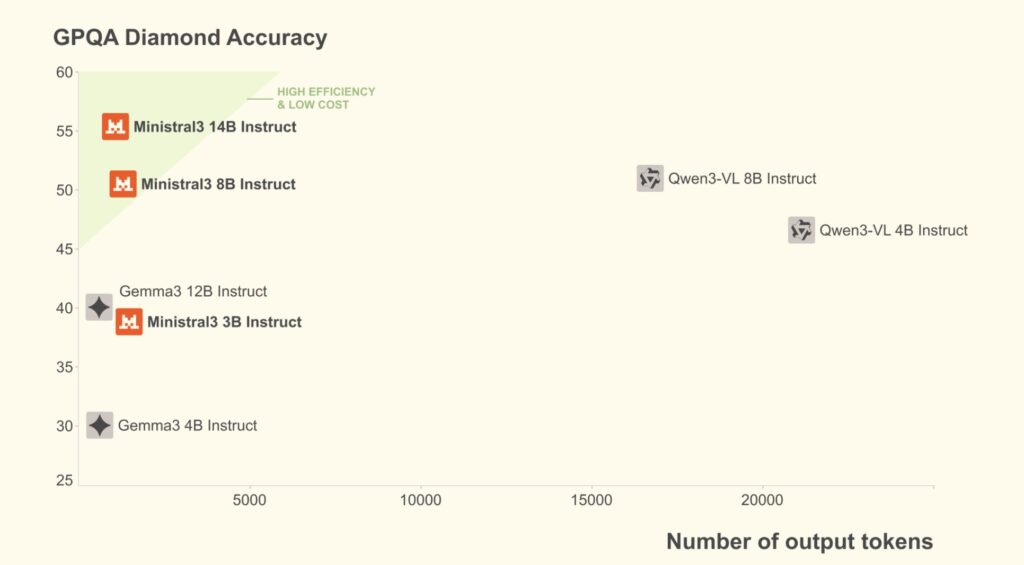
Recognizing that real-world utility often relies on speed and cost, the launch includes the Ministral 3 series. Available in 3B, 8B, and 14B sizes, these dense models are engineered for the best performance-to-cost ratio in the industry.
For developers, the Ministral family offers immense flexibility. Each size comes in base, instruct, and reasoning variants, all with image understanding. The efficiency here is critical: Ministral instruct models match or exceed the performance of comparable models while often producing an order of magnitude fewer tokens.
For scenarios where accuracy is paramount, the Ministral reasoning variants shine. They are designed to “think longer,” achieving state-of-the-art accuracy for their weight class. Notably, the 14B variant scored an impressive 85% on AIME ‘25, proving that small models can handle complex logic when optimized correctly.
Optimized by Giants: The NVIDIA, vLLM & Red Hat Partnership
Delivering advanced open-source AI requires more than just model weights; it requires a robust software and hardware ecosystem. Mistral 3 is the result of an “extreme co-design” approach involving NVIDIA, vLLM, and Red Hat.
- Data Center Scale: All models were trained on NVIDIA Hopper GPUs to utilize high-bandwidth HBM3e memory. NVIDIA engineers have enabled efficient inference support for TensorRT-LLM and SGLang.
- Accessible Power: Working with vLLM, Mistral is releasing a checkpoint in NVFP4 format (built with
llm-compressor). This allows Mistral Large 3 to run efficiently on Blackwell NVL72 systems or even on a single 8×A100/H100 node. - From Cloud to Robot: The optimization extends to the edge. The Ministral models are tuned for deployment on DGX Spark, RTX PCs, laptops, and Jetson devices, providing a consistent path from the server room to robotics.
Deployment and Customization
The future of AI is open, and Mistral is ensuring these tools are available immediately. Mistral 3 is accessible today via Mistral AI Studio, Amazon Bedrock, Azure Foundry, Hugging Face, IBM WatsonX, and many others.
For organizations requiring specialized solutions, Mistral AI is also offering custom model training services. Whether fine-tuning for domain-specific tasks or enhancing performance on proprietary datasets, this service allows enterprises to build secure, high-impact AI systems that align specifically with their business goals.