Google’s newest open model abandons sequential word guessing to draft, refine, and generate entire text blocks simultaneously.
- Blazing Fast Local Inference: Generates text up to 4x faster—reaching over 1,000 tokens per second—by utilizing diffusion to draft whole text blocks at once instead of relying on word-by-word generation.
- Bi-Directional Intelligence: Processes 256 tokens in parallel, enabling real-time self-correction, seamless in-line code editing, and mastery of complex, non-linear tasks like mathematical graphs and Sudoku.
- Accessible Hardware Footprint: Designed as a 26B Mixture of Experts (MoE) model that activates just 3.8B parameters, fitting comfortably within the 18GB VRAM limits of consumer graphics cards for rapid, local workflows.

The AI industry has spent years perfecting language models that act like incredibly advanced typewriters. Most traditional large language models (LLMs) operate autoregressively, predicting answers by guessing the single best word to say next, then the next, from left to right. While highly capable, this sequential process is not necessarily fast. The model must wait to finish one word before it can even think about the following one.
Today, the wait is over. Meet DiffusionGemma, an experimental open model released under an Apache 2.0 license that explores a revolutionary approach: text diffusion.
Built upon the industry-leading intelligence-per-parameter of the Gemma 4 family and cutting-edge Gemini Diffusion research, DiffusionGemma skips the sequential bottleneck entirely. Instead of predicting tokens one by one, it generates text by refining noise step by step—drafting and error-correcting entire blocks of text simultaneously. By shifting the decode bottleneck from memory bandwidth to pure compute, it upgrades model inference from a single sequential typewriter to a massive printing press that stamps out whole paragraphs in unison.
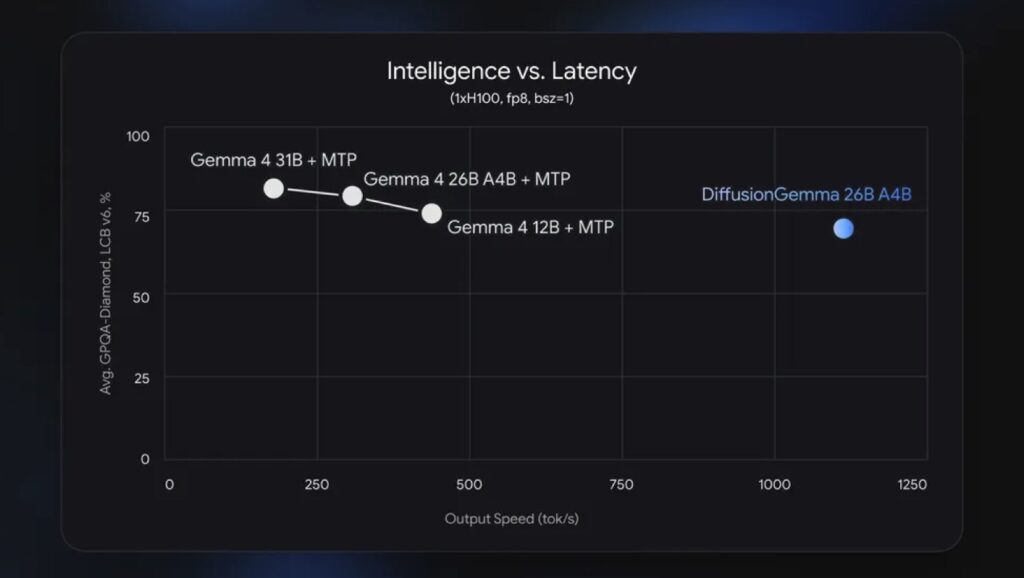
Unlocking Speed and Utilizing Hardware
While the AI research community has explored diffusion-based text generation for years, applying it efficiently to large models has remained a major challenge. DiffusionGemma changes the paradigm by shifting how models use hardware.
In a cloud environment, traditional word-by-word generation is efficient because servers batch thousands of user requests to share the hardware load. But when running a model locally, this sequential process leaves dedicated GPUs dramatically underutilized, spending most of their time simply waiting for the next “keystroke.” DiffusionGemma reverses this inefficiency. By drafting an entire 256-token paragraph simultaneously, it gives the processor a larger chunk of work at once, utilizing your hardware to its full potential.
