Standardizing the “LLM-Wiki Pattern” to rescue enterprise knowledge from fragmented silos and empower agentic AI.
- Context is the bottleneck: Modern AI systems are heavily limited by fragmented enterprise data locked inside isolated metadata catalogs, scattered code comments, and human minds.
- A universal standard: The Open Knowledge Format (OKF) is a new, vendor-neutral specification utilizing plain markdown and YAML frontmatter to create portable, interoperable knowledge graphs.
- Ready for action: OKF launches with reference implementations—including a BigQuery enrichment agent and static visualizer—and is now natively supported by Google Cloud’s Knowledge Catalog.
Artificial intelligence is only as smart as the context we provide it. As organizations rush to build more advanced, agentic AI systems, a glaring bottleneck has emerged: foundational models lack the accurate metadata and deep context required to be truly useful.
While today’s AI can brilliantly summarize documents or generate boilerplate code, asking it a business-specific question—like “How do we compute weekly active users from our event stream?”—often results in hallucinations. The answer exists, but it is locked inside fragmented data catalogs, isolated wikis, scattered docstrings, or exclusively in the minds of senior engineers. Every time a development team builds a new AI agent, they are forced to solve this exact same context-assembly problem from scratch.
To bridge this gap, the tech community has introduced the Open Knowledge Format (OKF). This vendor-neutral, open specification formalizes the rapidly emerging “LLM-wiki pattern” into a portable, interoperable standard, fundamentally changing how AI systems consume enterprise knowledge.
The Shift to “Knowledge as a Living Wiki”
Developer teams are evolving. Instead of forcing foundation models to repeatedly search the same disjointed documents for facts, developers are beginning to give their AI agents shared markdown libraries that grow more useful over time.
“LLMs don’t get bored, don’t forget to update a cross-reference, and can touch 15 files in one pass.” — Andrej Karpathy, AI Researcher
The bookkeeping drudgery that typically causes humans to abandon internal wikis is exactly what Large Language Models excel at. We have seen this pattern organically emerge under various names: Obsidian vaults wired to coding agents, AGENTS.md convention files, or repo directories full of index.md artifacts.
While these bespoke wikis are powerful, they are completely isolated. There has been no agreed-upon standard for what fields a document should carry or what filenames mean. OKF solves this by providing a format, not another proprietary service.
Radical Simplicity
At its core, an OKF bundle is incredibly simple. It eschews complex compression schemes, proprietary runtimes, and mandatory SDKs. The format is designed to be just as readable for a human developer as it is parseable for an AI agent.
A standard bundle of OKF documents consists of:
- Just Markdown: Readable in any text editor, renderable natively on GitHub, and indexable by any search tool.
- Just Files: Easily shippable as a tarball, hostable in any git repository, and mountable on any standard filesystem.
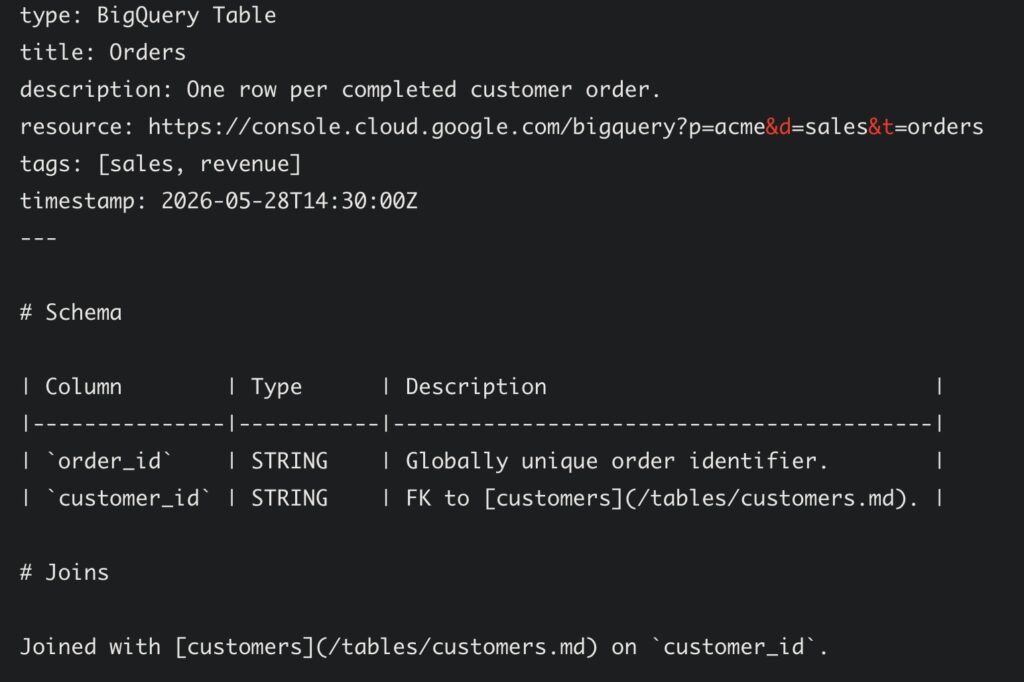
- Just YAML Frontmatter: Utilizing a minimal set of structured fields that need to be queryable (
type,title,description,resource,tags, andtimestamp).
