How a new modular framework is transforming LLMs from passive text generators into autonomous, decision-making agents capable of mastering the real world.
- The Shift to Autonomy: Current agent training relies on rigid, human-designed workflows, but Agent-R1 introduces an end-to-end Reinforcement Learning (RL) paradigm that treats environments as interactive and unpredictable rather than passive.
- Redefining the Framework: The research successfully extends the Markov Decision Process (MDP) to handle stochastic state transitions—incorporating tool use, memory history, and environmental feedback into the learning process.
- Superior Performance: Agent-R1 dramatically outperforms traditional RAG baselines (by over 2.5x) and demonstrates that precise credit assignment mechanisms are critical for training agents that can reason across multiple turns.
It is a well-established fact that Reinforcement Learning (RL) works exceptionally well for optimizing Large Language Models (LLMs) in deterministic domains like mathematics and coding. However, training agents—systems designed to interact with the world to solve problems—is a different story entirely.
The default approach to training LLM agents today relies heavily on methods like ReAct-style reasoning loops, human-designed workflows, and fixed tool-calling patterns. While functional, these methods suffer from a fundamental flaw: they treat the environment as passive.
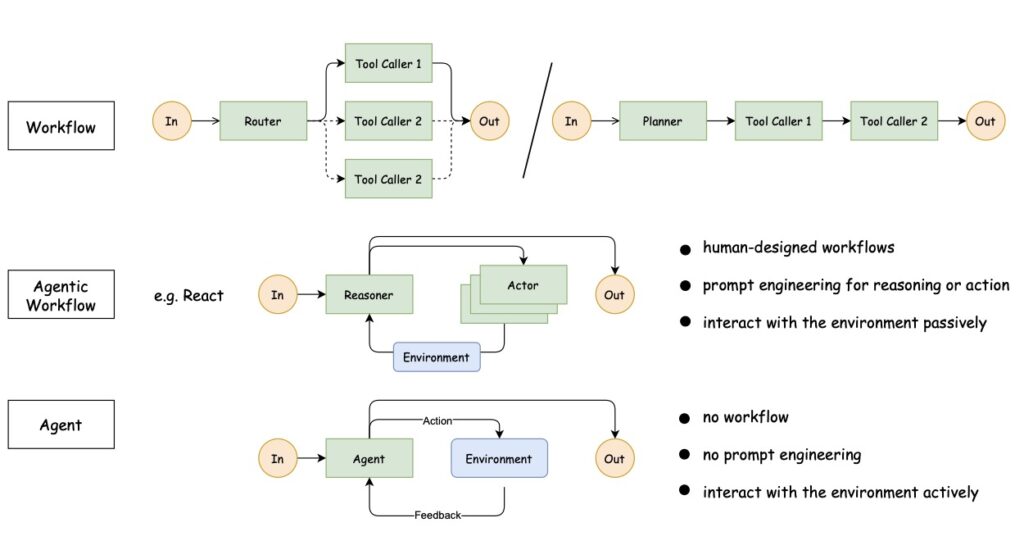
In the real world, an agent cannot rely on a linear script. It must make sequential decisions, maintain memory across dialogue turns, and adapt to stochastic (random or unpredictable) environmental feedback. As agents evolve from predefined workflows to autonomous interaction, the current paradigms are insufficient. This capability gap represents the next frontier in Artificial Intelligence.
Enter Agent-R1: A “Big Deal” for Autonomous AI
A new research paper, Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning, addresses this gap head-on. The researchers argue that the complexities of real-world interaction are fundamentally an RL problem.
Agent-R1 provides a modular, flexible foundation for scaling RL to complex, tool-using LLM agents. By moving away from static reasoning tasks to dynamic environments, this framework brings us closer to general artificial intelligence with self-evolving and problem-solving capabilities.
The Technical Leap: From Deterministic to Stochastic
To understand why Agent-R1 is innovative, one must look at how it changes the rules of the game regarding state transitions.
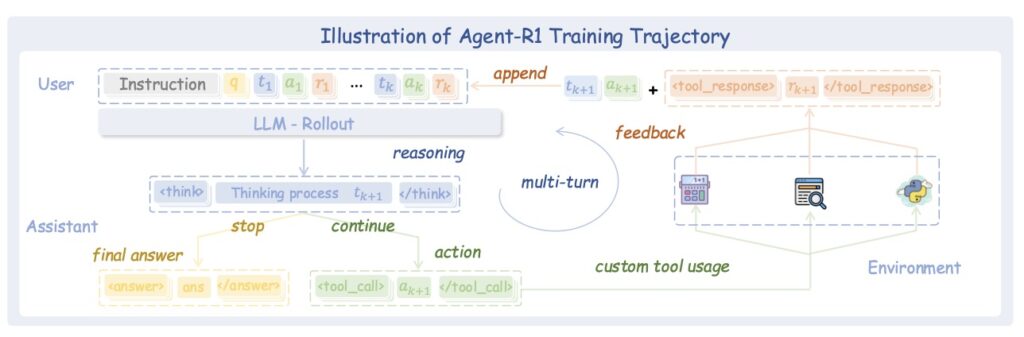
Standard RL for LLMs assumes deterministic state transitions: the model generates a token, appends it to the sequence, and the state is updated. It is a closed loop. However, when an agent triggers an external tool (like a search engine or a calculator), the outcome is uncertain. The environment responds unpredictably.
