Moving beyond multiple-choice to master the art of open-ended medical dialogue.
- Open-Ended Innovation: MediX-R1 introduces a reinforcement learning framework that allows AI to move past simple A/B/C answers, providing nuanced, free-form medical reasoning.
- Multimodal Intelligence: By integrating a composite reward system, the model balances text accuracy with visual recognition, ensuring it “sees” and “thinks” with clinical grounding.
- A New Standard for Truth: The framework replaces outdated “word-matching” metrics with a sophisticated “LLM-as-judge” system to evaluate the actual semantic meaning of a diagnosis.
In the world of medical AI, the industry has long relied on a “safety net” of multiple-choice questions. While these benchmarks are easy to grade, they don’t reflect the messy, complex reality of a clinical environment where patients don’t present with four pre-defined options. Enter MediX-R1, an open-ended Reinforcement Learning (RL) framework designed to liberate Medical Multimodal Large Language Models (MLLMs) from these rigid formats. By focusing on “clinically grounded, free-form answers,” MediX-R1 allows AI to engage in genuine medical reasoning, providing structured, interpretable responses that mirror the way doctors actually communicate.
The Composite Reward: Teaching AI to Think
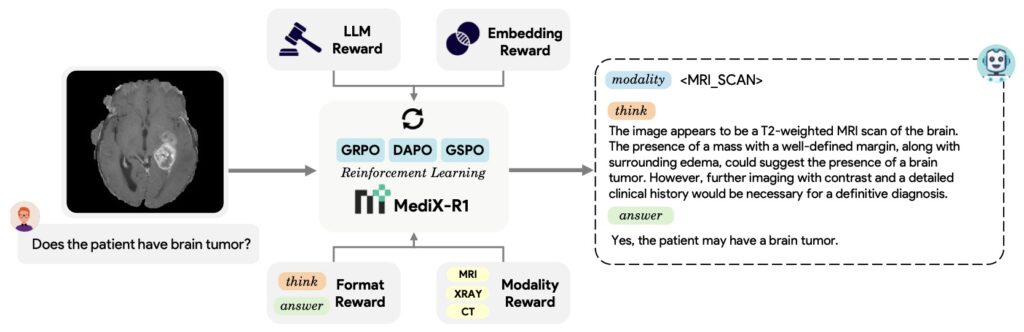
The secret sauce of MediX-R1 lies in its Group Based RL and a unique composite reward system. Traditional AI training often relies on simple string-overlap—checking if the AI’s words exactly match a reference key. However, in medicine, a “myocardial infarction” and a “heart attack” are the same thing, even if the words differ. MediX-R1 solves this using a multi-signal design:
- LLM-based Accuracy: A strict judge that decides if the answer is fundamentally correct.
- Medical Embedding Rewards: A system that recognizes terminology variants and paraphrasing.
- Format & Modality Rewards: Internal “checks” that ensure the AI provides clear reasoning and correctly identifies the medical imagery (like X-rays or MRIs) it is analyzing.
This “multi-signal” feedback provides a stable learning environment, allowing the model to achieve excellent results using only about 51,000 instruction examples—a remarkably efficient feat in the world of big data.
