How the Very Big Video Reasoning suite is shifting the AI frontier from visual realism to spatiotemporal intelligence.
- Bridging the Gap: While AI has mastered textual reasoning and visual realism, the “missing link” is spatiotemporal reasoning—the ability to understand causality, interaction, and physics within a video.
- Massive Scale: The introduction of the Very Big Video Reasoning (VBVR) Dataset provides over one million video clips across 200 tasks, offering a resource three orders of magnitude larger than previous datasets.
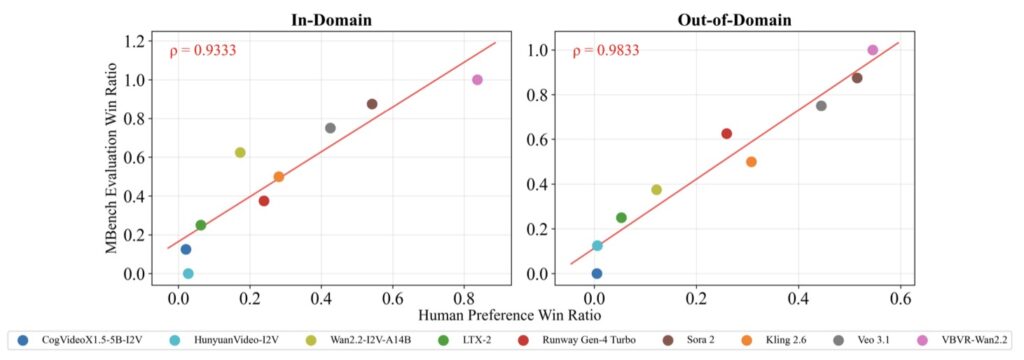
- Verifiable Progress: Through VBVR-Bench, the suite introduces a rule-based evaluation framework that allows for reproducible, human-aligned diagnosis of how models actually “think” about moving images.

For years, the gold standard of Artificial Intelligence has been defined by the meteoric rise of Large Language Models (LLMs). By 2025 and 2026, we have seen these models generalize across complex domains like advanced mathematics, coding, and scientific discovery. However, this intelligence has remained largely “trapped” in a text-based world. On the flip side, video generation models have become incredibly adept at creating visually stunning imagery, yet they often lack a fundamental understanding of the world they depict. They can draw a falling glass, but do they understand the gravity, the impact, and the resulting shatter?

This gap highlights the urgent need for video reasoning: the ability to ground intelligence in spatiotemporally consistent environments. Unlike static images or text, video requires an intuitive grasp of continuity, interaction, and causality. To move toward true general intelligence, AI must learn to reason within the physical world’s temporal flow.
Scaling the Unscalable: The VBVR Dataset
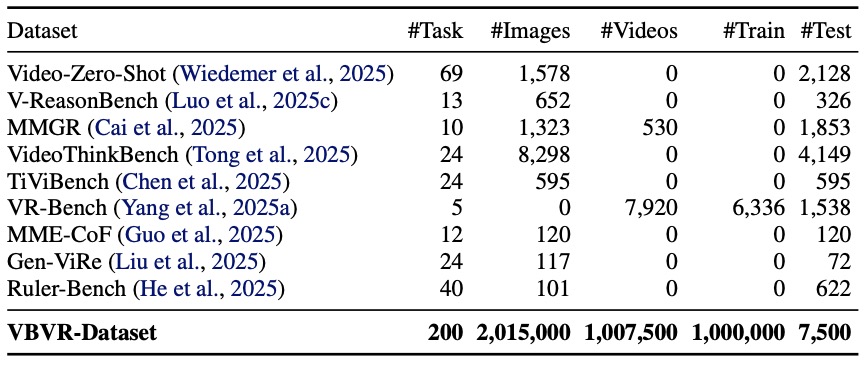
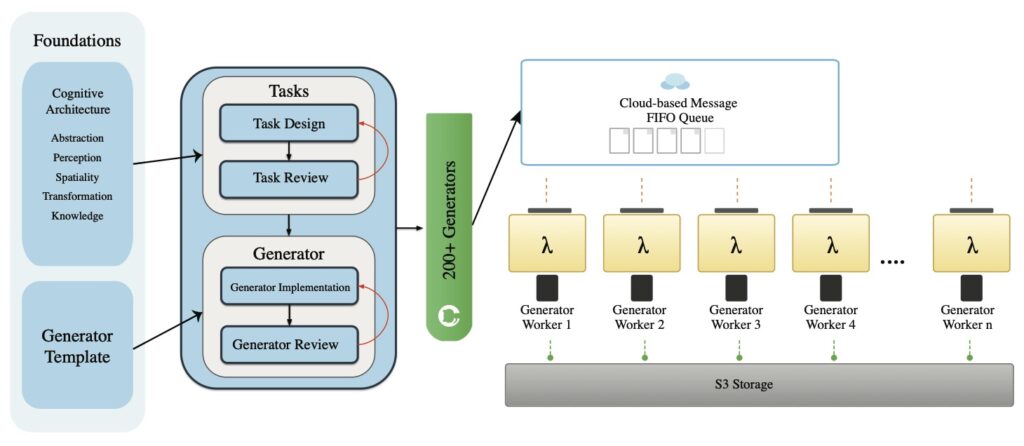
The primary obstacle to progress in this field has been a lack of data. Systematic study of scaling behavior—how a model gets smarter as it gets bigger—requires massive, diverse datasets that simply didn’t exist for video logic. Enter the Very Big Video Reasoning (VBVR) Dataset.
This unprecedented resource spans 200 curated reasoning tasks following a rigorous, principled taxonomy. By providing over one million video clips, the VBVR suite is approximately three orders of magnitude larger than existing benchmarks. This scale allows researchers to move beyond niche applications and finally investigate how video models can be trained to understand the “why” behind the “what” in a scene, from simple physical dynamics to complex long-range causality.