The result is blazing fast performance. DiffusionGemma generates token output up to 4x faster on dedicated GPUs. It can achieve over 1,000 tokens per second on a single NVIDIA H100, and an impressive 700+ tokens per second on an NVIDIA GeForce RTX 5090. Despite this immense throughput, it remains accessible. As a 26B total Mixture of Experts (MoE) model that activates only 3.8B parameters during inference, a quantized DiffusionGemma fits smoothly within the 18GB VRAM limits of high-end consumer hardware.

New Patterns of Intelligence
Because it generates everything at once, DiffusionGemma unlocks entirely new patterns of model behavior. Generating 256 tokens in parallel with each forward pass allows every single token to attend to all the others simultaneously.
This bi-directional attention provides significant advantages for non-linear domains:
- Intelligent Self-Correction: The model iteratively refines its own output, evaluating the entire text block at once to catch and fix mistakes in real time.
- Smart Editing: It can effortlessly fill in blanks, format code, and complete sequences naturally.
- Complex Problem Solving: It excels at tasks that traditionally stump autoregressive models. For example, when fine-tuned by platforms like Unsloth, DiffusionGemma successfully plays Sudoku—a highly non-linear task where every current token heavily depends on future tokens.
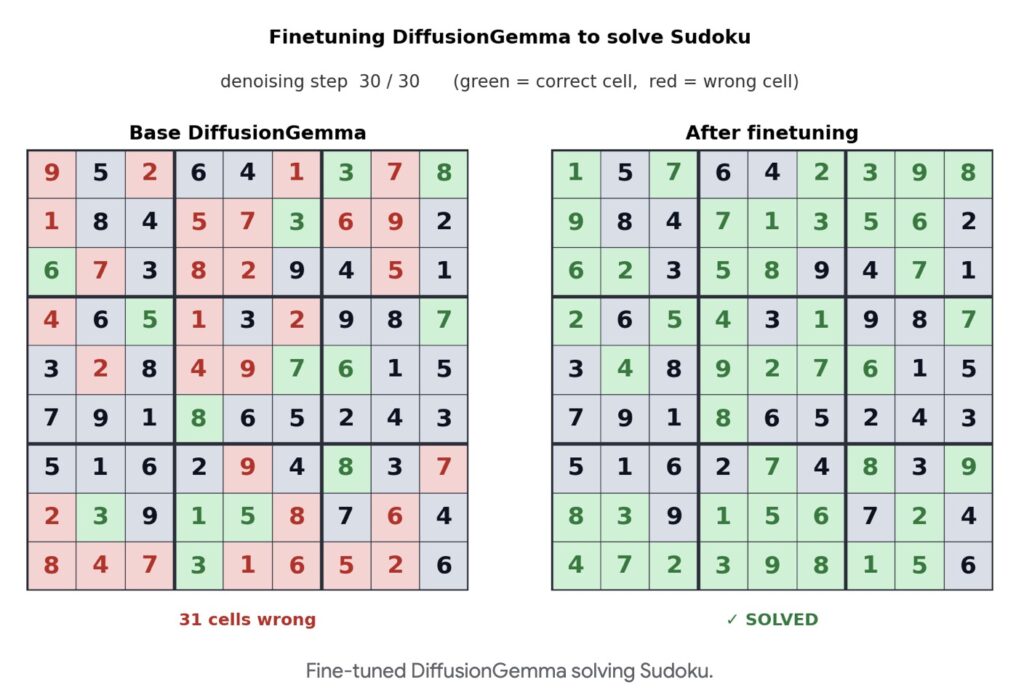
Understanding the Trade-Offs
While DiffusionGemma represents a massive leap in local generation speeds, it is an experimental model designed with specific trade-offs in mind.
Because it prioritizes speed and parallel layout generation, DiffusionGemma’s overall baseline output quality is lower than standard autoregressive models. For applications that demand maximum reasoning quality and polished production outputs, standard Gemma 4 remains the recommended choice. Furthermore, while DiffusionGemma’s parallel decoding provides a massive throughput advantage at low-to-medium batch sizes on a single local accelerator, it offers diminishing returns in high-QPS cloud serving, where traditional models can be deployed to saturate compute more cost-effectively.
DiffusionGemma is custom-built for researchers and developers pushing the boundaries of what is possible on local hardware. For those exploring speed-critical, interactive workflows, rapid iterations, and non-linear text structures, this model opens an exciting new frontier. It proves that sometimes, the fastest way to write the future is to look at the whole picture all at once.