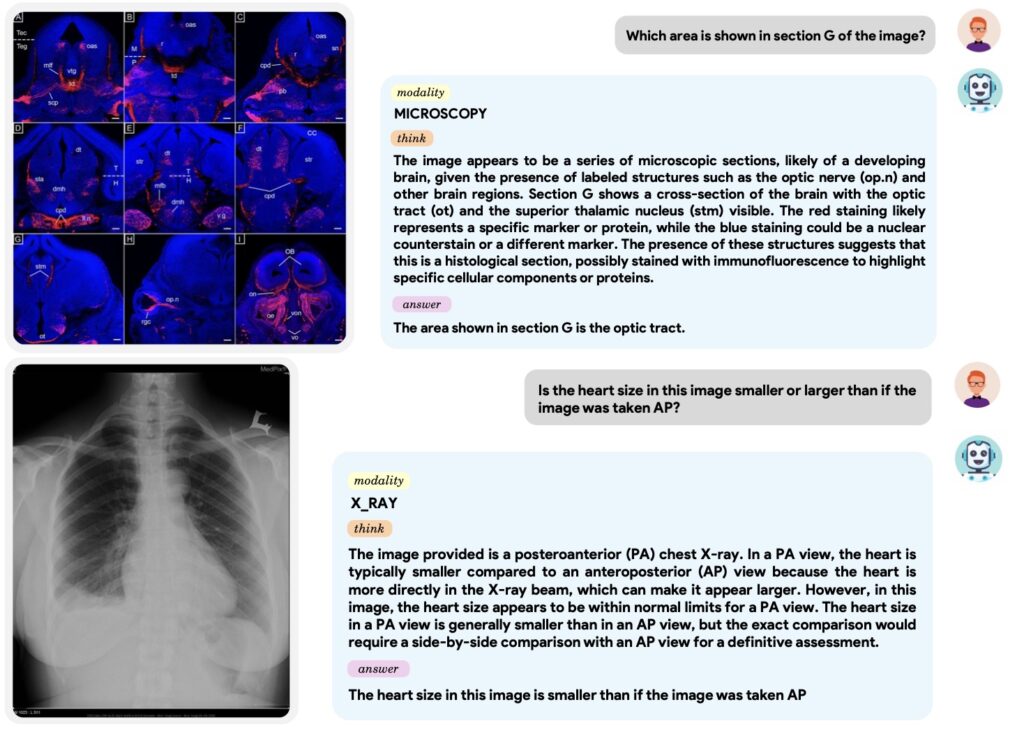
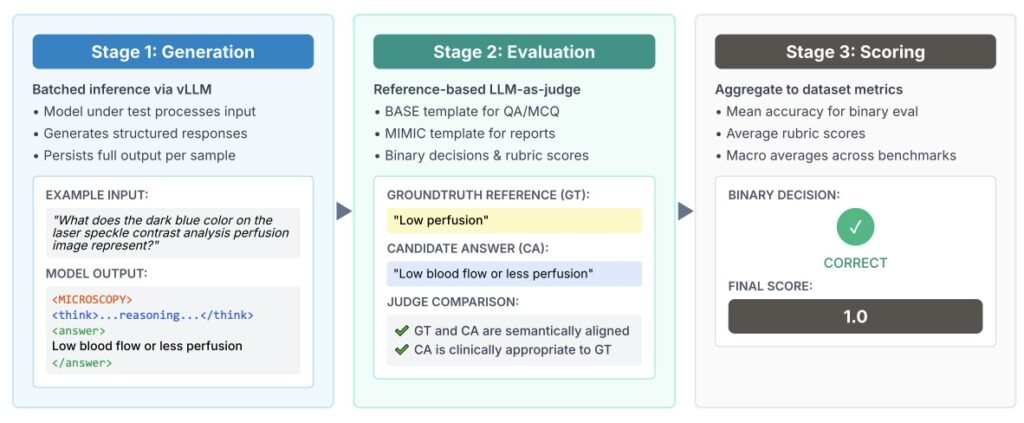
Measuring Progress with “LLM-as-Judge”
Evaluating a free-form answer is notoriously difficult. To solve this, the MediX-R1 team proposed a unified evaluation framework that uses a Reference-based LLM-as-judge. Instead of looking for specific keywords, this evaluator assesses semantic correctness, reasoning depth, and contextual alignment. This shift reduces the reliance on “brittle” metrics and allows for more realistic benchmarking of clinical reports and complex question-answering tasks. It’s not just about getting the answer right; it’s about the AI showing its work through structured reasoning blocks.
