Bytedance’s new model redefines video creation with unprecedented spatio-temporal precision.
- Beyond Simple Editing: Vidi2 can ingest hours of raw footage and a simple prompt to autonomously construct scripts, movies, or TikToks, outperforming competitors like Gemini 3 Pro and GPT-5 in understanding context.
- Pinpoint Precision: The model introduces “spatio-temporal grounding,” allowing it to identify exact timestamps and draw bounding boxes around specific objects or actions within a chaotic scene.
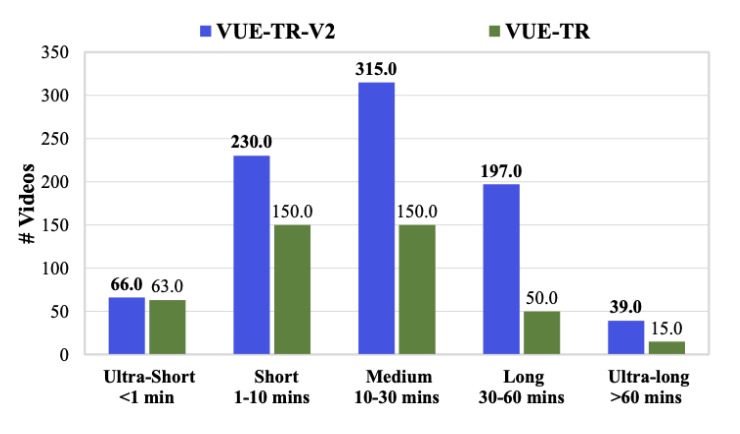
- A New Standard: Bytedance has released new benchmarks (VUE-STG and VUE-TR-V2) to prove Vidi2’s superiority in handling long-form content and complex, real-world editing scenarios.
Video has undeniably become the dominant language of the internet, driving a massive demand for tools that can democratize high-quality production. While we have seen a surge in AI tools that can generate short clips or answer basic questions about a video, the “holy grail” of