Overcoming the limits of 2D AI models to create hyper-realistic, view-consistent videos for gaming, e-commerce, and beyond.
- The 2D Trap of Current AI: Existing video generation models struggle with real-world 3D objects, relying on 2D visual features that force the AI to hallucinate unseen angles, leading to visual inconsistencies and temporal overfitting.
- A Paradigm Shift in Optimization: 3DreamBooth solves this by decoupling an object’s spatial geometry from its temporal motion, utilizing a unique 1-frame optimization process to bake a robust 3D prior directly into the model.
- Unmatched Fidelity with 3Dapter: By pairing 3DreamBooth with a visual conditioning module called 3Dapter, the framework dynamically routes geometric hints to preserve intricate, fine-grained textures from every angle, achieving state-of-the-art results.

Imagine a product designer who has just finalized the look of a revolutionary new sneaker. To showcase this product in a dynamic advertisement, they need footage of the shoe rotating, traversing various terrains, and shining under diverse lighting conditions. Traditionally, capturing this requires exhaustive, expensive filming sessions across multiple physical environments. Or, consider a game developer tasked with animating a custom character across dozens of diverse scenes while maintaining strict visual consistency.
Ideally, creators should be able to capture a subject just once and let a generative system seamlessly place it into any scene, from any viewpoint, and in any motion context. This high demand spans across emerging applications like immersive VR/AR, virtual production, and next-generation e-commerce. However, realizing this vision requires a system that not only understands what a subject looks like but also deeply grasps its underlying 3D structure.
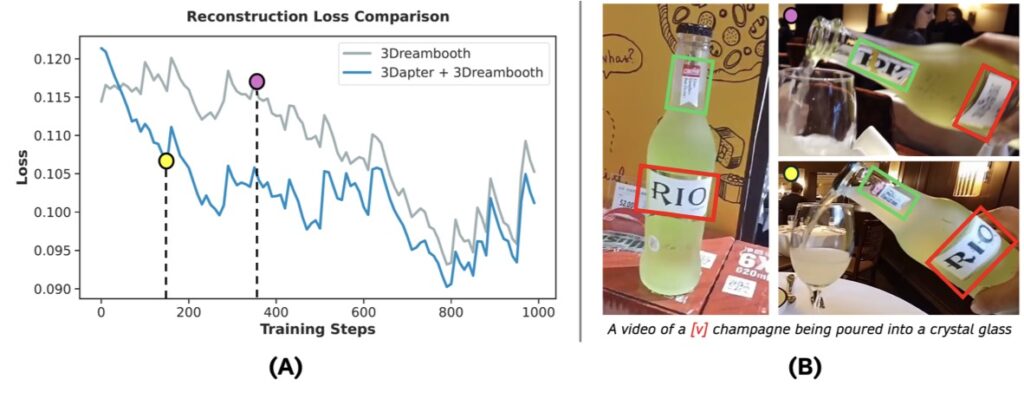
The Fundamental Flaw in Subject-Driven Video
Despite the rapid and impressive progress in subject-driven AI video generation, a fundamental limitation has held the technology back: existing methods overwhelmingly treat subjects as 2D entities. These models focus on transferring identity through single-view visual features or simple textual prompts.
Because real-world subjects are inherently 3D, applying these 2D-centric approaches to 3D object customization simply doesn’t work. The models lack the comprehensive spatial priors necessary to reconstruct accurate 3D geometry. Consequently, when asked to synthesize novel views—like the back of that new sneaker or the side profile of a game character—the AI is forced to guess. It generates plausible but entirely arbitrary details for those unseen regions, failing to preserve the object’s true 3D identity.
Furthermore, achieving genuine 3D-aware customization is notoriously difficult due to the scarcity of multi-view video datasets. If developers attempt to force the issue by fine-tuning models on the limited video sequences available, the system inevitably falls victim to “temporal overfitting”—where the model simply memorizes the specific video sequence rather than learning how the object should move and look in a new context.
