Bridging the gap between frontier-level reasoning and real-world computational agility.
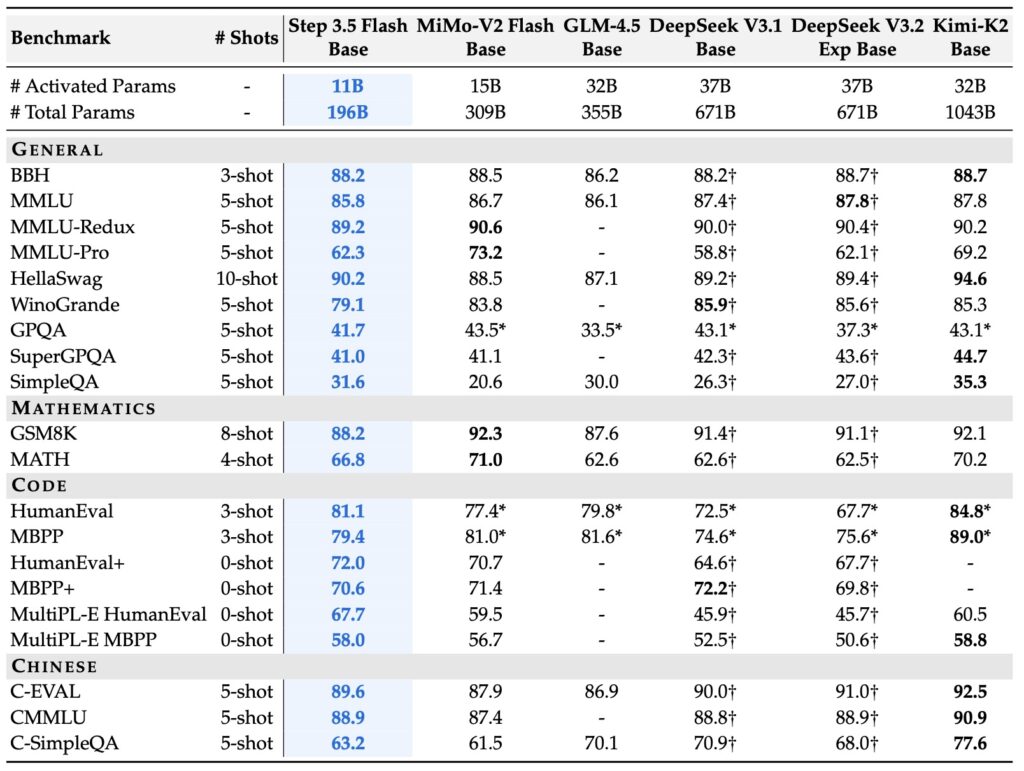
- Frontier Power, Compact Core: Step 3.5 Flash utilizes a sparse Mixture-of-Experts (MoE) architecture to provide the reasoning depth of a 196B-parameter foundation while activating only 11B parameters for lightning-fast inference.
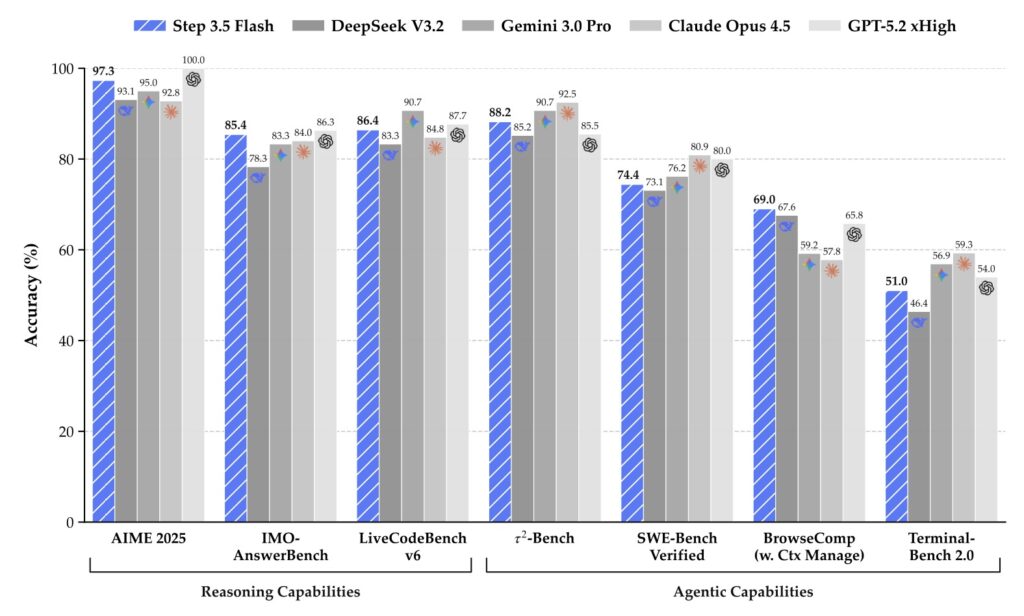
- Built for Action: Engineered specifically for “agentic” intelligence, the model achieves elite scores in coding (86.4% on LiveCodeBench) and math (85.4% on IMO-AnswerBench), rivaling closed-source giants like GPT-5.2 xHigh.
- Industrial-Grade Reliability: Through a scalable RL framework and expert-distilled benchmarks, the model ensures stable, verifiable performance in complex data analysis and professional advisory scenarios.
