MoE Models with Gradient-Informed Techniques to Boost Performance and Scalability
- Advancements in Mixture-of-Experts (MoE) Models: MoE models leverage sparse computation to improve scalability, activating only a small subset of expert modules for each task, yet they face challenges in training due to non-differentiable expert routing.
- Introducing GRIN: The new GRadient-INformed MoE training framework enhances traditional training methods by integrating sparse gradient estimation and model parallelism, enabling effective backpropagation even in sparse settings.
- Remarkable Performance Gains: GRIN has demonstrated superior performance in autoregressive language modeling, outpacing dense models and achieving high scores on various benchmarks, highlighting its potential to transform the landscape of deep learning.
In the evolving landscape of artificial intelligence, Mixture-of-Experts (MoE) models have emerged as a powerful tool for improving scalability in deep learning. By selectively activating a subset of expert modules, these models achieve significant efficiency gains compared to traditional dense architectures. However, training MoE models presents unique challenges, primarily due to the non-differentiable nature of the expert routing process, which complicates the application of standard backpropagation techniques. To address these challenges, researchers have introduced GRIN (GRadient-INformed MoE), a groundbreaking training framework designed to optimize MoE model performance.
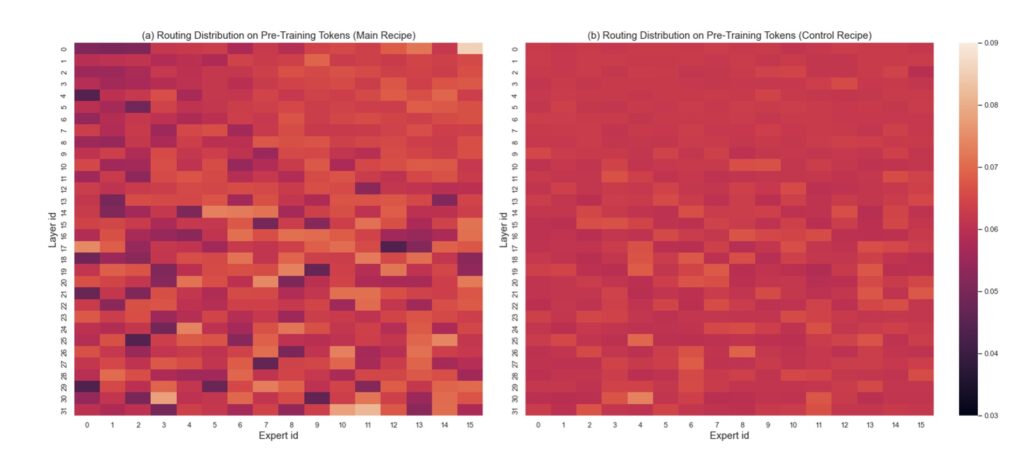
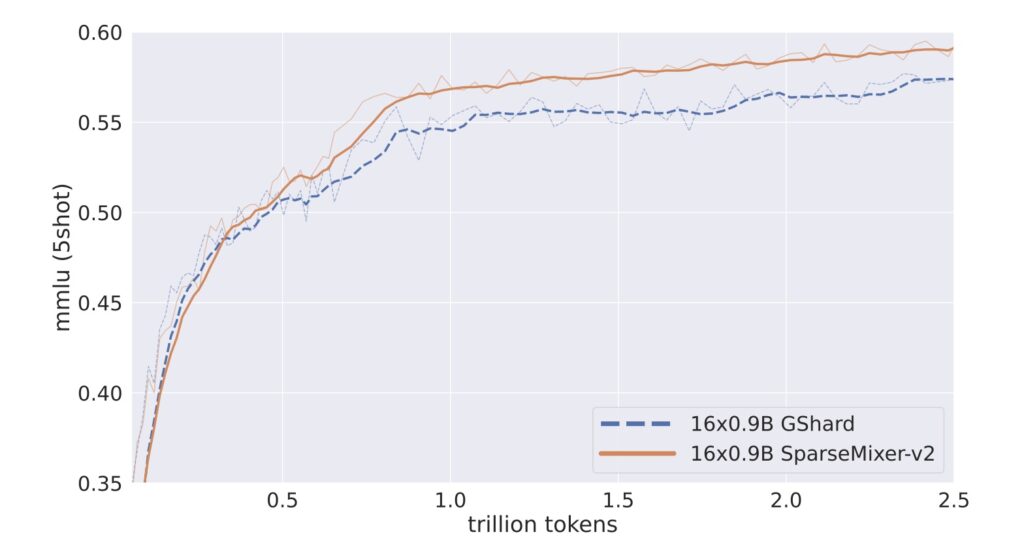
GRIN incorporates sparse gradient estimation to facilitate effective expert routing while maintaining compatibility with gradient-based optimization. By leveraging this approach, the framework allows for accurate backpropagation even in the presence of sparse activation, paving the way for enhanced training practices. The model parallelism configuration inherent in GRIN also addresses issues related to token dropping, which can hinder performance during training. This innovative combination of techniques positions GRIN as a game-changer in the realm of MoE training.
