DeepSeek-OCR’s Breakthrough Challenges the Text-Only Status Quo in AI
- Efficient Compression Through Vision: DeepSeek-OCR uses optical 2D mapping to squeeze long text into visual tokens, achieving up to 97% accuracy at a 10× compression ratio, making LLMs faster and more memory-efficient without losing key details.
- Rethinking Inputs for LLMs: By treating all data as images—even pure text rendered visually—this approach promises richer, more general information streams, bidirectional processing, and the elimination of clunky tokenizers that drag down modern AI.
- A Foundation for Future AI Memory: Beyond OCR, DeepSeek-OCR hints at a paradigm where compressed visual tokens enable LLMs to “remember” vast contexts, outperforming traditional methods and opening doors to multimodal intelligence.
In the ever-evolving world of artificial intelligence, a quiet revolution is brewing in the realm of how machines process language. DeepSeek AI’s latest innovation, DeepSeek-OCR, isn’t just another optical character recognition (OCR) tool—it’s a bold challenge to the foundational assumptions of large language models (LLMs). At its core, this open-source system leverages visual encoding to compress lengthy text passages, suggesting that pixels might be a superior input format to the text tokens that have dominated AI for years. For those of us with a foot in computer vision, this feels like a homecoming: why wrestle with the inefficiencies of text when images can capture nuance, layout, and context in a single, streamlined feed?
DeepSeek-OCR emerges from a simple yet profound insight: traditional tokenization—the process of breaking text into discrete units for LLMs—is wasteful and outdated. Tokenizers, those separate preprocessing steps, inherit the messiness of Unicode, byte encodings, and historical baggage, turning visually identical characters into wildly different internal representations. A smiling emoji? It becomes an abstract token, stripped of its pixel-perfect expressiveness and the visual transfer learning that could make AI more intuitive. Security risks lurk too, from jailbreak vulnerabilities tied to continuation bytes to the sheer inefficiency of handling bold, colored, or formatted text. DeepSeek-OCR flips this script by rendering text as images, using a “new paradigm for context compression” that maps information into 2D visual space. This isn’t merely about reading scanned documents; it’s a gateway to reimagining how LLMs ingest the world.