Agent-R1 extends the classic Markov Decision Process (MDP) framework to capture this complexity:
- Expanded State Space: The state now includes the full interaction history and external environmental feedback, not just the text sequence.
- Complex Actions: Actions can trigger external tools, not just generate text.
- Dense Rewards: The system utilizes process rewards for intermediate steps alongside final outcome rewards.
The Mechanisms of Success
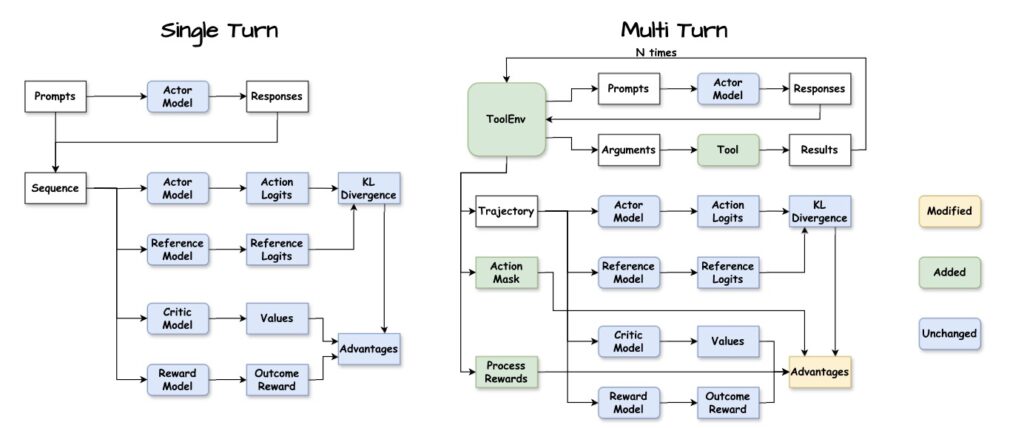
Two core mechanisms enable Agent-R1 to function effectively:
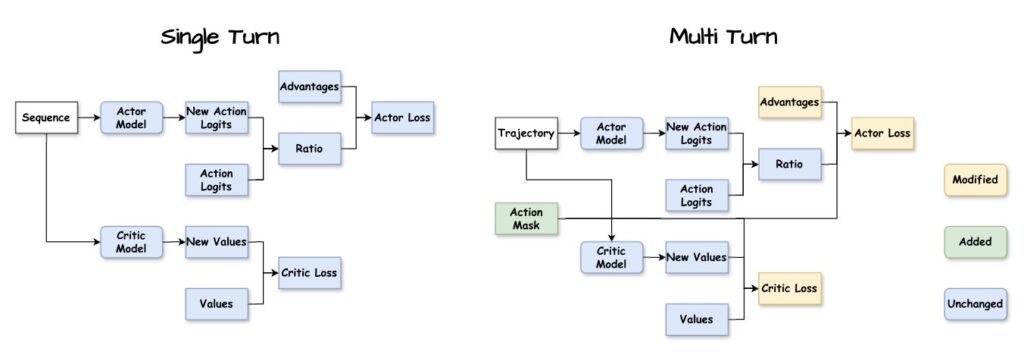
- The Action Mask: This critical component distinguishes between agent-generated tokens and environmental feedback. It ensures that credit assignment—the process of determining which action led to a reward—targets only the agent’s actual decisions, not the environment’s response.
- The ToolEnv Module: This manages the interaction loop, handling the stochastic state transitions and calculating rewards when tools are invoked.
Crushing the Baselines
The effectiveness of Agent-R1 was validated through experiments on multi-hop question answering—a task requiring reasoning, memory, and sequential tool use. The results were stark.
RL-trained agents dramatically outperformed standard baselines. Even the weakest RL algorithm tested (REINFORCE++) beat naive Retrieval-Augmented Generation (RAG) by 2.5x on average Exact Match (EM) scores.
The more advanced GRPO algorithm achieved an average EM of 0.3877, compared to a meager 0.1328 for RAG.
Why Design Matters: The Ablation Studies
The research also confirmed that the specific architecture of Agent-R1 is essential. When researchers disabled the advantage mask (a component of the Action Mask), performance using PPO dropped from 0.3719 to 0.3136. Disabling the loss mask caused further degradation to 0.3022.
These statistics prove that precise credit assignment is not just a “nice to have”—it is essential for multi-turn learning. Without it, the agent cannot effectively learn which specific actions led to success within a long, complex interaction.
Agent-R1 represents a significant step forward in the field of agentic AI. by clarifying how Reinforcement Learning can be applied to multi-turn interactions and providing a modular framework to do so, this research paves the way for agents that are not just smart, but truly adaptive.
As we move toward systems that must act autonomously and learn continuously, end-to-end RL frameworks like Agent-R1 will likely become the standard for building the next generation of intelligent systems.