The new “ProAct” framework moves beyond reactive AI by internalizing complex search logic, allowing small models to outplay giants in long-horizon tasks.
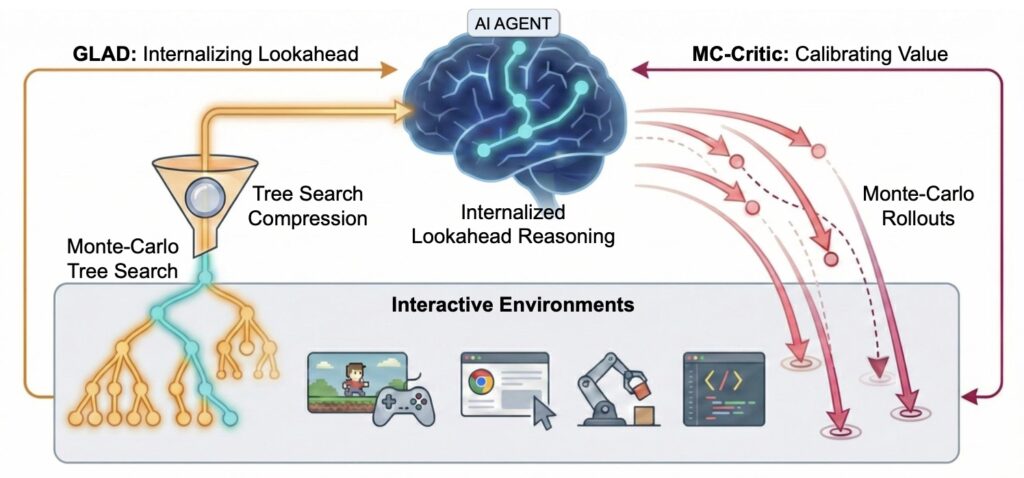
- Internalized Reasoning: Through Grounded LookAhead Distillation (GLAD), agents learn to compress massive search trees into concise, logical “foresight” chains.
- Precision Refinement: The Monte-Carlo Critic (MC-Critic) uses lightweight environment rollouts to provide stable, low-variance signals for Reinforcement Learning.
- Efficiency Meets Power: A compact 4B parameter model using ProAct now rivals massive proprietary models in complex, interactive environments.
In the world of AI agents, the difference between a “good” model and a “great” one often comes down to long-horizon planning. Standard Large Language Models (LLMs) frequently fail in interactive environments because they are fundamentally reactive. When they try to simulate the future, they suffer from compounding errors—small mistakes in predicting the next state snowball into a total loss of logic ten steps down the line. To solve this, researchers have introduced ProAct, a framework that shifts the burden of foresight from expensive, real-time searching to internalized, “agentic” intuition.

GLAD: Distilling Search into Wisdom
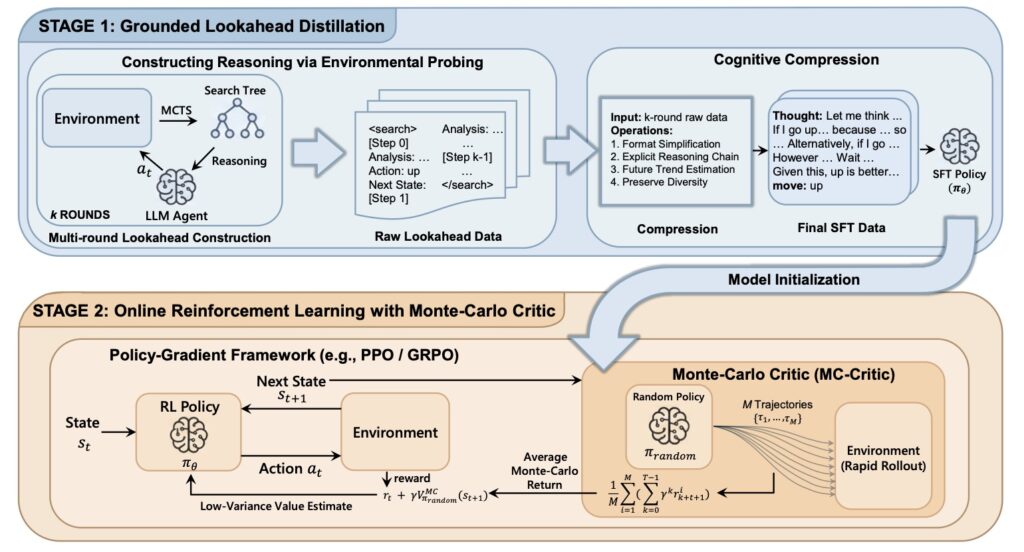
The first pillar of the ProAct framework is Grounded Look Ahead Distillation (GLAD). Traditionally, an agent might use Monte Carlo Tree Search (MCTS) at inference time to find the best move, but this is computationally heavy and slow. GLAD flips the script by using environment-based search during the training phase instead.

