Combining reasoning, vision, and coding in a hyper-efficient, single model design.
- The “One Model” Approach: Mistral Small 4 unifies the distinct capabilities of flagship models Magistral (reasoning), Pixtral (multimodality), and Devstral (coding) into a single, highly versatile assistant.
- Cutting-Edge Architecture: Built on a 119B parameter Mixture of Experts (MoE) architecture with a massive 256k context window, it natively supports both text and image inputs while allowing users to toggle their desired level of reasoning effort.
- Unmatched Efficiency: Released under the permissive Apache 2.0 license, it delivers a 40% reduction in completion time and 3x more throughput than its predecessor, generating highly accurate responses with significantly shorter output lengths.
The landscape of artificial intelligence has often forced developers and enterprises to make a difficult choice: deploy a fast conversational model, integrate a powerful reasoning engine, or build around a specialized multimodal assistant. Today, that fragmentation ends. The introduction of Mistral Small 4 represents a major leap forward, unifying top-tier coding, reasoning, and multimodal capabilities into one cohesive, versatile model.
At its core, Mistral Small 4 is designed to eliminate the need for context-switching between specialized tools. By consolidating the strengths of the Magistral, Devstral, and Mistral Small lineages, it adapts seamlessly to whatever task is at hand. Whether you are automating a codebase, parsing complex visual documents, or executing multi-step mathematical reasoning, Mistral Small 4 delivers a unified, enterprise-grade experience. Furthermore, by releasing it under the Apache 2.0 license, Mistral reaffirms a deep commitment to open, accessible, and highly customizable AI.
Under the Hood: Architectural Brilliance
Mistral Small 4 is a hybrid model built on a highly optimized Mixture of Experts (MoE) architecture. It boasts a total of 119 billion parameters distributed across 128 experts. Despite this massive scale, it operates with incredible efficiency by activating only 4 experts—or 6 billion active parameters (8 billion including embedding and output layers)—per token.
This model isn’t just about raw power; it’s about expansive understanding. With a 256k context window, it easily digests long-form interactions and extensive document analysis. It also introduces native multimodality, accepting both text and image inputs to unlock advanced use cases like visual analysis and complex document parsing right out of the box. Most uniquely, Mistral Small 4 introduces configurable reasoning effort, allowing users to dynamically toggle between lightning-fast, low-latency responses and deep, intensive analytical outputs depending on the immediate need.
