Revolutionizing Long-Form Video Generation with MovieDreamer
- MovieDreamer combines autoregressive models and diffusion rendering for long-duration video generation.
- The framework ensures narrative coherence and character consistency across extended video sequences.
- MovieDreamer’s multimodal scripts enhance scene descriptions, offering superior visual and narrative quality.

Advancements in video generation have made significant strides, yet creating long-form content such as movies has remained a challenging frontier. Traditional diffusion models excel at short-duration videos but often fail to maintain narrative coherence and character consistency over extended periods. Addressing this gap, MovieDreamer emerges as a pioneering solution, integrating the strengths of autoregressive models and diffusion-based rendering to produce high-quality, long-duration videos with intricate plot progressions.
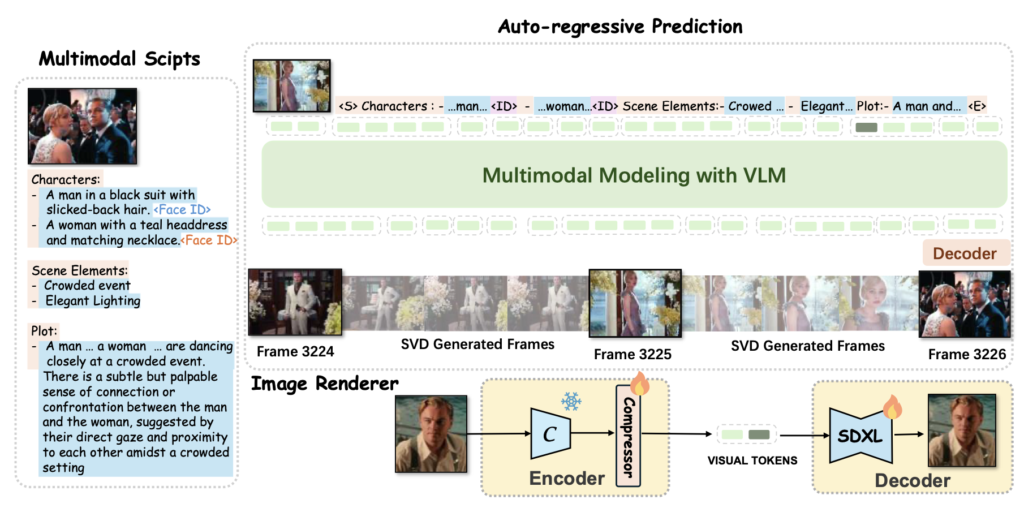
Combining Autoregressive Models with Diffusion Rendering
MovieDreamer’s innovative approach lies in its hierarchical framework, which utilizes autoregressive models for ensuring global narrative coherence. These models predict sequences of visual tokens that are then transformed into high-quality video frames through diffusion rendering. This method mirrors traditional movie production, where complex stories are broken down into manageable scenes, maintaining a cohesive narrative thread throughout the video.

The integration of autoregressive models with diffusion rendering leverages the best of both worlds. Autoregressive models excel at handling complex reasoning and predicting future events, crucial for maintaining a storyline. On the other hand, diffusion models are adept at high-fidelity visual rendering, essential for creating visually stunning content. This combination allows MovieDreamer to generate long videos while preserving both visual and narrative quality.

Ensuring Character Consistency with Multimodal Scripts
One of the significant challenges in long-duration video generation is maintaining character consistency across different scenes. MovieDreamer addresses this by employing multimodal scripts, which enrich scene descriptions with detailed character information and visual styles. These scripts ensure that characters retain their identity throughout the video, enhancing the overall coherence and viewer engagement.

Moreover, MovieDreamer introduces ID-preserving rendering, a technique designed to better preserve character identities across sequences. This approach supports few-shot movie creation, enabling the generation of extended video content with minimal input data, thus showcasing the model’s efficiency and flexibility.
Pushing the Boundaries of Generative AI
MovieDreamer’s capabilities are demonstrated through extensive experiments across various movie genres, proving its potential to revolutionize long-form video generation. By achieving superior visual and narrative quality, MovieDreamer sets a new benchmark in the field. The method significantly extends the duration of generated content, going beyond the limitations of current video generation technologies.
Previous models, like the Sora model, have made notable progress by extending video durations from seconds to minutes. However, MovieDreamer pushes these boundaries further, opening possibilities for generating hours-long movies. This advancement not only reshapes the landscape of generative AI but also fosters anticipation for future innovations in automated video production.
Addressing the Challenges of Long-Form Content
The primary challenge with existing video generation methods is their inability to handle complex narratives and extended durations effectively. Diffusion models, while excellent for visual rendering, struggle with abstract logic and reasoning required for coherent storytelling. Conversely, autoregressive models excel at these tasks but demand substantial computational resources for visual rendering.
MovieDreamer addresses these challenges by combining the strengths of both approaches. The autoregressive models handle the narrative structure, ensuring logical progression and coherence, while the diffusion models take care of the high-fidelity visual rendering. This synergy allows MovieDreamer to generate long-duration videos with intricate and engaging narratives, maintaining a high level of visual quality.
MovieDreamer represents a significant leap in the field of long-form video generation, offering a solution that marries narrative coherence with high-quality visual rendering. By integrating autoregressive models and diffusion techniques, MovieDreamer addresses the challenges of creating extended video content with consistent character representation and complex storylines. This breakthrough opens up exciting possibilities for the future of automated video production, potentially transforming the way movies and long-form content are created in the digital age.