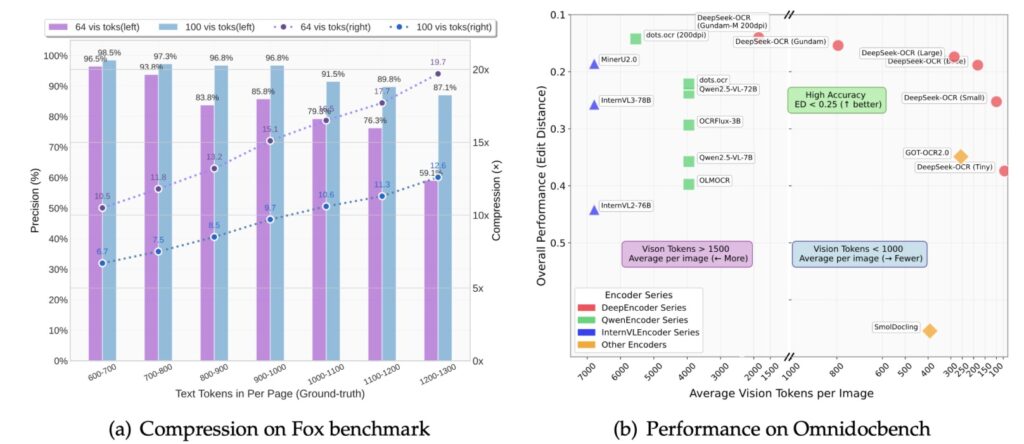
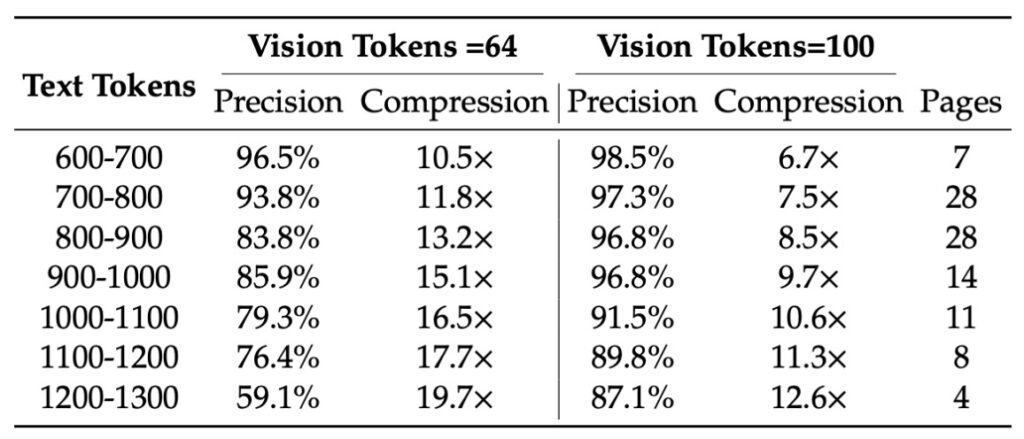
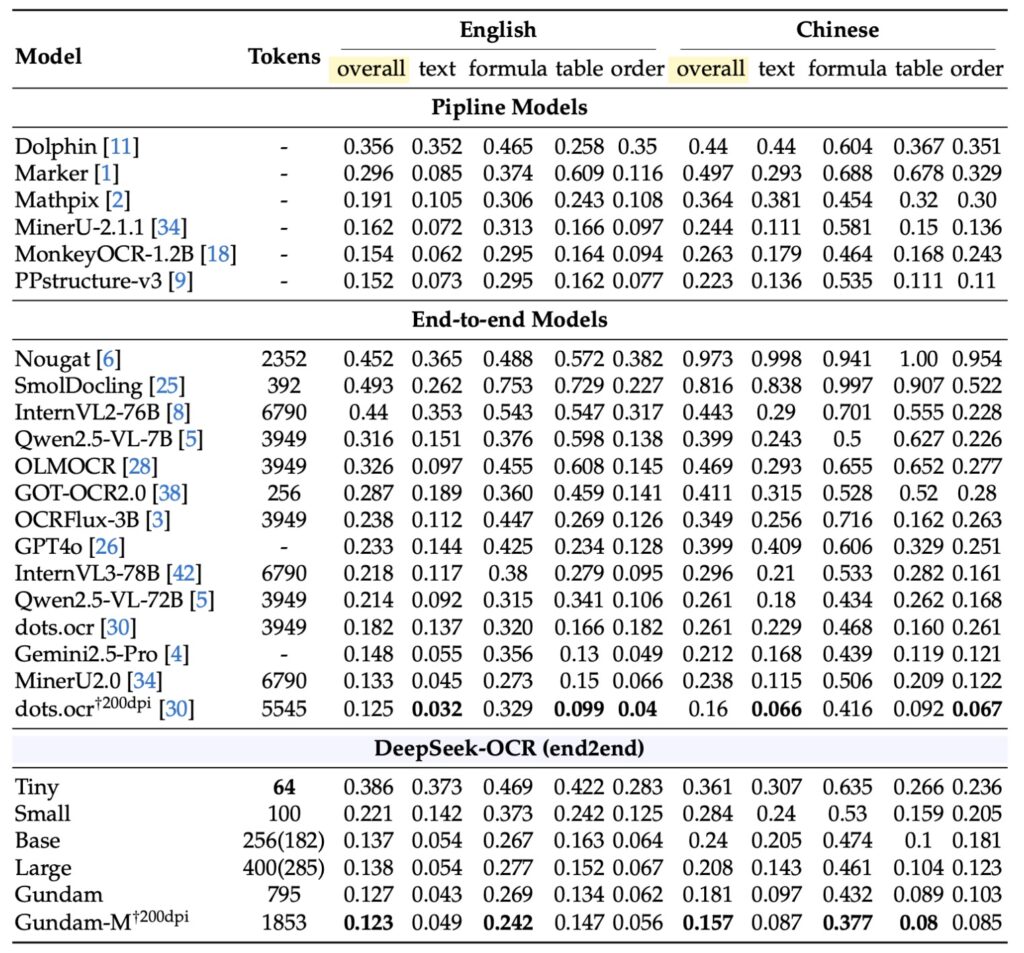
The system’s architecture is a masterclass in efficiency. At its heart lies the DeepEncoder, a visual compressor that tackles high-resolution inputs without the usual GPU memory headaches. By blending windowed and global attention mechanisms with a 16× convolutional compressor, it processes entire pages using under 800 vision tokens—far fewer than competitors like GOT-OCR 2.0 or MinerU 2.0, which it outperforms in precision. Imagine condensing ten text tokens into one visual token while retaining 97% OCR accuracy; even at a aggressive 20× ratio, it holds onto about 60% of meaningful content. This compression isn’t lossy in the way you’d fear—charts, formulas, and multilingual documents emerge crisp and interpretable, rivaling full-scale OCR suites but with a fraction of the computational toll.
Powering the output is the DeepSeek3B-MoE-A570M decoder, a mixture-of-experts (MoE) design that specializes in OCR subtasks without sacrificing speed. MoE allows the model to route queries to expert subnetworks, ensuring precise handling of diverse elements like bolded headings or embedded images. From a broader perspective, this setup underscores a key advantage of visual inputs: bidirectional attention. Unlike the autoregressive, left-to-right scanning of text-based LLMs, vision models can attend to the entire “image” at once, unlocking more powerful reasoning over layouts and relationships that text alone obscures. It’s a game-changer for tasks beyond pure OCR—think document analysis, where spatial cues like margins or diagrams add layers of meaning that tokenizers flatten.
