Revolutionizing Human Video Generation for Virtual Reality and Animation
- Innovative 4D Transformer Architecture: Efficient modeling of spatio-temporal correlations across viewpoints and time.
- Precise Conditioning Mechanism: Utilizes human identity, camera parameters, and temporal signals for accurate video generation.
- Multi-dimensional Training Strategy: Trained on a diverse dataset including images, videos, multi-view data, and 4D scans.
In the rapidly evolving world of multimedia technology, the ability to generate high-quality human videos from a single image is a significant breakthrough. Enter Human4DiT, a novel framework designed to create spatio-temporally coherent human videos from arbitrary viewpoints. This innovative approach leverages a unique combination of U-Nets and diffusion transformers to deliver unprecedented accuracy and realism in human video generation.

Innovative 4D Transformer Architecture
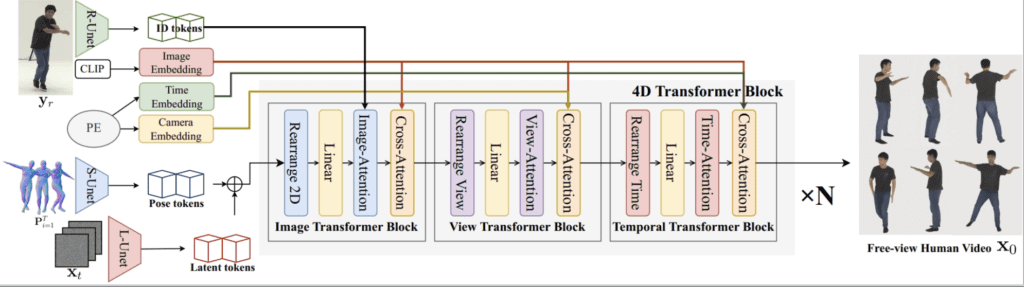
Human4DiT introduces a groundbreaking 4D transformer architecture that excels in modeling the complex correlations between various dimensions—viewpoints, time, and spatial aspects. Unlike traditional methods, which often struggle with dynamic motions and changing viewpoints, this architecture efficiently factorizes attention across all four dimensions. This allows for a more holistic understanding and generation of human motion, resulting in videos that are both realistic and coherent.
The core of this architecture is its ability to manage and integrate multiple forms of data. By employing a cascaded structure, the 4D transformer can capture and replicate the intricate details of human motion, ensuring that the generated videos maintain a high degree of spatial and temporal coherence.
Precise Conditioning Mechanism
To achieve precise and accurate video generation, Human4DiT incorporates a robust conditioning mechanism. This involves injecting key parameters such as human identity, camera settings, and temporal signals directly into the transformers. This method ensures that each video frame is not only consistent with the preceding ones but also aligns perfectly with the intended viewpoint and motion dynamics.
This precise conditioning is critical for applications requiring high levels of detail and realism, such as virtual reality, animation, and gaming. By ensuring that every aspect of the video is meticulously controlled and coherent, Human4DiT paves the way for more immersive and engaging multimedia experiences.
Multi-dimensional Training Strategy
The training of Human4DiT is as innovative as its architecture. The model is trained on a diverse and comprehensive dataset that spans images, videos, multi-view data, and 4D scans. This multi-dimensional training approach equips the model with a broad and versatile understanding of human motion and appearance across different contexts and perspectives.
This diverse training enables Human4DiT to generate videos that are not only visually stunning but also contextually accurate. Whether it’s a complex dance routine or a simple gesture, the model can faithfully recreate human motion from any viewpoint, making it an invaluable tool for various multimedia applications.
Human4DiT represents a significant leap forward in the field of human video generation. Its innovative use of a 4D transformer architecture, precise conditioning mechanism, and multi-dimensional training strategy set it apart from existing methods. By providing a scalable and efficient solution for generating spatio-temporally coherent human videos, Human4DiT has the potential to revolutionize various multimedia applications, from virtual reality and animation to gaming and beyond. As research continues to refine and expand this technology, the possibilities for creating realistic and immersive human motion videos will only grow.