Ditching massive contrastive pretraining for LLM-initialized vision encoders to unlock unprecedented efficiency on edge devices.
- A Shift from Scaling to Structure: Penguin-VL proves that compact models (2B and 8B parameters) can match or beat massive state-of-the-art Vision Language Models (VLMs) by prioritizing better visual representation over sheer scale.
- The LLM-Initialized Advantage: By initializing its vision encoder from a text-only LLM rather than using traditional contrastive pretraining, Penguin-VL preserves the fine-grained spatial and temporal cues essential for complex reasoning.
- A Stepping Stone to Autonomous Agents: Future developments will pivot towards real-time inference optimization, Reinforcement Learning (RL) post-training, and evolving the model into a fully agentic system capable of dynamic computer and GUI navigation.
The integration of robust visual perception into Large Language Models (LLMs) has yielded extraordinary multimodal capabilities. Recent heavyweights like Qwen3-VL, Intern-VL, and the Molmo series have demonstrated that pairing strong LLMs with modality-specific encoders creates impressive general-purpose AI. However, a glaring gap remains between these state-of-the-art research prototypes and practical, real-world deployment.
In the real world—especially on compute-constrained mobile devices, smartphones, and robots—the goal is rarely “the strongest model possible at any cost.” Instead, developers need compact, efficient models that remain reliably strong across modalities. Currently, leading VLMs rely on massive parameter counts and heavy training pipelines, complicating deployment under strict latency constraints and often resulting in uneven performance across image and video tasks.
Enter Penguin-VL, a compact, vision-centric multimodal foundation model that fundamentally challenges how we build VLMs from the ground up.
The Problem with Contrastive Pretraining
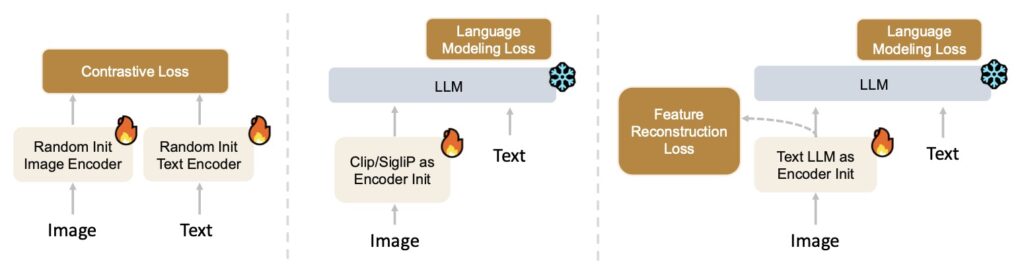
Historically, VLM development has relied heavily on scaling model size and initializing vision encoders through massive contrastive pretraining (such as CLIP or SigLIP). However, this prevailing practice harbors a critical flaw: an objective mismatch.
Contrastive learning is optimized for discrimination. It enforces coarse, category-level invariances that are great for basic image sorting but actively suppress the fine-grained visual cues needed for dense captioning and complex VLM reasoning. When a model optimized this way attempts complex tasks, it often struggles—for example, a model tuned for static image understanding might fail completely at video temporal reasoning.