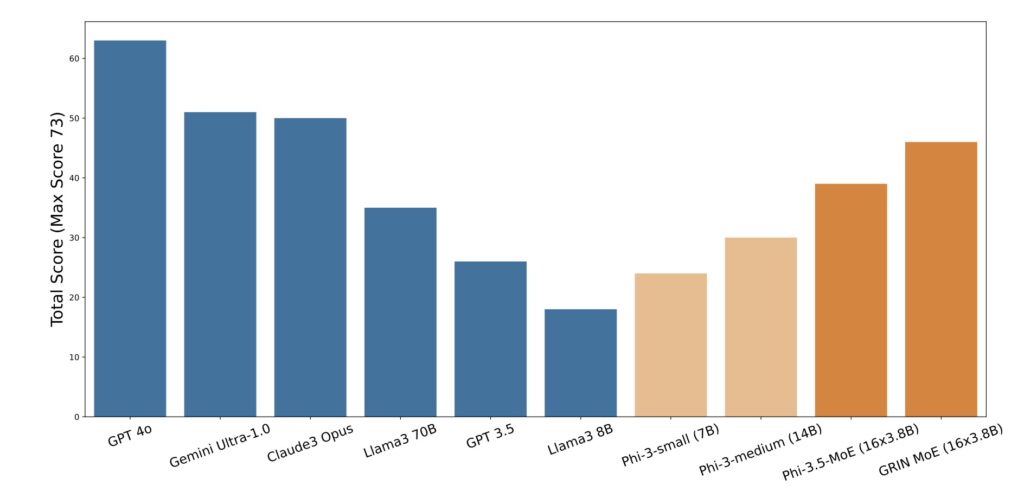
One of the most impressive applications of GRIN is its implementation in autoregressive language modeling. The development of a top-2 16×3.8B MoE model showcases GRIN’s efficacy, as it activates only 6.6 billion parameters yet outperforms a 7B dense model. Remarkably, it matches the performance of a 14B dense model trained on the same dataset. These results underline GRIN’s potential to significantly improve the scalability and efficiency of MoE models, which are critical in the current landscape of deep learning.
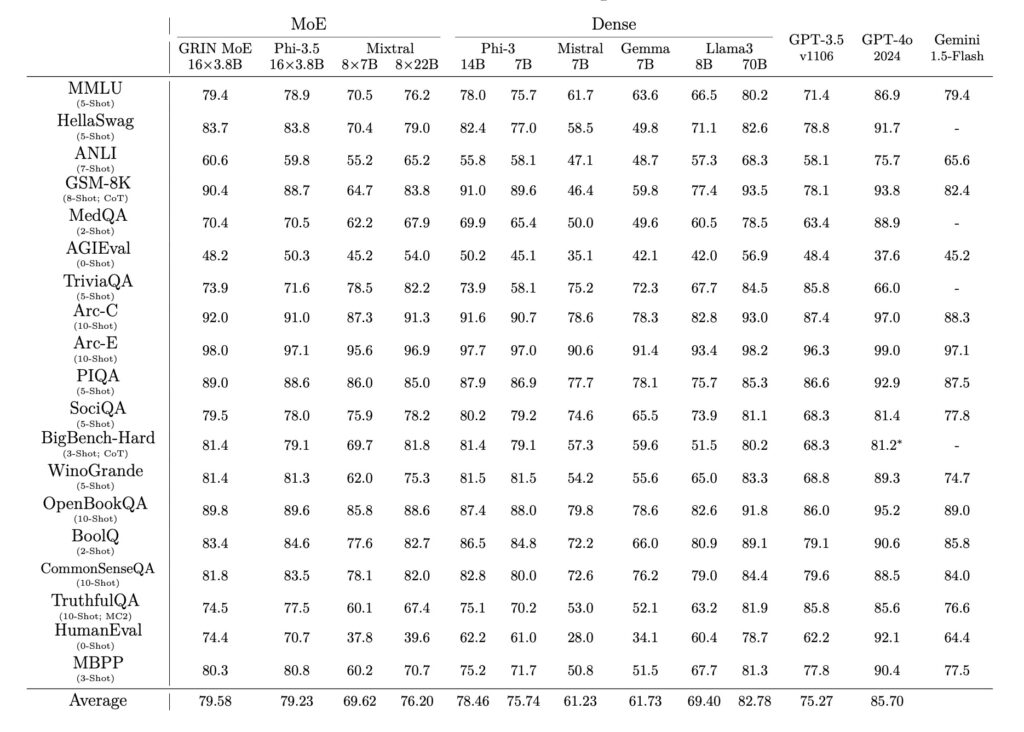
Extensive evaluations across various tasks demonstrate GRIN’s superior performance. The model achieved impressive scores on benchmarks such as 79.4 on MMLU, 83.7 on HellaSwag, 74.4 on HumanEval, and 58.9 on MATH. These achievements highlight not only the effectiveness of GRIN but also the importance of scaling up models to meet the demands of complex AI applications. The findings reinforce the notion that leveraging MoE architectures, coupled with advanced training techniques, can lead to breakthroughs in model capabilities.