automated, intelligent editing has remained elusive. Enter Vidi2, the latest release from China’s Bytedance. This isn’t just an upgrade; it is a fundamental shift in how AI perceives moving images, promising to turn hours of raw footage into polished narratives with a level of understanding that currently eclipses industry titans like Gemini 3 Pro and GPT-5.

The Evolution of Video Understanding
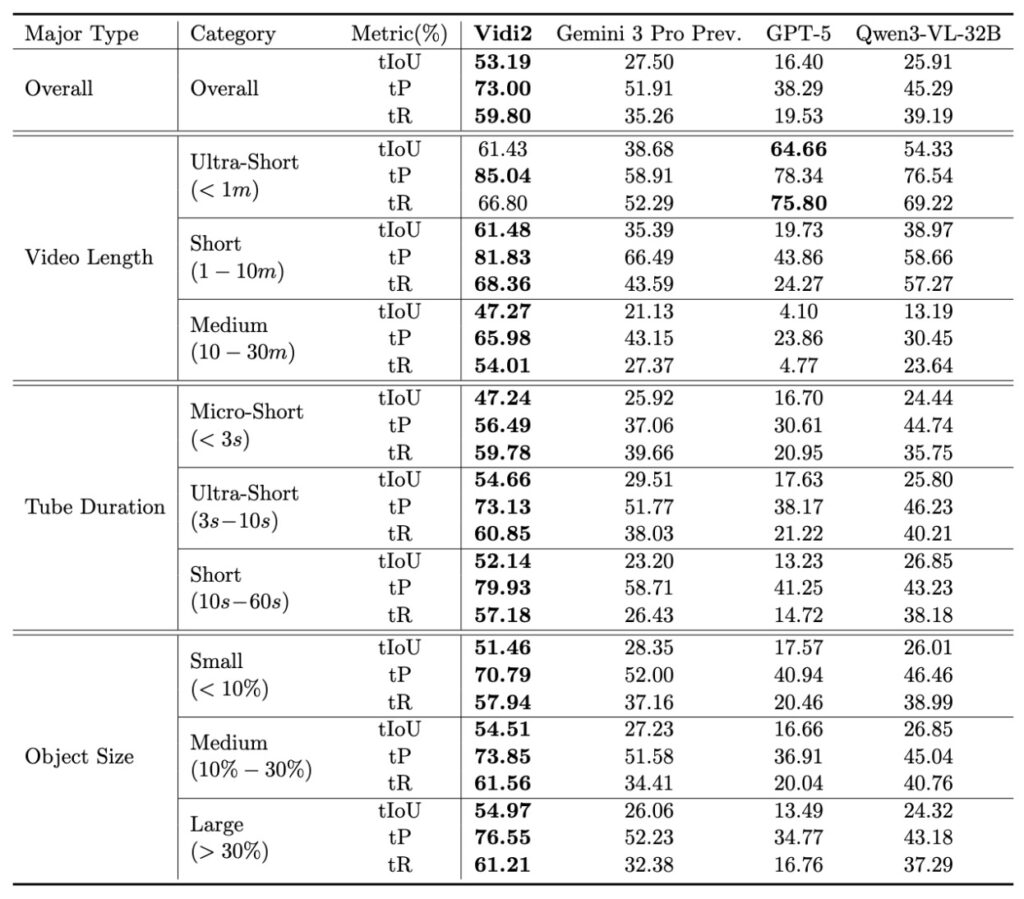
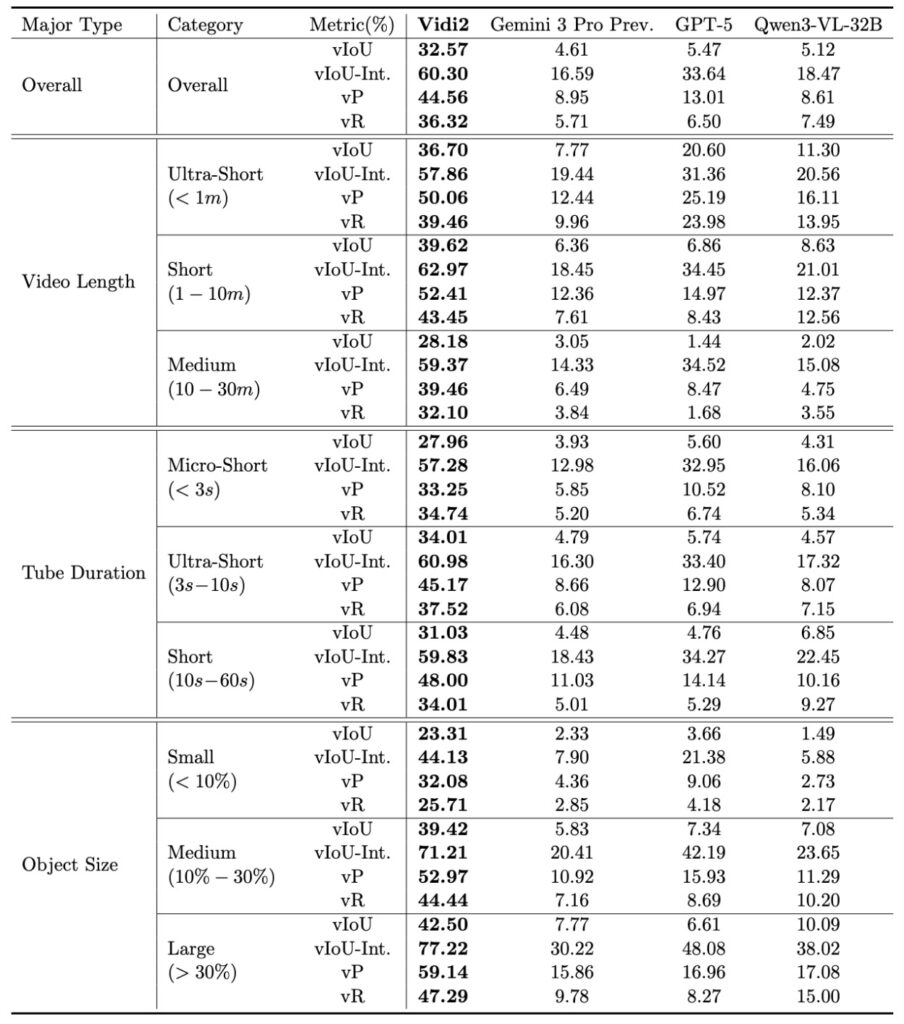
The first iteration of Vidi demonstrated strong capabilities in temporal understanding—knowing when something happened across text, visual, and audio modalities. However, Vidi2 takes a massive leap forward by introducing end-to-end spatio-temporal grounding (STG). In simple terms, most current AI models can tell you that a specific event occurred in a video. Vidi2 goes further: it can tell you exactly when it happened (timestamps) and exactly where it happened on the screen (bounding boxes), all in response to a single text query.