But the real intrigue lies in DeepSeek-OCR’s implications for LLMs at large. Why stop at text-to-vision conversion? The paper posits that all inputs to LLMs could—and perhaps should—be images. Pure text? Render it first, then feed the pixels. This shift promises more information compression, shrinking context windows and boosting efficiency for long-form reasoning. It also enriches the data stream: not just words, but their visual styling—colors, fonts, emphasis—that convey intent and emotion. And let’s not forget the tokenizer’s demise. By bypassing this “ugly, separate” stage, we eliminate its quirks: no more encoding pitfalls, no more visual symbols reduced to cryptic IDs. Emojis, diagrams, even handwritten notes become native, leveraging computer vision’s strengths in pattern recognition and transfer learning from vast image datasets.
Consider the asymmetry here—OCR is a one-way street from vision to text, but the reverse feels clunky. User messages might arrive as images (a screenshot, a scanned report), processed into text for the assistant’s response. Outputting pixels directly? That’s trickier, raising questions about realism and utility. Do we want LLMs generating images on the fly, or sticking to text for clarity? DeepSeek-OCR sidesteps this by focusing on input transformation, but it sparks side quests: envision an “image-input-only” chatbot, where every query is visual, and responses blend text with generated visuals. For a vision enthusiast moonlighting in natural language, this is tantalizing—pixels as the universal language, unburdened by text’s limitations.


DeepSeek-OCR positions itself as more than a tool; it’s a blueprint for next-generation AI memory. By storing long contexts as compressed vision tokens, LLMs could “remember” histories without token bloat, enabling deeper, more scalable intelligence. In a field racing toward multimodal models, this work reminds us that text was always a proxy. Pixels, with their density and flexibility, might be the true path forward—more general, more efficient, and far more human-like in how they capture the world’s complexity. As data collection refines these systems (even if they’re a notch below top performers like Dots in raw OCR), the bigger picture emerges: AI’s future isn’t in words alone, but in the vivid, compressible canvas of vision.