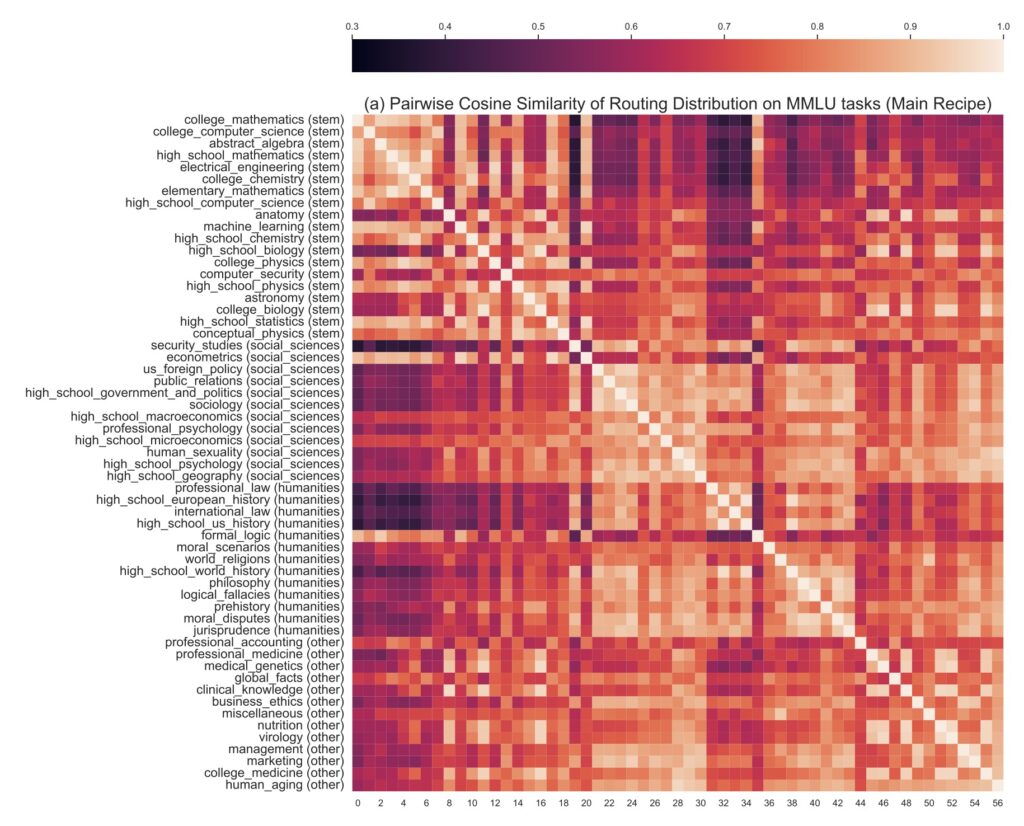
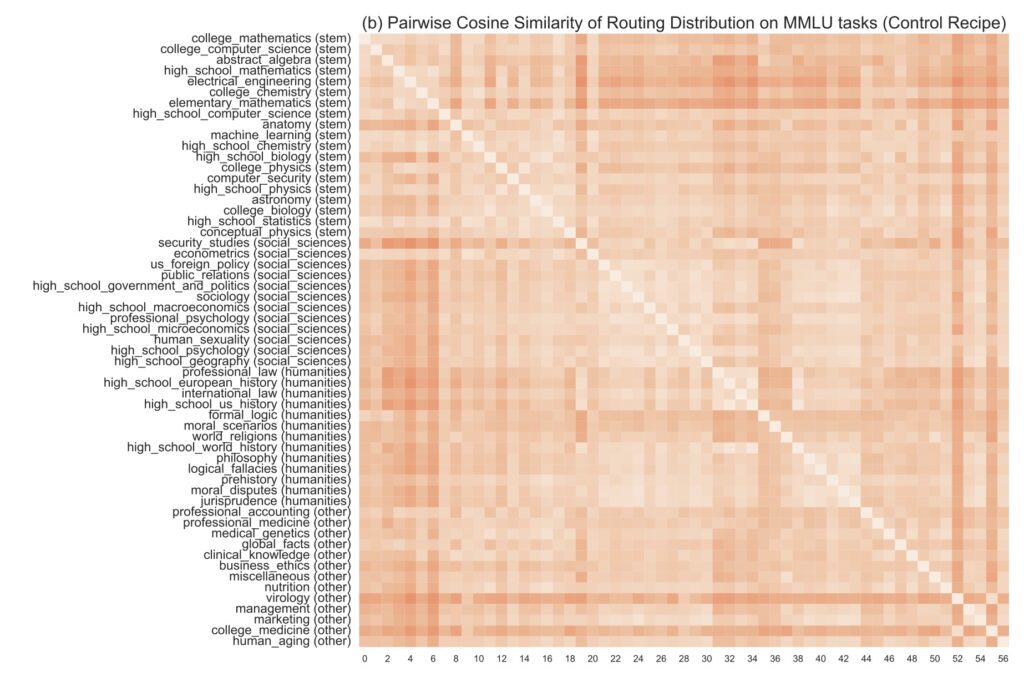
Despite the significant advancements brought by GRIN, challenges remain in the training and inference of MoE models. The reliance on softmax functions to approximate argmax operations presents new complexities, particularly when attempting to implement top-k sampling. Future research will focus on addressing these issues while enhancing sparsity and developing efficient computation methods to further advance the state-of-the-art in MoE modeling.