The Penguin-Encoder: A Head Start on Reasoning
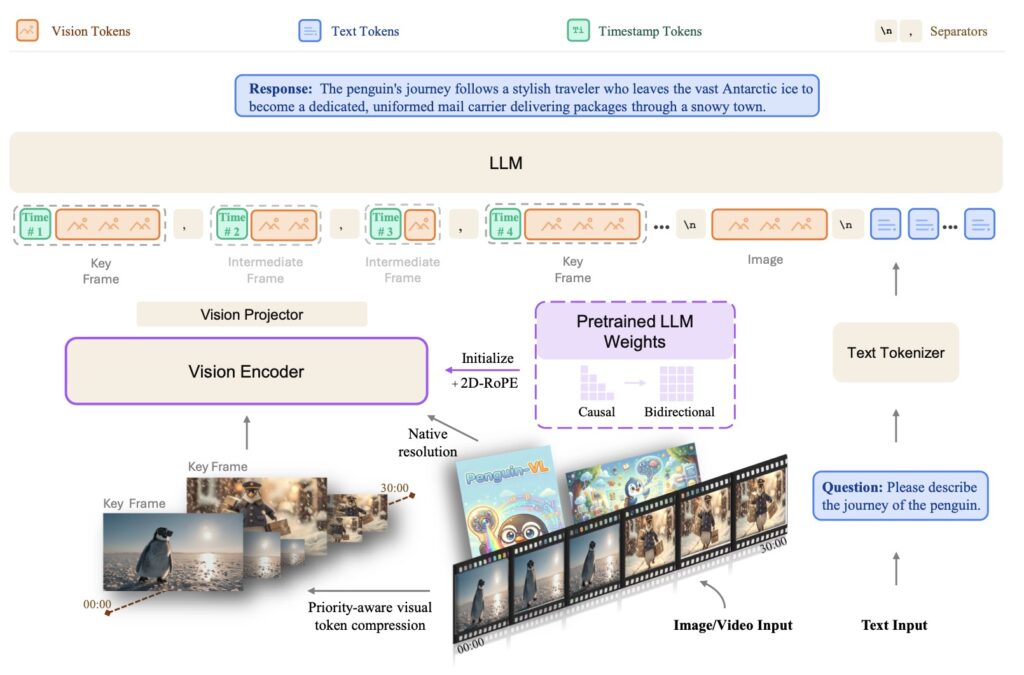
To solve this objective mismatch, the researchers behind Penguin-VL introduced the Penguin-Encoder. Instead of relying on a contrastive vision model, the Penguin-Encoder is initialized directly from a text-only LLM architecture (specifically starting from Qwen3-0.6B).
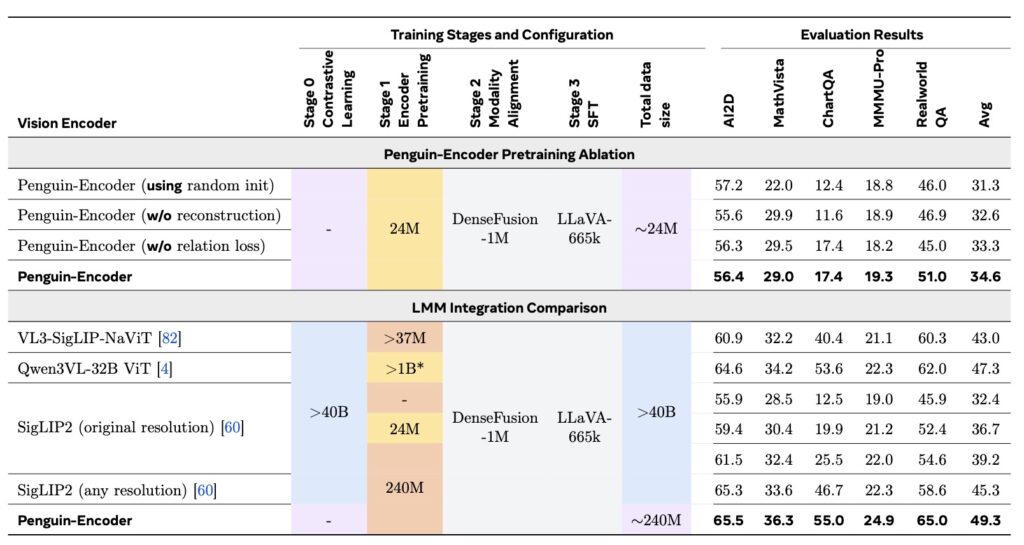
This LLM-initialization gives the vision encoder a massive head start. By starting closer to the decoder’s feature space, Penguin reuses pretrained attention and Feed-Forward Network (FFN) layers, transferring sequence-modeling priors directly into image patch understanding. With minimal adaptations—such as 2D-RoPE (Rotary Position Embedding) and bidirectional attention—the encoder doesn’t have to relearn what ordering, context, and causal composition look like from scratch. It simply learns how high-fidelity visual features should map into a mature, language-side reasoning pipeline.

