Introducing Precise Camera Angles in AI-Generated Images
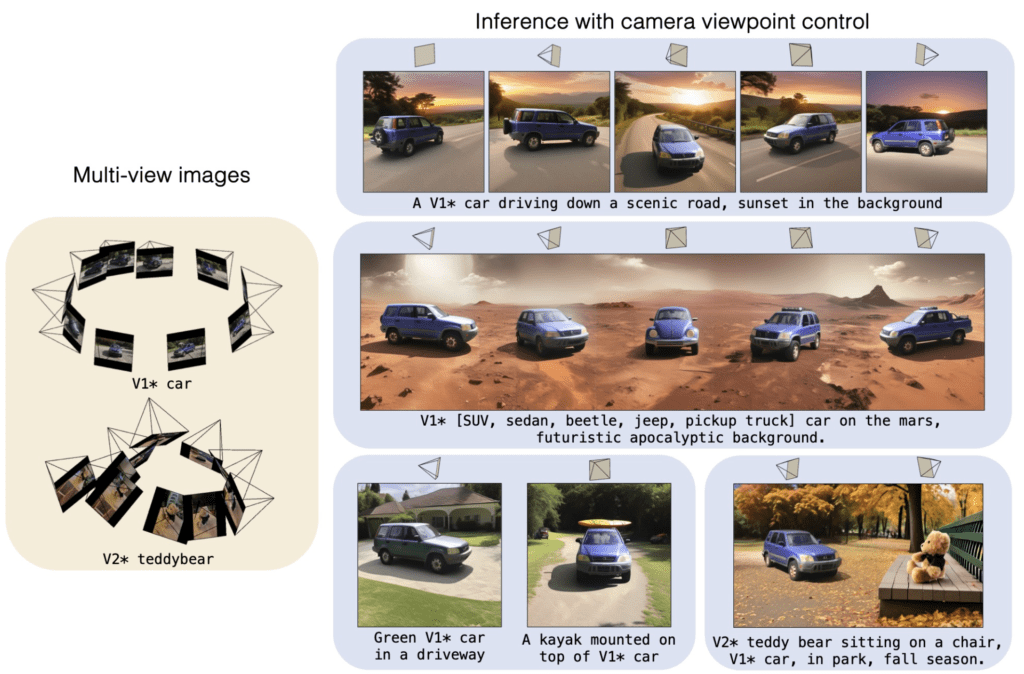
- Enhanced Viewpoint Customization: Adobe’s new method allows for explicit control of the camera viewpoint in text-to-image models, enhancing the customization of object properties across various scenes.
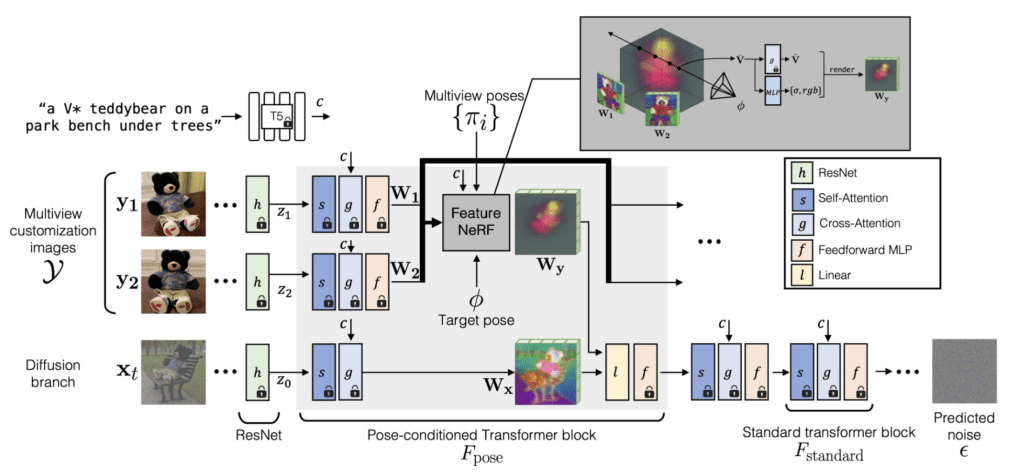
- Complex Integration of 3D and 2D Models: The approach combines 3D feature predictions with 2D diffusion models, enabling the generation of images with precise object poses and contextual adherence.
- High Dependency on Extensive Datasets: Effective utilization of this technology requires a substantial dataset of about 50 multi-view images per object to accurately render from various angles.
Adobe has introduced a groundbreaking enhancement to text-to-image generative models by incorporating camera viewpoint control, a feature that significantly elevates the flexibility and application of AI in image generation. This innovation allows users to specify camera angles directly through text prompts, leading to more precise and contextually appropriate image outputs.
Technical Implementation and Capabilities
Adobe’s methodology starts with a variant of the Stable Diffusion model, conditioned to integrate view-dependent features from 3D models into the 2D image generation process. This is achieved by adapting the diffusion process to include rendered, view-specific attributes of objects, thus maintaining their identity and geometric consistency across different scenes. The training process involves a fine-tuning approach where 3D feature prediction modules and 2D diffusion attention modules are jointly adapted to achieve this integration.

Performance and Applications
The new method outperforms traditional image editing and model personalization techniques, especially in preserving the object’s identity while accurately following the detailed text prompts and specified camera poses. This capability is particularly useful in industries such as digital marketing, film production, and virtual reality, where precise visual representations from specific angles are crucial.
Challenges and Future Directions
Despite its advantages, the method has limitations, particularly in handling extreme camera angles not encountered during training, which can lead to inaccuracies in object identity or pose. Additionally, the model tends to generate predominantly front views, a bias introduced by the training datasets typically used. Future enhancements will focus on including a broader range of camera angles and exploring zero-shot learning techniques to reduce reliance on extensive finetuning.

Adobe’s introduction of camera viewpoint control in text-to-image models represents a significant technological advancement, offering new possibilities for creators and developers in generating highly customized visual content. As this technology evolves, it promises to further bridge the gap between AI-generated imagery and real-world photographic accuracy.