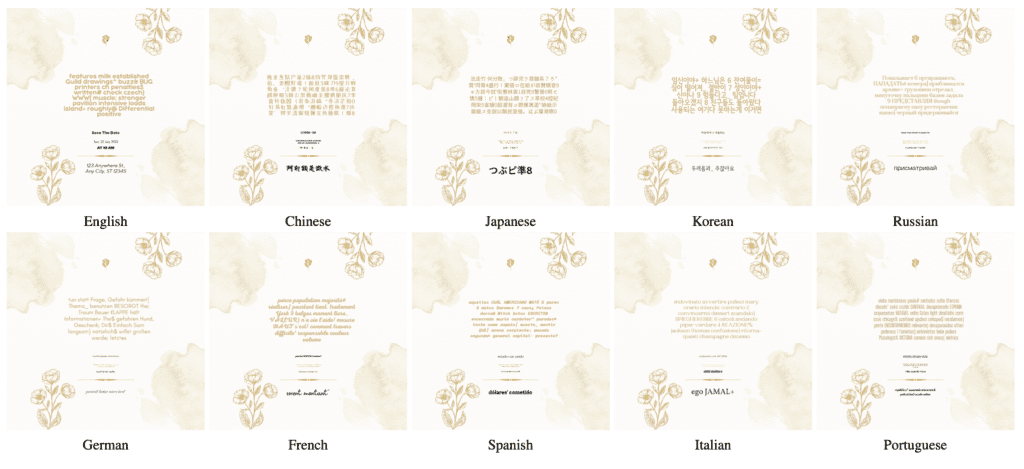
The breakthrough in visual text rendering supports 10 languages with improved aesthetic quality
- Multilingual Capability: Glyph-ByT5-v2 and Glyph-SDXL-v2 accurately render text in 10 languages.
- Enhanced Aesthetics: The models significantly improve the visual appeal of rendered text.
- Comprehensive Datasets: Creation of high-quality multilingual glyph and graphic design datasets to train the models.
In the rapidly evolving world of AI-driven graphic design, the ability to render visually appealing and accurate text in multiple languages has become a crucial benchmark. Addressing this challenge, the latest advancements in the field have been marked by the introduction of Glyph-ByT5-v2 and Glyph-SDXL-v2. These models represent a significant leap forward, not only supporting accurate visual text rendering for ten different languages but also achieving a superior level of aesthetic quality.

Overcoming Language Barriers in Visual Text Rendering
Until now, most text-to-image generation models, including popular names like DALL·E3, Midjourney-v6, and Ideogram 1.0, have primarily focused on English. This limitation has posed significant challenges in rendering text in other languages, particularly those with complex scripts like Chinese, Japanese, and Korean. Glyph-ByT5-v2 and Glyph-SDXL-v2 aim to bridge this gap by introducing robust multilingual support.

Key Contributions
1. High-Quality Multilingual Datasets: To achieve accurate multilingual text rendering, the developers created a comprehensive dataset consisting of over one million glyph-text pairs and ten million graphic design image-text pairs. This dataset spans nine additional languages beyond English, providing a rich resource for training the new models.
2. Multilingual Visual Paragraph Benchmark: The team also developed a multilingual visual paragraph benchmark with 1,000 prompts (100 per language). This benchmark is designed to assess the models’ ability to render text with visual and spelling accuracy across different languages.
3. Step-Aware Preference Learning: By leveraging step-aware preference learning, the models enhance the visual aesthetic quality of the generated images. This technique involves post-training optimization that aligns with human visual preferences, resulting in images that are not only accurate but also visually pleasing.
The Technology Behind Glyph-ByT5-v2 and Glyph-SDXL-v2
The foundation of these advancements lies in the innovative use of a Multi-modal Feature Connector. This mechanism effectively integrates text and supplementary modal information using a special attention mechanism. By freezing all parameters in the original T2I diffusion model and only adjusting additional layers, the pre-trained model can seamlessly accept multi-modal prompts.
Practical Applications and Future Directions
The implications of this technology are far-reaching. The ability to accurately render text in multiple languages opens up new possibilities in global graphic design, advertising, and content creation. For instance, companies can now create visually consistent marketing materials in various languages without compromising on quality or aesthetics.

Moreover, the creation of these high-quality datasets sets a new standard for future research and development in the field. The techniques used in Glyph-ByT5-v2 and Glyph-SDXL-v2 could be applied to other areas of AI-driven content creation, pushing the boundaries of what is possible with generative models.
Glyph-ByT5-v2 and Glyph-SDXL-v2 mark a significant advancement in the field of text-to-image generation, addressing two critical limitations of their predecessors: language support and visual appeal. By creating comprehensive multilingual datasets and leveraging advanced learning techniques, these models set a new benchmark for the industry. As the technology continues to evolve, we can expect even more sophisticated and user-friendly tools for multilingual and multi-modal content creation, driving innovation and accessibility in the digital age.