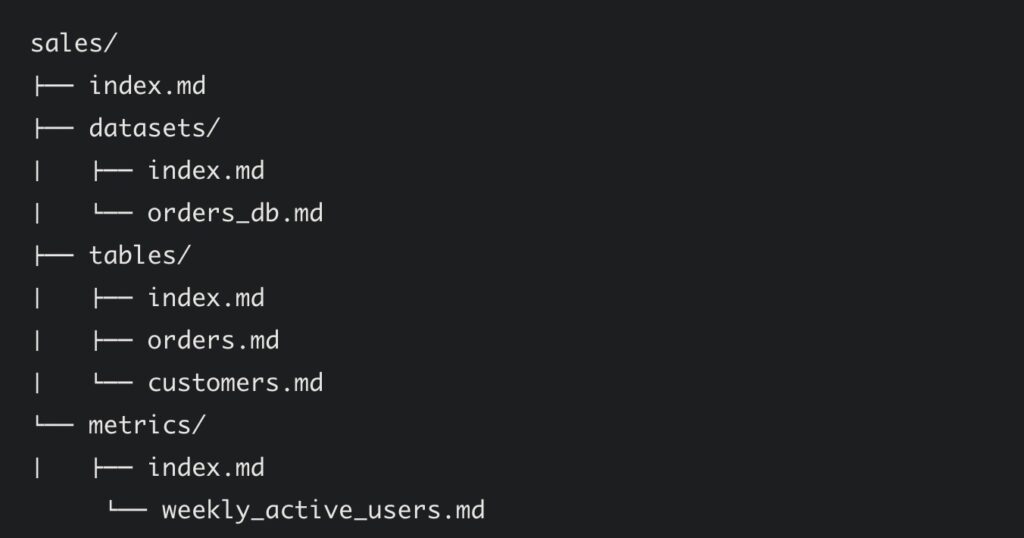
Within OKF, every concept—whether it is a database table, a business metric, an incident runbook, or an API deprecation notice—is represented by a single file. File paths act as the concept’s identity, and standard markdown links turn the directory into a rich, navigable graph of relationships. Bundles can also optionally include index.md files for progressive disclosure and log.md files to maintain a chronological history of changes.
Hitting the Ground Running
To prove the efficacy of OKF and lower the barrier to entry, a suite of reference implementations has been published alongside the specification:
- BigQuery Enrichment Agent: A producer agent that walks a BigQuery dataset, drafts an OKF concept document for every table, and runs a secondary LLM pass to crawl authoritative documentation—enriching the concepts with schemas, citations, and join paths.
- Static HTML Visualizer: A consumer tool that turns any OKF bundle into an interactive, self-contained graph view directly in the browser, ensuring no data ever leaves the page.
- Sample Bundles: Ready-to-browse living examples, including datasets for GA4 e-commerce, Stack Overflow, and Bitcoin public data.
Furthermore, enterprise adoption is already beginning. Google Cloud’s Knowledge Catalog has been updated to natively ingest the Open Knowledge Format and serve it directly to AI agents.
Building the Lingua Franca of AI Context
OKF v0.1 is just the starting point. Because it is published entirely in the open on GitHub, the specification is explicitly designed for backward-compatible growth.
The true value of a knowledge format comes from how many parties speak it, not who owns it. Whether you are building a knowledge catalog, an automated enrichment pipeline, or a dedicated AI wiki, OKF is built to be the universal lingua franca. By moving enterprise context out of locked silos and into an interoperable standard, we can finally stop rebuilding context from scratch and start building smarter, more reliable AI.