By taking complex, successful search trajectories and distilling them into concise, causal reasoning chains, the agent learns the logic of the search without needing to perform it every time it acts. This process allows the model to bridge the gap between “thinking fast” (intuition) and “thinking slow” (searching), effectively embedding a strategic “inner monologue” into the model’s supervised fine-tuning.
Stabilizing the Reward Signal with MC-Critic
Even with good reasoning, training an agent via Reinforcement Learning (RL) is notoriously unstable. High-variance value estimates can lead an agent to learn the wrong lessons from its successes and failures. ProAct addresses this with the Monte-Carlo Critic (MC-Critic).
Unlike traditional critics that rely on expensive model-based approximations, MC-Critic is a “plug-and-play” auxiliary estimator. It uses lightweight environment rollouts to calibrate its value estimates, providing a clear, low-variance signal. This makes algorithms like PPO and GRPO significantly more stable, ensuring that the agent’s policy optimization is grounded in the actual mechanics of the environment rather than a shaky mathematical guess.
Small Models, Big Results
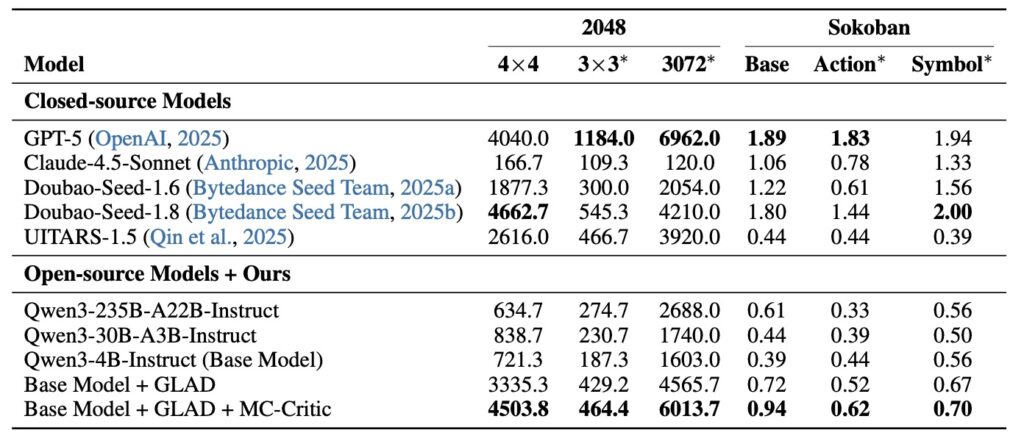
The true test of ProAct lay in its performance across diverse challenges: the stochastic unpredictability of 2048 and the deterministic logic of Sokoban. The results were striking. A relatively modest 4B parameter model trained with the ProAct framework didn’t just beat its open-source peers—it rivaled the performance of state-of-the-art closed-source models.
Perhaps most importantly, ProAct demonstrated robust generalization. The agents weren’t just memorizing paths; they were learning the underlying principles of interactive planning. This allows them to maintain high accuracy even when dropped into entirely unseen environments. By internalizing lookahead reasoning and stabilizing the learning process, ProAct marks a significant leap toward AI agents that don’t just react to the world, but actively master it.