A First-Principles Training Pipeline
This architecture is supported by a robust, three-stage training pipeline designed to keep fine-grained spatial and temporal information available long enough for the reasoning engine to actually use it:
- Encoder Training: Adapting the Qwen3 text backbone into the Penguin-Encoder.
- VLM Pretraining: Training the full model to align visual and linguistic features.
- Supervised Fine-Tuning (SFT): Refining the model’s instruction-following and task-specific performance alongside highly effective data curation strategies for open-source datasets.
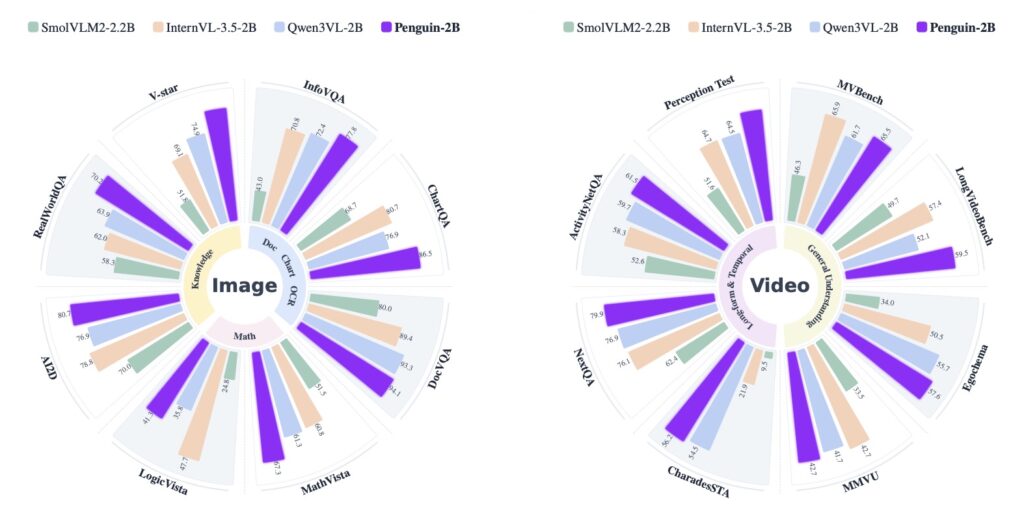
Across various benchmarks, the results are staggering. Penguin-VL achieves performance comparable to leading models like Qwen3-VL in mathematical reasoning, and actually surpasses them in tasks like document understanding (OCR), visual knowledge, and multi-perspective video understanding. Notably, these gains are achieved with a highly lightweight 2B to 8B architecture, proving that aligning a vision encoder’s initialization with an LLM’s generative objectives is a vastly superior path than simply scaling up disconnected contrastive models.
The Road Ahead: From Perception to Action
Building on these foundations, the future of Penguin-VL points toward highly interactive and autonomous applications:
- Real-time Inference Optimization: Real-world applications—like embodied agents and assistive systems—require adaptive computation under strict time constraints. Future iterations will explore early exiting, token/region-level sparsity, and dynamic resolution to allow the model to trade accuracy for latency on demand. Incremental streaming, where visual data is updated continuously rather than recomputed, alongside hardware-aware on-device distillation, will be critical.
- Advanced Post-Training Techniques (RL): While Supervised Fine-Tuning provides a strong baseline, it relies on static annotations. The next frontier is Reinforcement Learning (RL) post-training. By optimizing VLMs using task-level rewards and trial-and-error interaction, models can better handle long-horizon objectives and implicit user preferences, moving from simple text generation to robust decision-making.
- Agentic Visual-Language Systems: The ultimate application is extending Penguin-VL into dynamic graphical environments. By grounding visual understanding in actionable affordances, the model will be able to robustly perceive UI elements, track state changes, and execute multi-step interactions. This will pave the way for powerful GUI agents capable of autonomous computer use.
Penguin-VL proves that the future of multimodal AI isn’t necessarily bigger—it’s smarter, better structured, and deeply integrated.