Evaluating Truth in Motion
Data alone is not enough; we also need a yardstick that doesn’t move. Previous evaluation methods often relied on other models to “judge” a video model’s performance, leading to a circular logic that was difficult to verify. To solve this, the suite includes VBVR-Bench, a verifiable evaluation framework.
By incorporating rule-based, human-aligned scorers, VBVR-Bench ensures that assessments are both reproducible and interpretable. It moves the industry away from “vibes-based” grading toward a diagnostic approach that can pinpoint exactly where a model’s reasoning breaks down—whether it’s a failure to track an object over time or a misunderstanding of a physical interaction.
Emergent Generalization and the Future
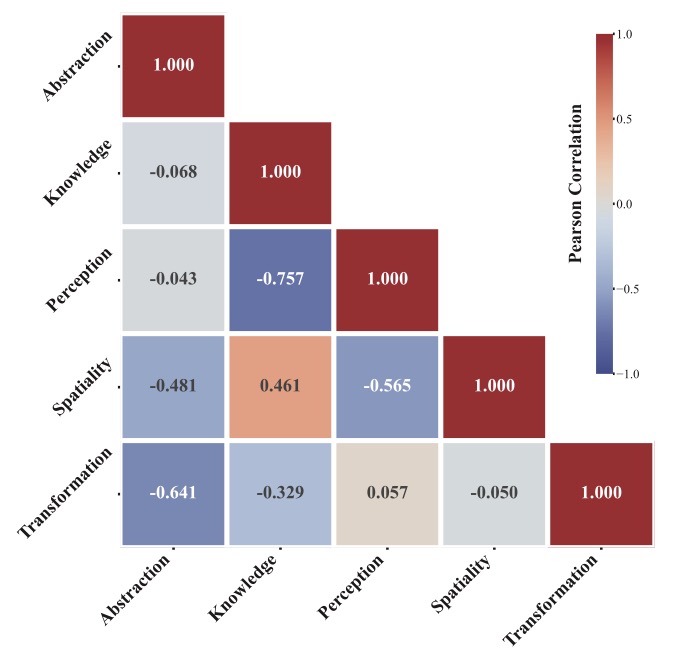
Perhaps the most exciting outcome of the VBVR suite is the initial scaling study it has enabled. For the first time, researchers have observed early signs of emergent generalization in video reasoning. Much like LLMs suddenly gained the ability to “reason” when they reached a certain size, video models are starting to show the ability to handle unseen reasoning tasks as they scale.
Together, the VBVR-Dataset and VBVR-Bench lay the foundation for the next generation of AI. By grounding intelligence in the physical and temporal structure of video, we are moving closer to models that don’t just mimic the world, but actually understand how it works.