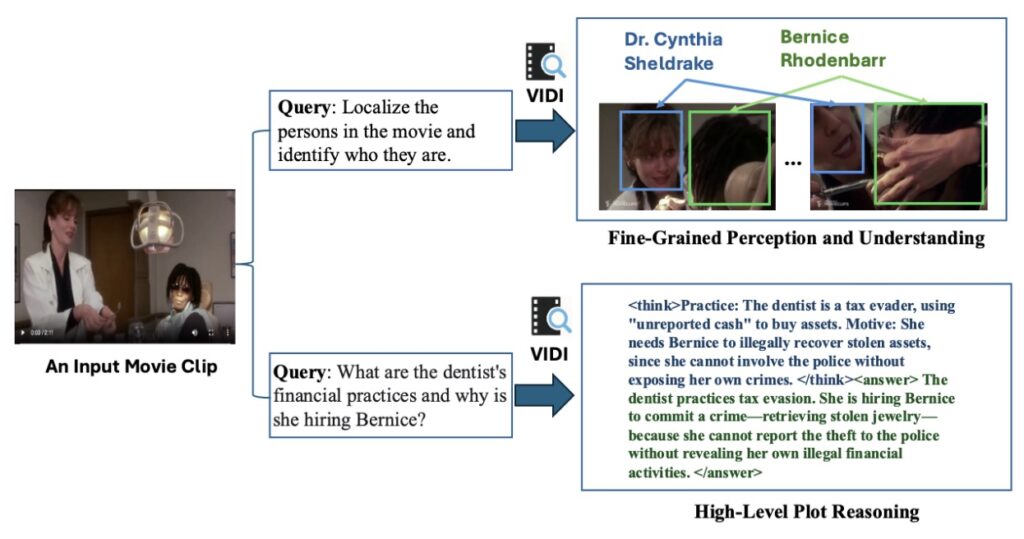
This capability is groundbreaking because it mimics the eye of a professional editor. For example, if you ask Vidi2 to find “a man standing up from a kneeling position” in a dark, crowded scene, it doesn’t just flag the clip. It accurately localizes the specific time range and distinguishes the target person from others in the frame. This level of fine-grained perception is currently absent in leading proprietary systems and academic models, making Vidi2 a uniquely powerful tool for complex workflows.
Powering Next-Gen Creativity
The practical applications of this technology are immense. Because Vidi2 understands the “plot” and character dynamics within a video, it can automate tasks that used to require hours of manual labor. The model can handle automatic multi-view switching, intelligent cropping that respects the composition of the shot, and character tracking. Imagine feeding a system three hours of vacation footage and a prompt like “make a fun 30-second TikTok summary,” and having the AI not only pick the best moments but frame them perfectly for a vertical screen.
To validate these capabilities, the team introduced a new benchmark called VUE-STG. Unlike previous tests, this benchmark evaluates models on videos ranging from 10 seconds to 30 minutes, ensuring the AI can handle long-context reasoning. It uses high-quality, manually annotated data to test how well the model handles user-style queries. In these rigorous tests, Vidi2 substantially outperformed Gemini 3 Pro (Preview) and GPT-5, proving that it isn’t just a theoretical advancement, but a practical leader in the field.
A Foundation for the Future
Vidi2 represents more than just a smart editing tool; it is a foundation model for the future of multimodal reasoning. By upgrading their previous benchmarks to include more long and ultra-long videos, Bytedance is pushing the industry toward tools that can handle the reality of modern content creation. Whether it is for professional filmmakers needing to sift through dailies or social media creators trying to edit on a mobile device, Vidi2 offers a glimpse into a future where the barrier between a creative idea and a finished video is virtually non-existent.