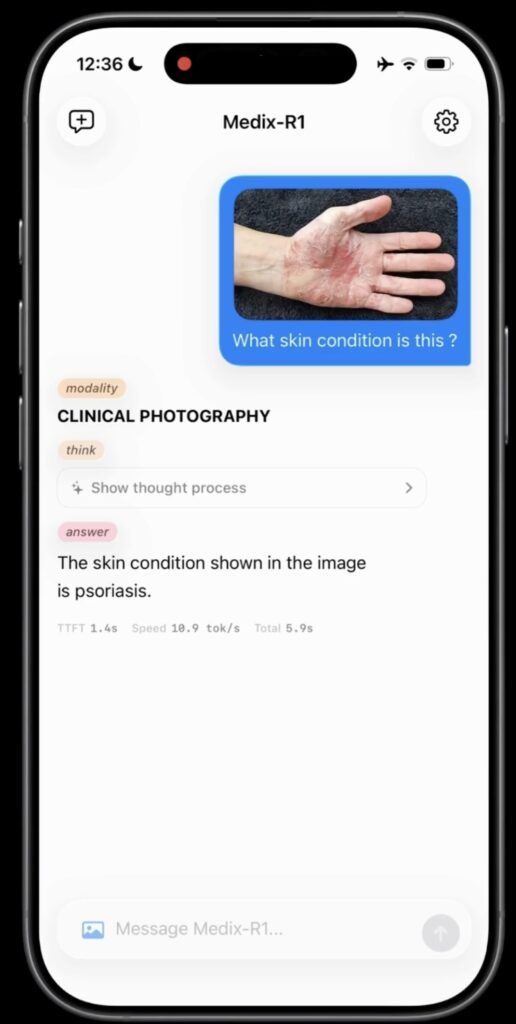
Ethical Horizons and the Road Ahead
Despite its technical prowess, the creators of MediX-R1 are candid about the risks. As a research prototype, it is not ready for the ER just yet. Issues like “hallucinations” (where the AI confidently states a falsehood) and potential demographic biases in the training data remain significant hurdles. The researchers emphasize that this tool is currently an aid for education and research, not a replacement for human clinicians. To foster a culture of transparency, the team is releasing their code and datasets under a CC-BY-NC-SA 4.0 license, inviting the global community to audit, refine, and improve upon this foundation.
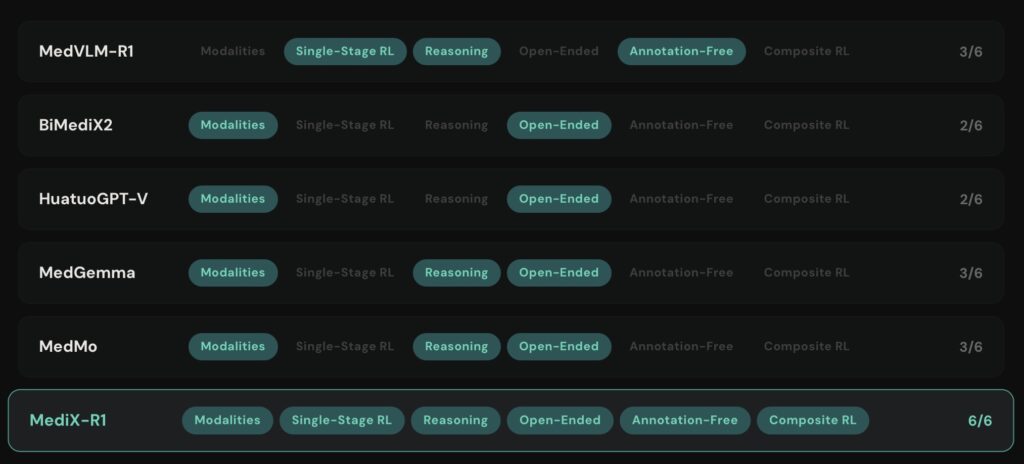
By prioritizing transparency and complex reasoning over simple memorization, MediX-R1 marks a significant step toward an AI that doesn’t just pass a test, but understands the gravity of the medical field.