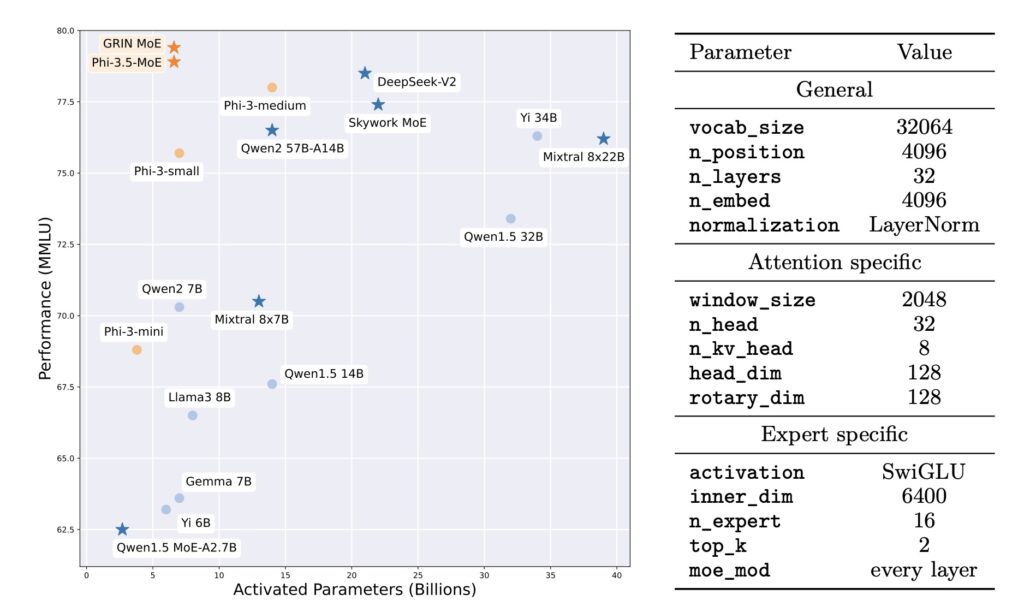
GRIN represents a major step forward in optimizing Mixture-of-Experts models for deep learning. By overcoming the traditional limitations of sparse computation through innovative training techniques, GRIN paves the way for more scalable and efficient AI solutions. As researchers continue to explore and refine these methodologies, the potential for MoE models to revolutionize various applications in artificial intelligence becomes increasingly clear.