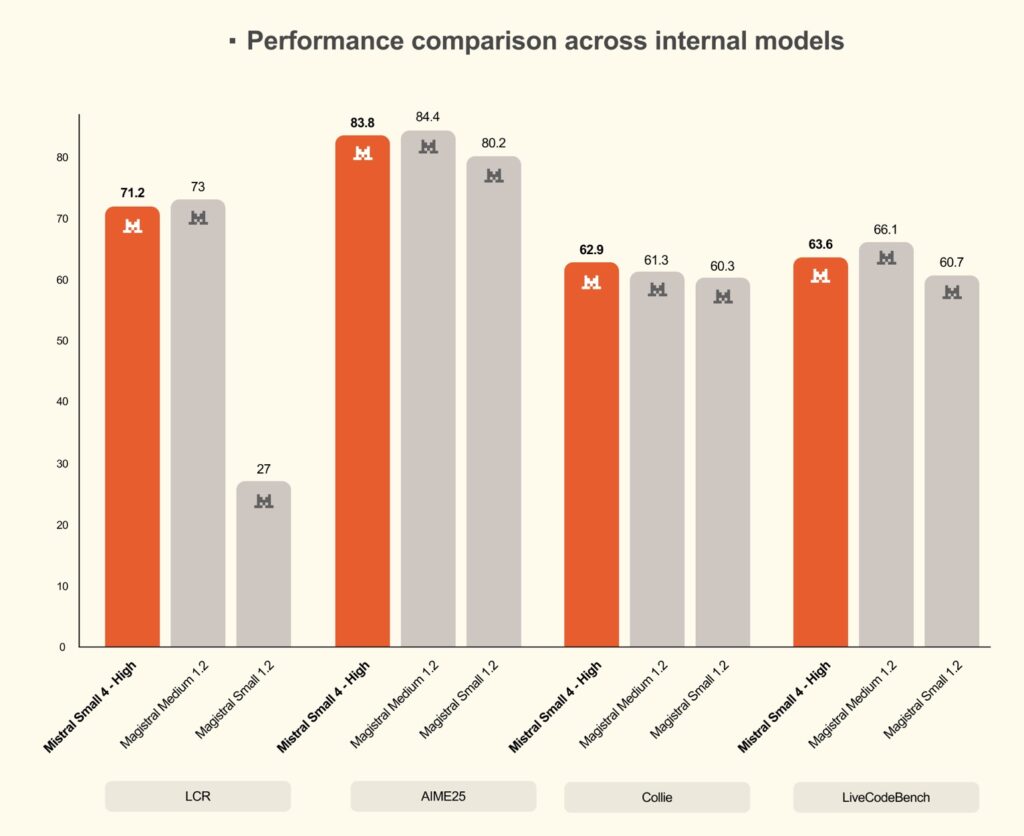
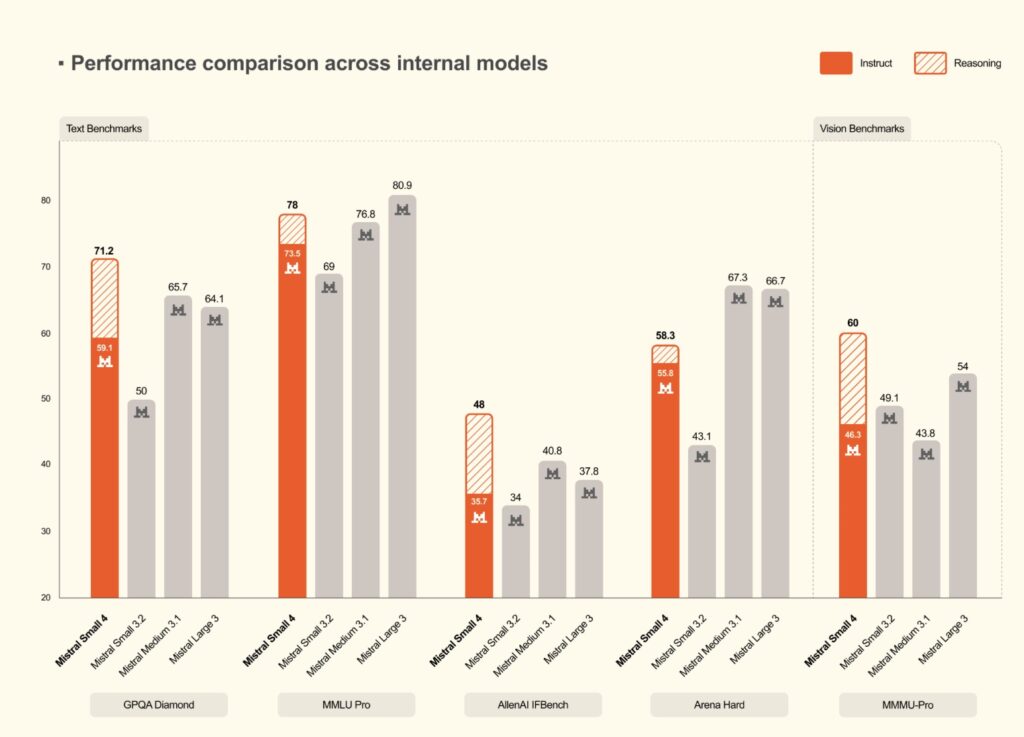
Redefining Performance and Efficiency
Performance per token is the new gold standard for model selection, and Mistral Small 4 excels in this arena. Compared to Mistral Small 3, the new model achieves a 40% reduction in end-to-end completion time in latency-optimized setups, alongside 3x more requests per second when optimized for throughput.
This efficiency becomes glaringly obvious in competitive benchmarks. Mistral Small 4 matches or surpasses GPT-OSS 120B on key benchmarks while generating significantly shorter, more concise outputs. For example, on the AA LCR benchmark, Mistral Small 4 achieves a score of 0.72 using just 1.6K characters—whereas competing Qwen models require nearly four times the output length (5.8K to 6.1K characters) to hit comparable performance. On LiveCodeBench, it consistently outperforms GPT-OSS 120B while producing 20% less output. Shorter outputs mean drastically lower latency, reduced inference costs, and a vastly superior end-user experience.
Value for Enterprise and Technical Teams
For enterprise buyers, this efficiency directly translates to scalable, cost-effective operations. Models that maintain high accuracy without inflating output length reduce operational costs and the need for manual intervention in high-stakes workflows like report generation or customer support.
For data scientists and technical teams, this hybrid reasoning model means fewer trade-offs. The ability to deploy solutions for nuanced, multi-step tasks without skyrocketing computational costs allows for more innovative application development. The model is also highly adaptable to varying hardware setups. It requires a minimum infrastructure of 4x NVIDIA HGX H100, 2x HGX H200, or 1x DGX B200, with scaling recommended for optimal enterprise performance.

Availability and the Open Future
Delivering advanced open-source AI requires broad optimization, which is why Mistral has proudly joined the NVIDIA Nemotron Coalition as a founding member. Through this collaboration, inference is deeply optimized for open-source platforms like vLLM and SGLang, as well as llama.cpp and Transformers.
Mistral Small 4 is available immediately across multiple platforms. Developers can prototype for free on NVIDIA’s accelerated computing at build.nvidia.com, access it day-zero as an NVIDIA NIM for containerized inference, or find it on the Hugging Face Repository and Mistral API/AI Studio. For specialized tasks, it can be easily fine-tuned using NVIDIA NeMo.