The landscape of Artificial Intelligence is currently caught in a tug-of-war between two opposing forces: the need for massive, frontier-level reasoning and the practical requirement for low-latency, cost-effective execution. For developers building autonomous agents, this “efficiency gap” has long been a barrier to deployment. Step 3.5 Flash emerges as the definitive solution to this paradox, redefining the “intelligence density” of open-source models by delivering high-fidelity modeling without the traditional computational tax.
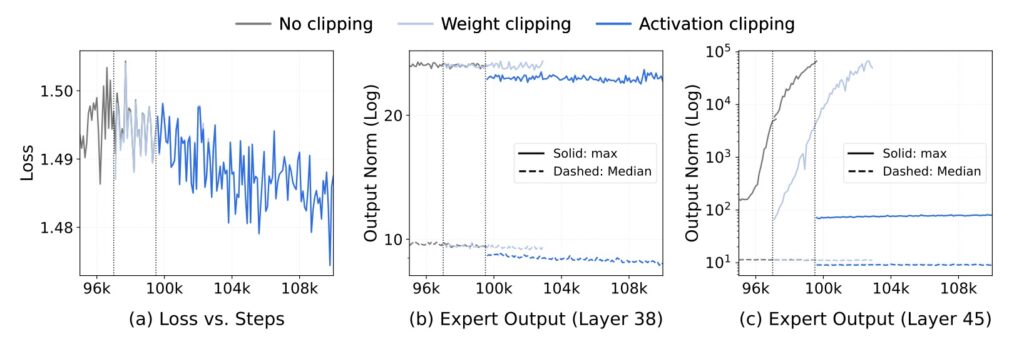
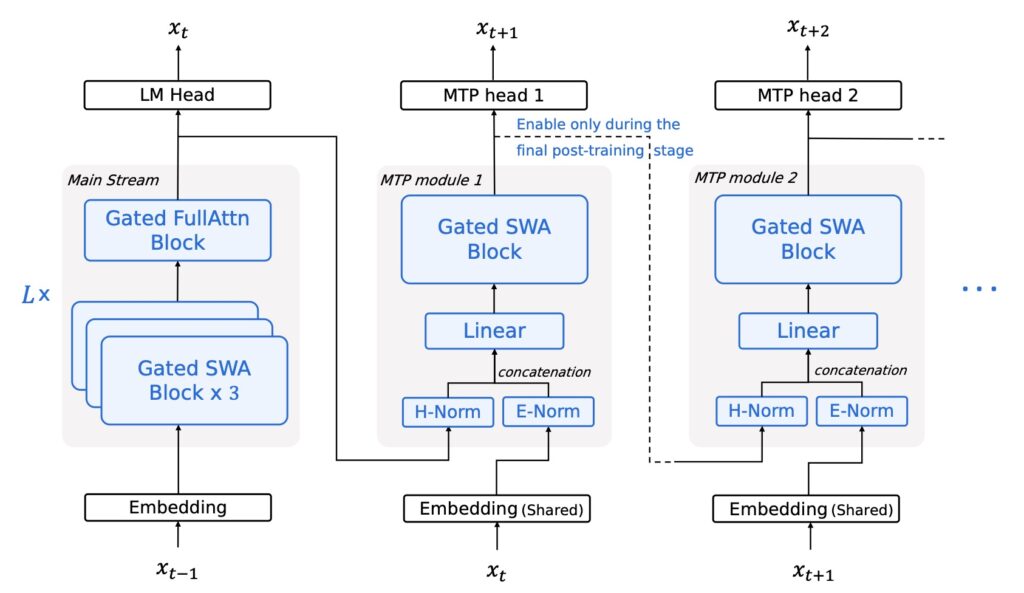
At the heart of Step 3.5 Flash is a sophisticated sparse Mixture-of-Experts (MoE) architecture. While the model boasts a massive 196B-parameter foundation to capture nuanced global knowledge, it intelligently activates only 11B parameters per token during inference. This selective activation is paired with an innovative 3:1 Sliding Window/Full Attentionmechanism and Multi-Token Prediction (MTP-3). The result is a model that doesn’t just “read” like a chatbot but “reasons” like an agent, achieving generation speeds of up to 350 tokens per second—crucial for the iterative, multi-round interactions required in modern software engineering and data science.
To ensure this speed doesn’t come at the cost of accuracy, the developers implemented a scalable Reinforcement Learning (RL) framework. This framework integrates verifiable signals and human preference feedback to drive self-improvement across mathematics, code, and tool use. The results speak for themselves: Step 3.5 Flash achieved an 85.4% on IMO-AnswerBench and a staggering 86.4% on LiveCodeBench-v6. In practical agentic environments, it holds its own against industry titans, scoring 88.2% on τ2-Bench, a performance tier previously reserved for models like Gemini 3.0 Pro.
Beyond raw benchmarks, Step 3.5 Flash is grounded in the “tacit expertise” of industry veterans. To validate its utility in professional settings, it was tested against a new Data Analysis Benchmark developed in collaboration with senior leaders from major tech firms. This benchmark uses a rubric-grounded evaluation suite to simulate real-world business constraints and ambiguous analytical tasks. Whether it is following complex instructions, maintaining a professional tone, or ensuring logical coherence without hallucinations, Step 3.5 Flash proves that it can handle the messiness of human professional life.
Finally, Step 3.5 Flash is designed for the modern privacy-conscious enterprise. With a 256K context window and the ability to run on high-end consumer hardware like the Mac Studio M4 Max, it brings elite intelligence out of the cloud and into local, secure environments. By prioritizing what matters most—sharp reasoning, fast execution, and verifiable reliability—Step 3.5 Flash stands as the new open-source foundation for the next generation of industrial AI agents.