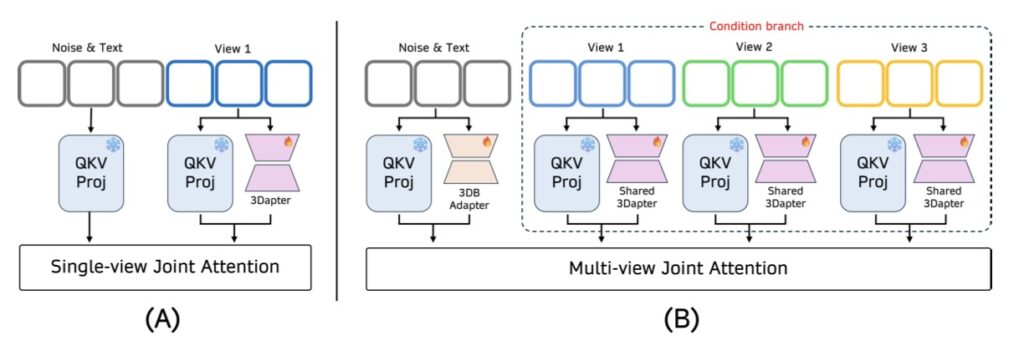
3DreamBooth: Decoupling Space and Motion
To resolve these deeply rooted issues, a highly efficient and novel framework has emerged: 3DreamBooth, paired with its companion module, 3Dapter.
3DreamBooth tackles the core problem by entirely decoupling spatial identity from temporal motion. It achieves this through an innovative 1-frame optimization paradigm. By restricting the AI’s updates strictly to spatial representations, 3DreamBooth effectively bakes a robust, subject-specific 3D prior into the model. This means the system learns the true volume and shape of the object without the need for exhaustive, video-based training, neatly bypassing the trap of temporal overfitting.
3Dapter: The Secret to High-Fidelity Textures
Understanding the shape of an object is only half the battle; capturing its complex, fine-grained textures is equally crucial. This is where 3Dapter, a specialized visual conditioning module, comes into play.
Designed to accelerate convergence and enhance visual fidelity, 3Dapter undergoes single-view pre-training before entering a multi-view joint optimization phase with the main generation branch. It utilizes a clever asymmetrical conditioning strategy that allows the module to act as a dynamic selective router. In plain terms, 3Dapter intelligently queries view-specific geometric hints from a very minimal set of reference images. It actively extracts the exact geometric features needed for whatever angle the video is currently showing, ensuring that intricate textures are preserved flawlessly.
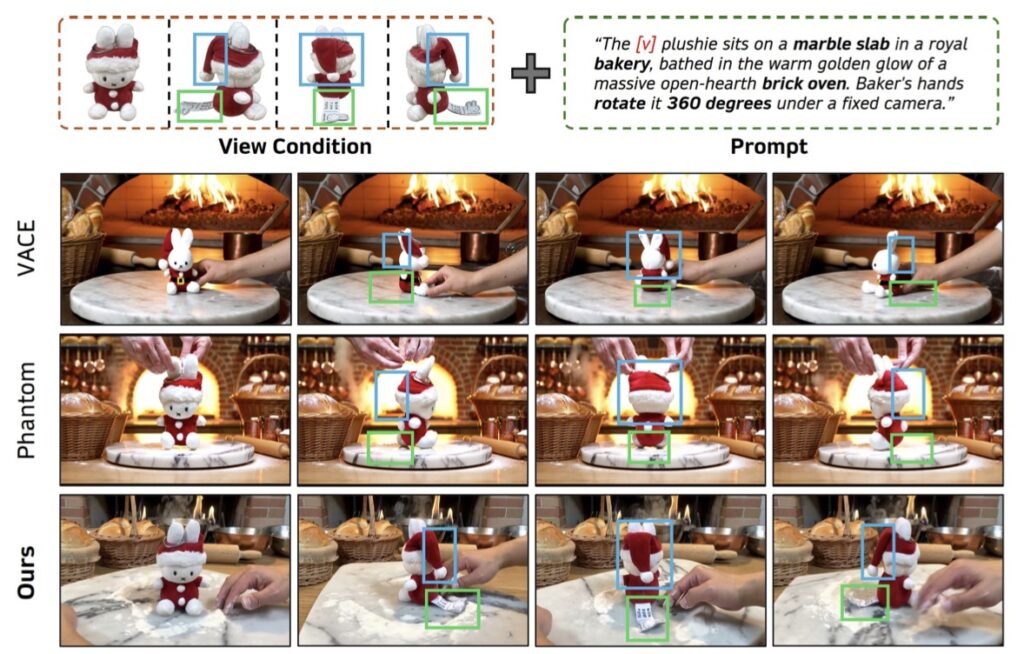
Paving the Way for the Future of Virtual Production
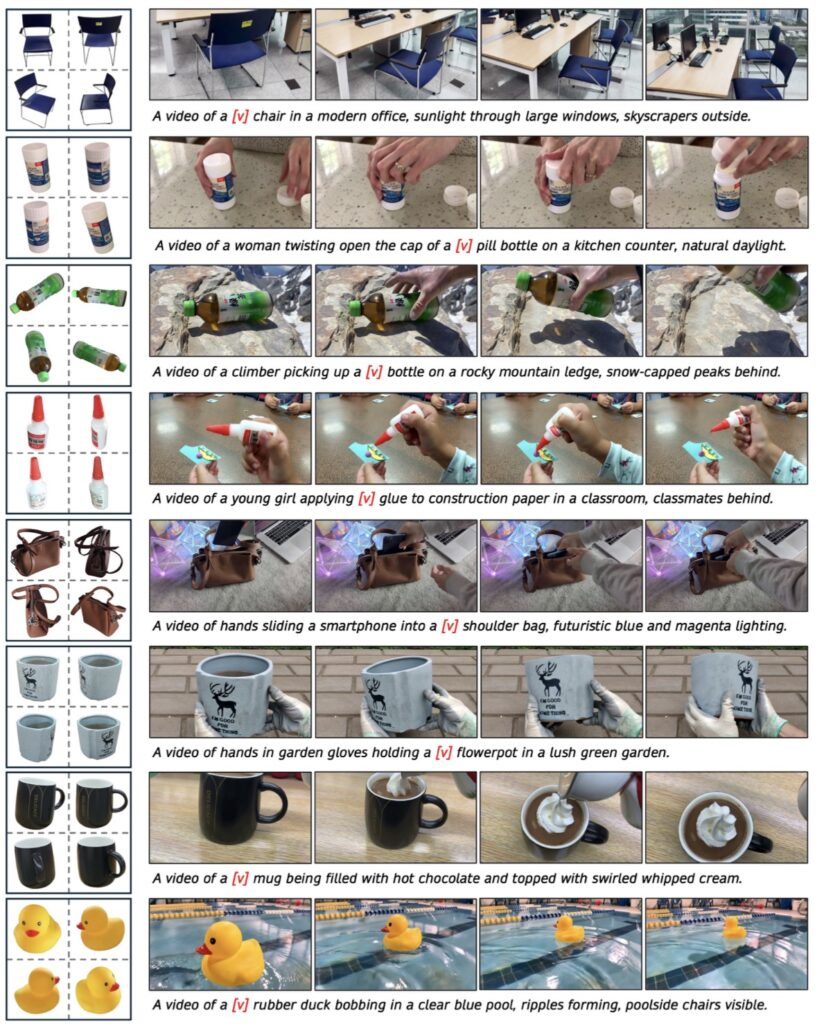
The synergy between 3DreamBooth’s 1-frame optimization and 3Dapter’s dynamic routing represents a massive leap forward. Extensive quantitative and qualitative evaluations on the curated 3D-CustomBench demonstrate that this framework achieves state-of-the-art 3D geometric fidelity while maintaining computational efficiency.
By finally giving AI a true understanding of 3D space, 3DreamBooth is breaking down the walls between static 2D images and dynamic, immersive virtual worlds. It promises a future where generating a high-fidelity, computationally efficient, and perfectly consistent 3D video is as simple as providing a single reference and letting the model do the heavy lifting.
